[root@localhost Linux_Test]# ls a.txt b.txt cat cmp c.txt date d.txt less ls more ps sed sort tr uniq vi wc 文件管理和目录管理 文件名和文件通配符 正则表达式 [root@localhost Linux_Test]# ls 文件管理和目录管理/* 文件管理和目录管理/HelloWorld2.c 文件管理和目录管理/HelloWorld.c
[root@localhost Linux_Test]# mkdir 文件管理和目录管理2 [root@localhost Linux_Test]# ls a.txt cat c.txt d.txt ls ps sort uniq wc 文件管理和目录管理2 正则表达式 b.txt cmp date less more sed tr vi 文件管理和目录管理 文件名和文件通配符 [root@localhost Linux_Test]#
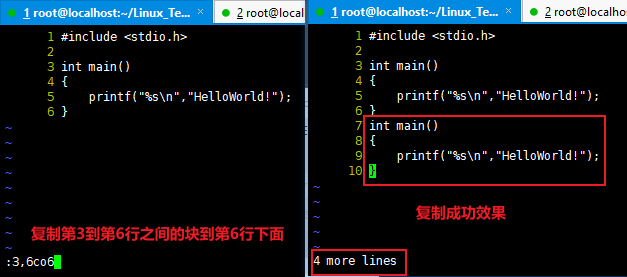
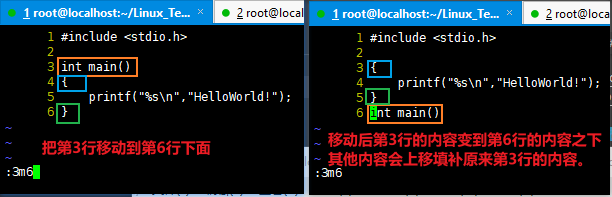
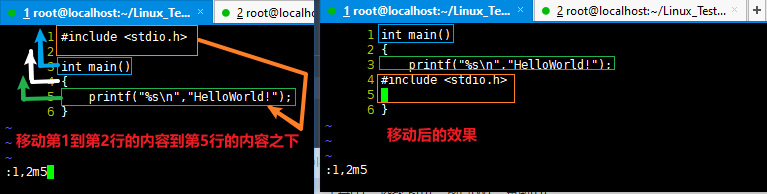
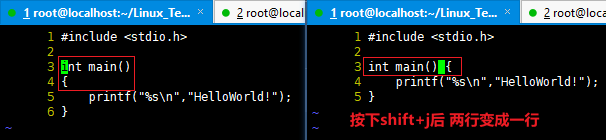
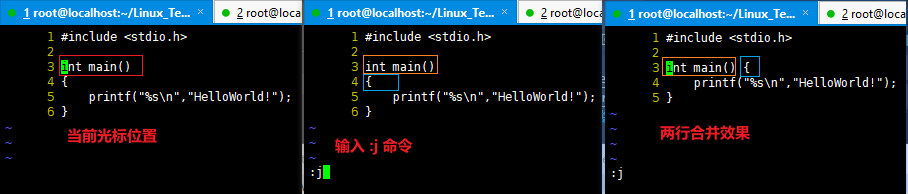
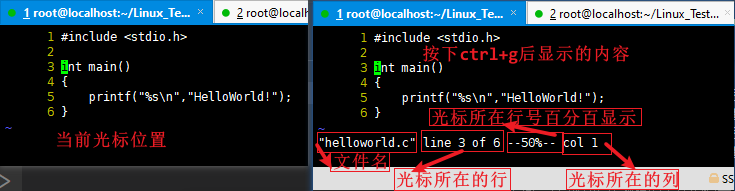
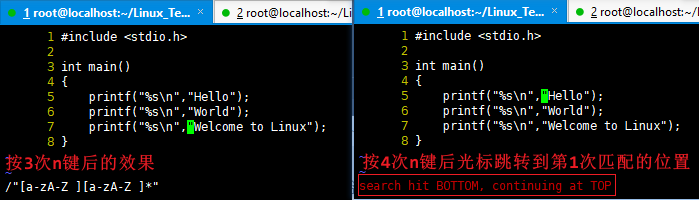
移动一个目录下的所有文件以及子目录 到 另一个目录
1 2 3 4 5 6 7 8
[root@localhost Linux_Test]# mv 文件管理和目录管理/* 文件管理和目录管理2 [root@localhost Linux_Test]# ls 文件管理和目录管理/ [root@localhost Linux_Test]# ls 文件管理和目录管理2/* 文件管理和目录管理2/HelloWorld2.c 文件管理和目录管理2/HelloWorld.c
[root@localhost Linux_Test]# ls a.txt cat c.txt d.txt ls ps sort uniq wc 文件管理和目录管理2 正则表达式 b.txt cmp date less more sed tr vi 文件管理和目录管理 文件名和文件通配符 [root@localhost Linux_Test]# tree -N 文件管理和目录管理 文件管理和目录管理
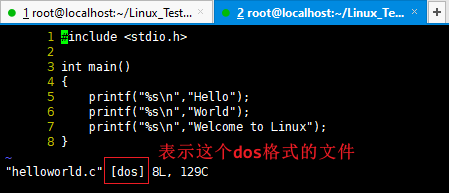
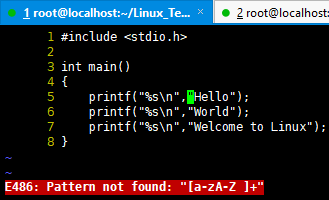
