SQL语言PPT
本章概要
SQL是结构化查询语言(Structured Query Language)的缩写,其功能包括数据查询、数据操纵、数据定义和数据控制四个部分。
SQL 语言简洁、方便实用、功能齐全,已成为目前应用最广的关系数据库语言。
本章要求
了解 SQL语言的特点,
掌握SQL语言的四大功能及使用方法,
重点掌握其数据查询功能及其使用。
3.1 SQL语言的基本概念与特点
3.1.1 SQL语言的发展及标准化
3.1.1.1 SQL语言发展史
SQL语言是当前最为成功、应用最为广泛的关系数据库语言,其发展主要经历了以下几个阶段:
1974年由CHAMBERLIN和BOYEE提出,当时称为SEQUEL(STUCTURED ENGLISH QUERY LANGUAGE);
IBM公司对其进行了修改,并用于其SYSTEM R关系数据库系统中;
1981年 IBM推出其商用关系关系数据库SQL/DS,并将其名字改为SQL,由于SQL语言功能强大,简洁易用,因此得到了广泛的使用;
今天广泛应用于各种大型数据库,如SYBASE、INFORMIX、 ORACLE、DB2、INGRES等,也用于各种小型数据库,如FOXPRO、ACCESS。
3.1.1.2 SQL语言标准化
随着关系数据库系统和SQL语言应用的日益广泛,SQL语言的标准化工作也在紧张革进行着,十多年来已制订了多个SQL标准;
- 1982年,美国国家标准化局(AMERICAN NATIONAL STANDARD INSTITUTE,简称ANSI)开始制定SQL标准;
- 1986年,美国国家标准化协会公布了SQL语言的第一个标准SQL86;
- 1987年,国际标准化组织(ISO)通过了SQL86标准;
- 1989年,国际标准化组织(ISO)对SQL86进行了补充,推出了SQL89标准;
- 1992年,ISO又推出了SQL92标准,也称为SQL2;
- 目前SQL99(也称为SQL3)在起草中,增加了面向对象的功能。
3.1.2 SQL语言的基本概念
首先介绍两个基本概念:基本表和视图。
基本表(BASE TABLE):
是独立存在的表,不是由其它的
表导出的表。一个关系对应一个基本表,一个或多个基本表对应一个存储文件。
视图(VIEW):
是一个虚拟的表,是从一个或几个基本表导出的表。它本身不独立存在于数据库中,数据库中只存放视图的定义而不存放视图对应的数据,这些数据仍存放在导出视图的基本表中。当基本表中的数据发生变化时,从视图中查询出来的数据也随之改变。
例如:学生数据库中有学生基本情况表STUDENT(SNO,SNAME,SSEX,SAGE,SDEPT),此表为基本表,对应一个存储文件。可以在其基础上定义一个男生基本情况表STUDENT_MALE(SNO,SNAME,SAGE,SDEPT),
它是从STUDENT中选择SSEX=’男’的各个行,然后在SNO,SNAME,SAGE,SDEPT上投影得到的。
在数据库中只存有STUDENT_MALE的定义,而STUDENT_MALE的记录不重复存储。
在用户看来,视图是通过不同路径去看一个实际表,就象一个窗口一样,我们通过窗户去看外面的高楼,可以看到高楼的不同部分,而透过视图可以看到数据库中自己感兴趣的内容。
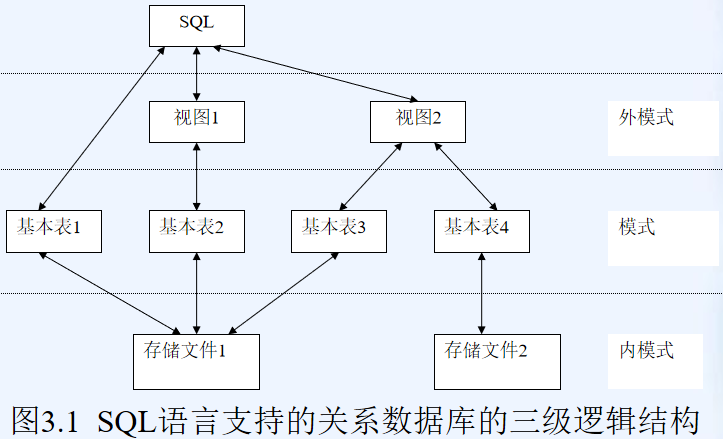
数据库三级模式
SQL语言支持数据库的三级模式结构,如图3.1所示。其中**外模式对应于==视图==和部分基本表,模式对应于==基本表==,内模式对应于==存储文件==**。
3.2 SQL数据定义
SQL语言使用数据定义语言(DATA DEFINITION LANGUAGE,简称DDL)实现其数据定义功能,可对数据库用户、基本表、视图、索引进行定义和撤消。
3.2.1 字段数据类型
当用SQL语句定义表时,需要为表中的每一个字段设置一个数据类型,用来指定字段所存放的数据是整数、字符串、货币或是其它类型的数据。
SQL SERVER 的数据类型有很多种,分为以下9类:
- 整数数据类型:依整数数值的范围大小,有BIT, INT , SMALLINT, TINYINT四种。
- 精确数值类型:用来定义可带小数部分的数字,有NUMERIC和DECIMAL两种。二者相同,但建议使用DECIMAL。如:123.0、8000.56
3.2.2 定义、修改和撤消数据库的用户
3.2.2.1 建立数据库用户
数据库用户是指能够登录到数据库,并能够对数据库进行存取操作的用户。
当SQL SERVER系统安装完毕后,数据库管理员就可以通过CREATE USER语句建立其他数据库用户了。
语法格式为:
