11.2 即时编译器 11.2.2 编译对象与触发条件
11.2.2 编译对象与触发条件
在本章概述中提到了在运行过程中会被即时编译器编译的目标是“热点代码”,这里所指的热点代码主要有两类,包括:
- 被多次调用的方法。
- 被多次执行的循环体。
前者很好理解,一个方法被调用得多了,方法体内代码执行的次数自然就多,它成为“热点代码”是理所当然的。而后者则是为了解决当一个方法只被调用过一次或少量的几次,但是方法体内部存在循环次数较多的循环体,这样循环体的代码也被重复执行多次,因此这些代码也应该认为是“热点代码”[^1]。
对于这两种情况,编译的目标对象都是整个方法体,而不会是单独的循环体。第一种情况,由于是依靠方法调用触发的编译,那编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的即时编译方式。而对于后一种情况,尽管编译动作是由循环体所触发的,热点只是方法的一部分,但编译器依然必须以整个方法作为编译对象,只是执行入口(从方法第几条字节码指令开始执行)会稍有不同,编译时会传入执行入口点字节码序号(Byte Code Index,BCI)。这种编译方式因为编译发生在方法执行的过程中,因此被很形象地称为“栈上替换”(On Stack Replacement,OSR),即方法的栈帧还在栈上,方法就被替换了。
读者可能还会有疑问,在上面的描述里,无论是“多次执行的方法”,还是“多次执行的代码块”, 所谓“多次”只定性不定量,并不是一个具体严谨的用语,那到底多少次才算“多次”呢?还有一个问题,就是Java虚拟机是如何统计某个方法或某段代码被执行过多少次的呢?解决了这两个问题,也就解答了即时编译被触发的条件。
要知道某段代码是不是热点代码,是不是需要触发即时编译,这个行为称为“热点探测”(Hot Spot Code Detection),其实进行热点探测并不一定要知道方法具体被调用了多少次,目前主流的热点探测判定方式有两种[^2],分别是:
- 基于采样的热点探测(Sample Based Hot Spot Code Detection)。采用这种方法的虚拟机会周期性 地检查各个线程的调用栈顶,如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是“热点方 法”。基于采样的热点探测的好处是实现简单高效,还可以很容易地获取方法调用关系(将调用堆栈展 开即可),缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而 扰乱热点探测。
- 基于计数器的热点探测(Counter Based Hot Spot Code Detection)。采用这种方法的虚拟机会为 每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定的阈值就认为 它是“热点方法”。这种统计方法实现起来要麻烦一些,需要为每个方法建立并维护计数器,而且不能 直接获取到方法的调用关系。但是它的统计结果相对来说更加精确严谨。