int main() { printf("%s\n","Hello"); printf("%s\n","World"); printf("%s\n","Welcome to Linux"); } lan@DESKTOP-8ISAT6B MINGW64 /g/Desktop/test/Linux $ file helloworld.c helloworld.c: C source, ASCII text, with CRLF line terminators
可以看到helloworld.c文件使用的是CRLF,也就是回车换行符\r\n。
Linux中打开Windows文本文件
将该文件上传到CentOS中,再次执行file命令:
1 2 3
[root@localhost encode]# file helloworld.c helloworld.c: C source, ASCII text, with CRLF line terminators [root@localhost encode]#
使用vi打开该文件:
Linux中吧Windows文本文件转换成Linux文本文件
1 2 3 4 5
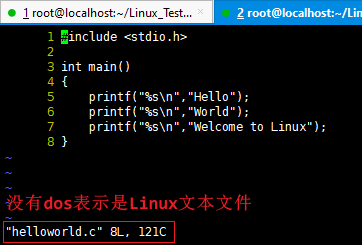
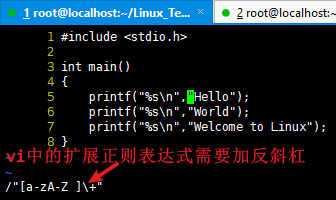
[root@localhost encode]# dos2unix helloworld.c dos2unix: converting file helloworld.c to Unix format ... [root@localhost encode]# file helloworld.c helloworld.c: C source, ASCII text [root@localhost encode]#
然后在使用vi打开该文件:
中文编码问题
问题
从Windows迁来的文件,只有在显示中文字符时是乱码。Linux本生的中文信息正常显示。
原因
中文GBK与UTF8不兼容
英文字符集
7比特ASCII码,字节高位为0的,后面7位是英文ASCII码
中文字符编码GBK
Windows默认中文编码方案,两个字节表示一个汉字,字节的高位为1,以区别于ASCII码
中文字符编码UTF8
许多Linux默认中文编码方案,三个字节表示一个汉字,字节的高位为1,以区别于ASCII码
检查系统设置
与语言有关的环境变量LANG应为en_US.UTF-8
1
env | grep LANG
若有问题,设置方法为:
1
export LANG=en_US.UTF-8
命令iconv:中文字符编码的转换
from GBK to UTF8
1
iconv –f gbk –t utf8
from UTF8 to GBK
1
iconv –f utf8 –t gbk
示例
1 2 3 4
$ echo "汉字" | od -t x1 0000000 e6 b1 89 e5 ad 97 0a $ echo "汉字" | iconv -f utf-8 -t gbk | od -t x1 0000000 ba ba d7 d6 0a