1 | CREATE USER <用户名> IDENTIFIED BY <口令>; |
<用户名>指定数据库用户的帐号名字,即用户标识符,
<口令>指用户登录到数据库系统时使用的口令,
这里的用户名和口令可以与用户登录到操作系统时所使用的用户名和口令不同。
例3.1 建立一个新用户,其名称为ZHANGSAN,登录口令为123。
1 | CREATE USER ZHANGSAN IDENTIFIED BY 123; |
3.2.2.2 更改数据库用户的口令
数据库用户最初的口令是由数据库管理员指定的,数据库用户可以用ALTER USER命令来更改它,``ALTER USER语句的基本语法格式为:
1 | ALTER USER <用户名> IDENTIFIED BY <口令>; |
例3.2 将用户ZHANGSAN的口令改为456。
1 | ALTER USER ZHANGSAN IDENTIFIED BY 456; |
3.2.2.3 删除用户
随着数据库应用的发展和变化,数据库的用户也会发生变化。
如果某些数据库用户不再需要使用数据库,数据库管理员就可以使用DROP USER把该用户删掉,DROP USER 语句的基本语法格式为:
1 | DROP USER <用户名>; |
例3.3 删除用户ZHANGSAN
1 | DROP USER ZHANGSAN; |
注意:删除数据库用户之前应首先删除该用户建立的数据库对象,包括基本表、视图、索引等,否则系统将不允许删除这个用户。
3.2.2 建立数据库
1 | CREATE DATABASE <数据库名>; |
3.2.3 创建、修改和删除数据表
3.2.3.1 创建数据表
数据表是关系数据库的基本组成单位,它物理地存储于数据库的存储文件中。
- 创建一个数据表时主要包括以下几个组成部分:
(1)字段名(列名):字段名可长达128个字符。字段名可包含中文、英文字母、下划线、#号、货币符号(¥)及AT符号(@)。同一表中不许有重名列;
(2)字段数据类型:见表3.2;
(3)字段的长度、精度和小数位数;
2. 创建数据表的SQL语法格式
在SQL语言中,使用语句CREATE TABLE创建数据表,其基本语法格式为:
CREATE TABLE <表名>(<列定义>[{,<列定义>|<表约束>}])
<表名>是合法标识符,最多可有128个字符,如S,SC,C,不允许重名。
<列定义>:<列名><数据类型>[DEFAULT] [{<列约束>}]
例3.4 建立一学生表
1 | USE STUDENT |
执行该语句后,便产生了学生基本表的表框架,此表为一个空表。
其中,SEX列的缺省值为“男”。
3. 定义完整性约束
上列为创建基本表的最简单形式,还可以对表进一步定义,如主键、空值的设定,使数据库用户能够根据应用的需要对基本表的定义做出更为精确和详尽的规定。
在SQL SERVER中,对于基本表的约束分为列约束和表约束。
列约束是对某一个特定列的约束,包含在列定义中,直接跟在该列的其他定义之后,用空格分隔,不必指定列名;
表约束与列定义相互独立,不包括在列定义中,通常用于对多个列一起进行约束,与列定义用’,’分隔,定义表约束时必须指出要约束的那些列的名称。
完整性约束的基本语法格式为:
1 | [ CONSTRAINT <约束名> ] <约束类型>; |
约束名:约束不指定名称时,系统会给定一个名称。
约束类型
约束类型:在定义完整性约束时必须指定完整性约束的类型。
在SQL SERVER中可以定义五种类型的完整性约束,下面分别加以介绍:
(1)NULL/NOT NULL
是否允许该字段的值为NULL。
NULL值不是0也不是空白,更不是填入字符串“NULL”,而是表示“不知道”、“不确定”或“没有数据”的意思。
当某一字段的值一定要输入才有意义的时候,则可以设置为NOT NULL。
如主键列就不允许出现空值,否则就失去了唯一标识一条记录的作用
NOT NULL只能用于定义列约束,
其语法格式如下:
1 | [constraint <约束名> ][null|not null] ; |
例3.5 建立一个S表,对SNO字段进行NOT NULL约束。
1 | use student; |
当SNO为空时,系统给出错误信息,无NOT NULL约束时,系统缺省为NULL。
其中S_CONS为指定的约束名称,当约束名称省略时,系统自动产生一个名字。如下列功能同上,只是省略约束名称。
下面是省略not null约束名constraint s_cons的写法
1 | use student; |
(2)UNIQUE约束
UNIQUE约束用于指明基本表在某一列或多个列的组合上的取值必须唯一。