这两种探测手段在商用Java虚拟机中都有使用到,譬如J9用过第一种采样热点探测,而在HotSpot虚拟机中使用的是第二种基于计数器的热点探测方法,为了实现热点计数,HotSpot为每个方法准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter,“回边”的意思就是指在循环边界往回跳转)。当虚拟机运行参数确定的前提下,这两个计数器都有一个明确的阈值,计数器阈值一旦溢出,就会触发即时编译。
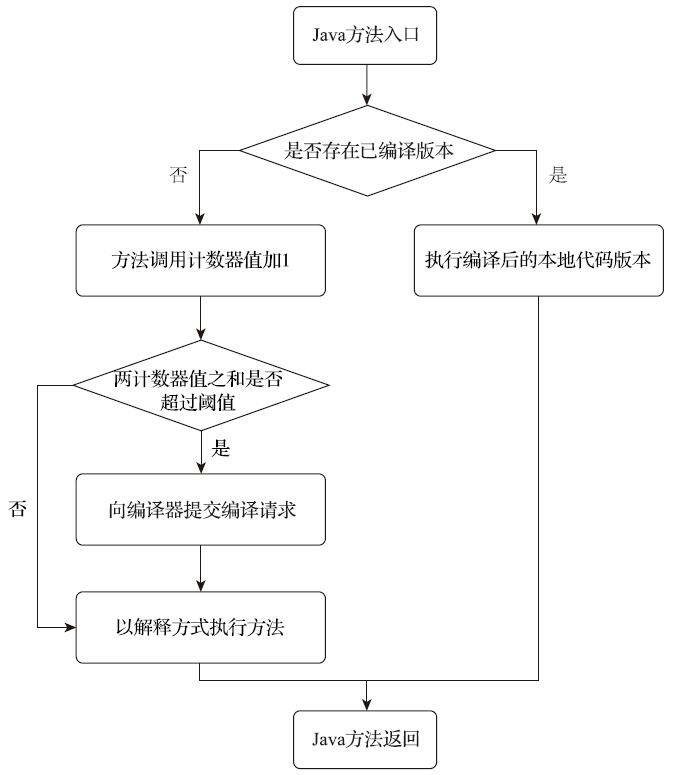
我们首先来看看方法调用计数器。顾名思义,这个计数器就是用于统计方法被调用的次数,它的默认阈值在客户端模式下是1500次,在服务端模式下是10000次,这个阈值可以通过虚拟机参数-XX: CompileThreshold来人为设定。当一个方法被调用时,虚拟机会先检查该方法是否存在被即时编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在已被编译过的版本,则将该方法的调用计数器值加一,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值。一旦已超过阈值的话,将会向即时编译器提交一个该方法的代码编译请求。
如果没有做过任何设置,执行引擎默认不会同步等待编译请求完成,而是继续进入解释器按照解释方式执行字节码,直到提交的请求被即时编译器编译完成。当编译工作完成后,这个方法的调用入口地址就会被系统自动改写成新值,下一次调用该方法时就会使用已编译的版本了,整个即时编译的交互过程如图11-3所示。
在默认设置下,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那该方法的调用计数器就会被减少一半,这个过程被称为方法调用计数器热度的衰减(Counter Decay),而这段时间就称为此方法统计的半衰周期(Counter Half Life Time), 进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数-XX:- UseCounterDecay来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样只要系统运行时间足够长,程序中绝大部分方法都会被编译成本地代码。另外还可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位是秒。
现在我们再来看看另外一个计数器——回边计数器,它的作用是统计一个方法中循环体代码执行的次数[^3],在字节码中遇到控制流向后跳转的指令就称为“回边(Back Edge)”,很显然建立回边计数器统计的目的是为了触发栈上的替换编译。
关于回边计数器的阈值,虽然HotSpot虚拟机也提供了一个类似于方法调用计数器阈值-XX: CompileThreshold的参数-XX:BackEdgeThreshold供用户设置,但是当前的HotSpot虚拟机实际上并未使用此参数,我们必须设置另外一个参数-XX:OnStackReplacePercentage来间接调整回边计数器的阈值,其计算公式有如下两种。
