11.2 即时编译器 11.2.1 解释器与编译器
11.2 即时编译器
目前主流的两款商用Java虚拟机(HotSpot、OpenJ9)里,Java程序最初都是通过解释器 (Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁,就会把这些代码认定为“热点代码”(Hot Spot Code),为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成本地机器码,并以各种手段尽可能地进行代码优化,运行时完成这个任务的后端编译器被称为即时编译器。本节我们将会了解HotSpot虚拟机内的即时编译器的运作过程,此外,我们还将解决以下几个问题:
- 为何HotSpot虚拟机要使用解释器与即时编译器并存的架构?
- 为何HotSpot虚拟机要实现两个(或三个)不同的即时编译器?
- 程序何时使用解释器执行?何时使用编译器执行?
- 哪些程序代码会被编译为本地代码?如何编译本地代码?
- 如何从外部观察到即时编译器的编译过程和编译结果?
11.2.1 解释器与编译器
尽管并不是所有的Java虚拟机都采用解释器与编译器并存的运行架构,但目前主流的商用Java虚拟机,譬如HotSpot、OpenJ9等,内部都同时包含解释器与编译器[^1],解释器与编译器两者各有优势: 当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即运行。当程序启动后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更高的执行效率。当程序运行环境中内存资源限制较大,可以使用解释执行节约内存(如部分嵌入式系统中和大部分的JavaCard应用中就只有解释器的存在),反之可以使用编译执行来提升效率。同时,解释器还可以作为编译器激进优化时后备的“逃生门”(如果情况允许, HotSpot虚拟机中也会采用不进行激进优化的客户端编译器充当“逃生门”的角色),让编译器根据概率选择一些不能保证所有情况都正确,但大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,如加载了新类以后,类型继承结构出现变化、出现“罕见陷阱”(Uncommon Trap)时可以通过逆优化(Deoptimization)退回到解释状态继续执行,因此在整个Java虚拟机执行架构里,解释器与编译器经常是相辅相成地配合工作,其交互关系如图11-1所示。
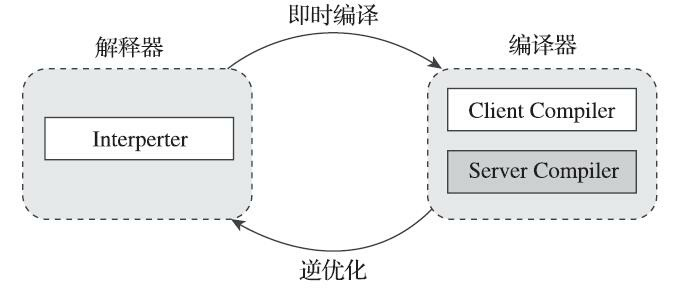
HotSpot虚拟机中内置了两个(或三个)即时编译器,其中有两个编译器存在已久,分别被称为“客户端编译器”(Client Compiler)和“服务端编译器”(Server Compiler),或者简称为C1编译器和C2编译器(部分资料和JDK源码中C2也叫Opto编译器),第三个是在JDK 10时才出现的、长期目标是代替C2的Graal编译器。Graal编译器目前还处于实验状态,本章将安排出专门的小节对它讲解与实战,在本节里,我们将重点关注传统的C1、C2编译器的工作过程。
在分层编译(Tiered Compilation)的工作模式出现以前,HotSpot虚拟机通常是采用解释器与其中一个编译器直接搭配的方式工作,程序使用哪个编译器,只取决于虚拟机运行的模式,HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用“-client”或“-server”参数去强制指定虚拟机运行在客户端模式还是服务端模式。