定义了UNIQUE约束的那些列称为唯一键,系统自动为唯一键建立唯一索引,从而保证了唯一键的唯一性。
唯一键允许为空,但系统为保证其唯一性,最多只可以出现一个NULL值。
unique既可用于列约束,也可用于表约束。
unique列约束
unique用于定义列约束时,其语法格式如下:
1 | [constraint <约束名>] unique |
例3.6 建立一个S表,定义SN为唯一键。
1 | use student |
其中sn_uniq为指定的约束名称,约束名称可以省略,
省略约束名的写法如下:
1 | use student |
unique用于定义表约束时,其语法格式如下:
1 | [constraint <约束名>] unique(<列名>[{,<列名>}]); |
例3.7 建立一个S表,定义SN+SEX为唯一键。
1 | use student |
系统为SN+SEX建立唯一索引,确保同一性别的学生没有重名。
(3)PRIMARY KEY约束
primary key约束用于定义基本表的主键,起唯一标识作用,其值不能为null,也不能重复,以此来保证实体的完整性。
primary key与unique约束类似,通过建立唯一索引来保证基本表在主键列取值的唯一性,但它们之间存在着很大的区别:
- 在一个基本表中只能定义一个
primary key约束,但可定义多个unique约束; - 对于指定为
primary key的一个列或多个列的组合,其中任何一个列都不能出现空值,而对于unique所约束的唯一键,则允许为空。
注意:不能为同一个列或一组列既定义unique约束,又定义primary key约束。primary key既可用于列约束,也可用于表约束。
primary key列约束
primary key用于定义列约束时,其语法格式如下:
1 | constraint <约束名> primary key; |
例3.8 建立一个S表,定义SNO为S的主键
1 | use student |
primary key表约束
primary key用于定义表约束时,即将某些列的组合定义为主键,其语法格式如下:
1 | [constraint <约束名>]s primary key (<列名>[{<列名>}]) |
例3.9 建立一个SC表,定义SNO+CNO为SC的主键
1 | use student |
(4)FOREIGN KEY约束
foreign key约束指定某一个列或一组列作为外部键,其中,包含外部键的表称为从表,包含外部键所引用的主键或唯一键的表称主表。
系统保证从表在外部键上的取值要么是主表中某一个主键值或唯一键值,要么取空值。以此保证两个表之间的连接,确保了实体的参照完整性。
foreign key既可用于列约束,也可用于表约束,
其语法格式为:
1 | [constraint <约束名>] foreign key references <主表名> (<列名>[{<列名>}]) |
例3.10 建立一个SC表,定义SNO,CNO为SC的外部键。
1 | use student |
(5)CHECK约束
CHECK约束用来检查字段值所允许的范围,如,一个字段只能输入整数,而且限定在0-100的整数,以此来保证域的完整性。
CHECK既可用于列约束,也可用于表约束,
其语法格式为:
1 | [constraint <约束名>] check (<条件>) |
例3.10 建立一个SC表,定义SCORE 的取值范围为0到100之间。
1 | use student |
例3.11 建立包含完整性定义的学生表
1 | use student |
3.2.3.2 修改基本表
由于应用环境和应用需求的变化,经常需要修改基本表的结构,比如,增加新列和完整性约束、修改原有的列定义和完整性约束等。
sql语言使用alter table命令来完成这一功能,有如下三种修改方式:
1. add方式
用于增加新列和完整性约束,定义方式同create table语句中的定义方式相同,其语法格式为:
1 | ALTER TABLE <表名> ADD <列定义> | <完整性约束定义>; |
例3.12 在S表中增加一个班号列和住址列。
1 | use student |
注意:使用此方式增加的新列自动填充NULL值,所以不能为增加的新列指定NOT NULL约束 。
例3.13 在SC表中增加完整性约束定义,使SCORE在0-100之间。
1 | use student |
2. ALTER 方式
用于修改某些列,其语法格式为:
1 | alter table<表名> |
例3.14 把S表中的SNO列加宽到8位字符宽度
1 | use student |