- 虚拟机运行在客户端模式下,回边计数器阈值计算公式为:方法调用计数器阈值(-XX: CompileThreshold)乘以OSR比率(-XX:OnStackReplacePercentage)除以100。其中-XX: OnStackReplacePercentage默认值为933,如果都取默认值,那客户端模式虚拟机的回边计数器的阈值为 13995。
- 虚拟机运行在服务端模式下,回边计数器阈值的计算公式为:方法调用计数器阈值(-XX: CompileThreshold)乘以(OSR比率(-XX:OnStackReplacePercentage)减去解释器监控比率(-XX: InterpreterProfilePercentage)的差值)除以100。其中-XX:OnStack ReplacePercentage默认值为140,- XX:InterpreterProfilePercentage默认值为33,如果都取默认值,那服务端模式虚拟机回边计数器的阈 值为10700。
当解释器遇到一条回边指令时,会先查找将要执行的代码片段是否有已经编译好的版本,如果有的话,它将会优先执行已编译的代码,否则就把回边计数器的值加一,然后判断方法调用计数器与回边计数器值之和是否超过回边计数器的阈值。当超过阈值的时候,将会提交一个栈上替换编译请求, 并且把回边计数器的值稍微降低一些,以便继续在解释器中执行循环,等待编译器输出编译结果,整个执行过程如图11-4所示。
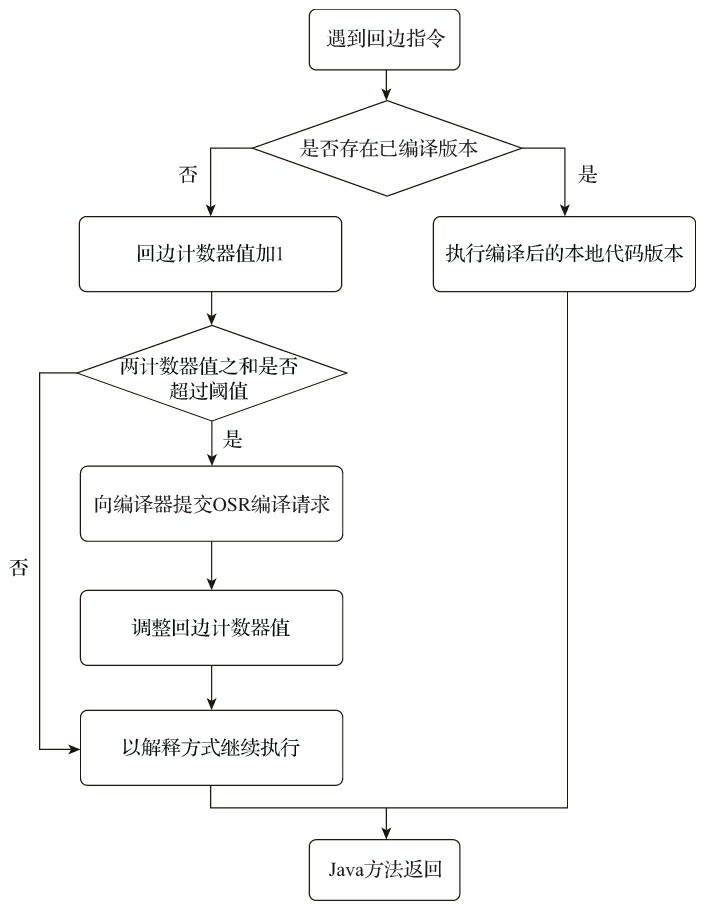
与方法计数器不同,回边计数器没有计数热度衰减的过程,因此这个计数器统计的就是该方法循环执行的绝对次数。当计数器溢出的时候,它还会把方法计数器的值也调整到溢出状态,这样下次再进入该方法的时候就会执行标准编译过程。
最后还要提醒一点,图11-2和图11-3都仅仅是描述了客户端模式虚拟机的即时编译方式,对于服务端模式虚拟机来说,执行情况会比上面描述还要复杂一些。从理论上了解过编译对象和编译触发条件后,我们还可以从HotSpot虚拟机的源码中简单观察一下这两个计数器,在MehtodOop.hpp(一个methodOop对象代表了一个Java方法)中,定义了Java方法在虚拟机中的内存布局,如下所示:
1 | // |------------------------------------------------------| |
在这段注释所描述的方法内存布局里,每一行表示占用32个比特,从中我们可以清楚看到方法调用计数器和回边计数器所在的位置和数据宽度,另外还有from_compiled_entry和from_interpreted_entry 两个方法入口所处的位置。
[^1]: 还有一个不太上台面但其实是Java虚拟机必须支持循环体触发编译的理由,是诸多跑分软件的测试 用力通常都属于第二种,如果不去支持跑分会显得成绩很不好看。
[^2]: 除这两种方式外,还有其他热点代码的探测方式,如基于“踪迹”(Trace)的热点探测在最近相当流 行,像FireFox里的TraceMonkey和Dalvik里新的即时编译器都是用了这种热点探测方式。
[^3]: 准确地说,应当是回边的次数而不是循环次数,因为并非所有的循环都是回边,如空循环实际上就 可以视为自己跳转到自己的过程,因此并不算作控制流向后跳转,也不会被回边计数器统计。