无论采用的编译器是客户端编译器还是服务端编译器,解释器与编译器搭配使用的方式在虚拟机中被称为“混合模式”(Mixed Mode),用户也可以使用参数“-Xint”强制虚拟机运行于“解释模式”(Interpreted Mode),这时候编译器完全不介入工作,全部代码都使用解释方式执行。另外,也可以使用参数“-Xcomp”强制虚拟机运行于“编译模式”(Compiled Mode),这时候将优先采用编译方式执行程序,但是解释器仍然要在编译无法进行的情况下介入执行过程。可以通过虚拟机的“- version”命令的输出结果显示出这三种模式,内容如代码清单11-1所示,请读者注意黑体字部分。
1 | $java -version |
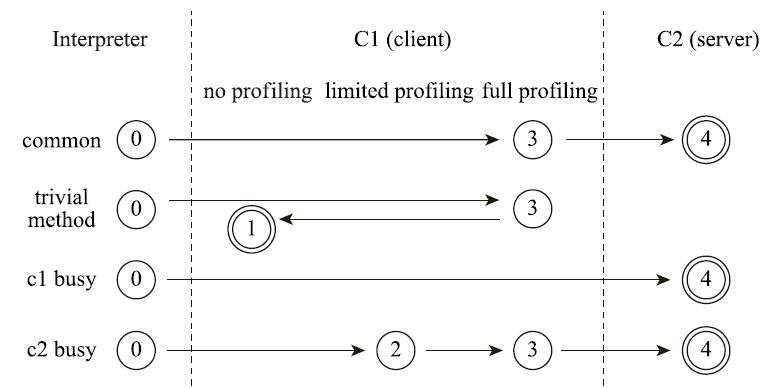
由于即时编译器编译本地代码需要占用程序运行时间,通常要编译出优化程度越高的代码,所花费的时间便会越长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行阶段的速度也有所影响。为了在程序启动响应速度与运行效率之间达到最佳平衡, HotSpot虚拟机在编译子系统中加入了分层编译的功能[^2],分层编译的概念其实很早就已经提出,但直到JDK 6时期才被初步实现,后来一直处于改进阶段,最终在JDK 7的服务端模式虚拟机中作为默认编译策略被开启。分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包括:
- 第0层。程序纯解释执行,并且解释器不开启性能监控功能(Profiling)。
- 第1层。使用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开启 性能监控功能。
- 第2层。仍然使用客户端编译器执行,仅开启方法及回边次数统计等有限的性能监控功能。
- 第3层。仍然使用客户端编译器执行,开启全部性能监控,除了第2层的统计信息外,还会收集如 分支跳转、虚方法调用版本等全部的统计信息。
- 第4层。使用服务端编译器将字节码编译为本地代码,相比起客户端编译器,服务端编译器会启 用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化。
以上层次并不是固定不变的,根据不同的运行参数和版本,虚拟机可以调整分层的数量。各层次编译之间的交互、转换关系如图11-2所示。
实施分层编译后,解释器、客户端编译器和服务端编译器就会同时工作,热点代码都可能会被多次编译,用客户端编译器获取更高的编译速度,用服务端编译器来获取更好的编译质量,在解释执行的时候也无须额外承担收集性能监控信息的任务,而在服务端编译器采用高复杂度的优化算法时,客户端编译器可先采用简单优化来为它争取更多的编译时间。
[^1]: 作为曾经的三大商用虚拟机之一的JRockit是个例外,它内部没有解释器,因此会存在本书中所说 的“启动响应时间长”之类的缺点,但它主要是面向服务端的应用,这类应用一般不会重点关注启动时 间,而且JRockit目前已经不再发展了。
[^2]: 分层编译在JDK 6时期出现,到JDK 7之前都需要使用-XX:+TieredCompilation参数来手动开启, 如果不开启分层编译策略,而虚拟机又运行在服务端模式,服务端编译器需要性能监控信息提供编译 依据,则是由解释器收集性能监控信息供服务端编译器使用。分层编译的相关资料可参见: http://weblogs.java.net/blog/forax/archive/2010/09/04/tiered-compilation。
[^3]: 图片来源:https://www.infoq.cn/article/java-10-jit-compiler-graal/。