注意:使用此方式有如下一些限制:
①不能改变列名;
②不能将含有空值的列的定义修改为NOT NULL约束;
③若列中已有数据,则不能减少该列的宽度,也不能改变其数据类型;
④只能修改null|not null约束,其它类型的约束在修改之前必须先删除,然后再重新添加修改过的约束定义。
3.DROP方式
删除完整性约束定义,其语法格式为:
1 | alter table<表名> |
例3.15 删除S表中的AGE_CHK约束
1 | use student |
3.2.3.3 改变基本表的名字
使用rename命令,可以改变基本表的名字,其语法格式为:
1 | rename <旧表名> to <新表名>; |
例3.16 将S表的名字更改为STUDENT
1 | use student |
3.2.3.4 删除基本表
当某个基本表无用时,可将其删除。
删除后,该表中的数据和在此表上所建的索引都被删除,而建立在该表上的视图不会随之删除,系统将继续保留其定义,但已无法使用。
如果重新恢复该表,这些视图可重新使用。
删除表的语法格式:
1 | drop table <表名>; |
例3.17 删除表STUDENT
1 | use student |
注意:只能删除自己建立的表,不能删除其他用户所建的表。
3.2.5 设计、创建和维护索引
3.2.5.1 索引的作用
在日常生活中我们会经常遇到索引,例如图书目录、词典索引等。
借助索引,人们会很快地找到需要的东西。
索引是数据库随机检索的常用手段,它实际上就是记录的关键字与其相应地址的对应表。
例如,当我们要在本书中查找有关“SQL查询”的内容时,应该先通过目录找到“SQL查询”所对应的页码,然后从该页码中找出所要的信息。这种方法比直接翻阅书的内容要快。
如果把数据库表比作一本书,则表的索引就如书的目录一样,通过索引可大大提高查询速度。
此外,在SQL SERVER中,行的唯一性也是通过建立唯一索引来维护的。
索引的作用可归纳为:
- 加快查询速度;
- 保证行的唯一性。
3.2.5.2 索引的分类
按照索引记录的存放位置可分为聚集索引与非聚集索引
聚集索引:按照索引的字段排列记录,并且依照排好的顺序将记录存储在表中。
非聚集索引:按照索引的字段排列记录,但是排列的结果并不会存储在表中,而是另外存储。唯一索引的概念
唯一索引表示表中每一个索引值只对应唯一的数据记录,
这与表的PRIMARY KEY的特性类似,因此唯一性索引常用于PRIMARY KEY的字段上,以区别每一笔记录。
当表中有被设置为UNIQUE的字段时,SQL SERVER会自动建立一个非聚集的唯一性索引。
而当表中有PRIMARY KEY的字段时,SQL SERVER会在PRIMARY KEY字段建立一个聚集索引。复合索引的概念
复合索引是将两个字段或多个字段组合起来建立的索引,而单独的字段允许有重复的值。
3.2.5.3 建立索引
建立索引的语句是CREATE INDEX,其语法格式为:
1 | create [unique] [cluster] index <索引名> on <表名> (<列名> [次序] [{,<列名>}] [次序]…); |
UNIQUE表明建立唯一索引。
CLUSTER表示建立聚集索引。
次序用来指定索引值的排列顺序,可为ASC(升序)或DESC(降序),缺省值为ASC。
例3.18 为表SC在SNO和CNO上建立唯一索引。
1 | use student |
执行此命令后,为SC表建立一个索引名为SCI的唯一索引,
此索引为SNO和CNO两列的复合索引,即对SC表中的行先按SNO的递增顺序索引,对于相同的SNO,又按CNO的递增顺序索引。
由于有UNIQUE的限制,所以该索引在(SNO,CNO)组合列的排序上具有唯一性,不存在重复值。
例3.19 为教师表T在TN上建立聚集索引。
1 | create cluster index ti on t(tn); |
执行此命令后,为T表建立一个索引名为TI的聚集索引,T表中的记录将按照TN值的升序存放。
注意:
改变表中的数据(如增加或删除记录)时,索引将自动更新。
索引建立后,在查询使用该列时,系统将自动使用索引进行查询。索引数目无限制,但索引越多,更新数据的速度越慢。对于仅用于查询的表可多建索引,对于数据更新频繁的表则应少建索引。
3.2.5.4 删除索引
建立索引是为了提高查询速度,但随着索引的增多,数据更新时,系统会花费许多时间来维护索引。这时,应删除不必要的索引。
删除索引的语句是DROP INDEX,其语法格式为:
1 | DROP INDEX 数据表名.索引名; |
例3.20 删除表SC的索引SCI。
1 | drop index sc.sci; |