13.3 文本文件和字符流 上节介绍了如何以字节流的方式处理文件,对于文本文件,字节流没有编码的概念,不能按行处理,使用不太方便,更适合的是使用字符流,本节就来介绍字符流。
我们首先简要介绍文本文件的基本概念、与二进制文件的区别、编码,以及字符流和字节流的区别,然后介绍Java中的主要字符流,它们有:
除了这些类,Java中还有一个类Scanner,类似于一个Reader,但不是Reader的子类,可以读取基本类型的字符串形式,类似于PrintWriter的逆操作。理解了字节流和字符流后,我们介绍Java中的标准输入输出和错误流。最后,我们总结一些简单的实用方法。
13.3.1 基本概念 我们先来看一些基本概念,包括文本文件、编码和字符流。
1.文本文件 上节提到,处理文件要有二进制思维 。从二进制角度,我们通过一个简单的例子解释下文本文件与二进制文件的区别。比如,要存储整数123,使用二进制形式保存到文件test. dat,代码为:
1 2 3 4 5 6 7 DataOutputStream output = new DataOutputStream ( new FileOutputStream ("test.dat" )); try { output.writeInt(123 ); }finally { output.close(); }
使用UltraEdit打开该文件,显示的却是:
打开十六进制编辑器,显示如图13-3所示。
图13-3 整数123的二进制存储
在文件中存储的实际有4个字节,最低位字节7B对应的十进制数是123,也就是说,对int类型,二进制文件保存的直接就是int的二进制形式。这个二进制形式,如果当成字符来解释,显示成什么字符则与编码有关,如果当成UTF-32BE编码,解释成的就是一个字符,即{。
如果使用文本文件保存整数123,则代码为:
1 2 3 4 5 6 7 OutputStream output = new FileOutputStream ("test.txt" );try { String data = Integer.toString(123 ); output.write(data.getBytes("UTF-8" )); }finally { output.close(); }
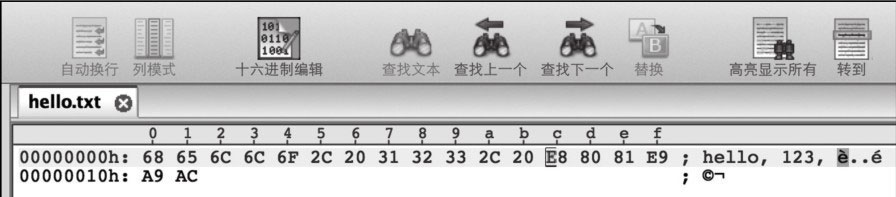
代码将整数123转换为字符串,然后将它的UTF-8编码输出到了文件中,使用Ultra-Edit打开该文件,显示的就是期望的:
打开十六进制编辑器,显示如图13-4所示。
图13-4 整数123的文本存储
文件中实际存储的有三个字节:31、32、33,对应的十进制数分别是49、50、51,分别对应字符’1’、’2’、’3’的ASCII编码。
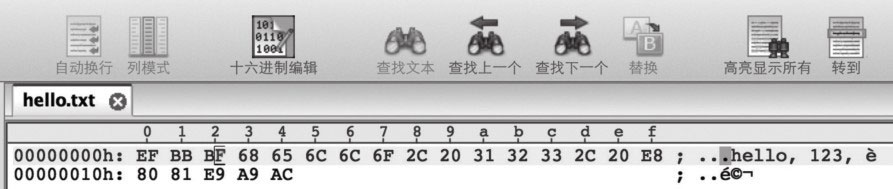
2.编码 在文本文件中,编码非常重要,同一个字符,不同编码方式对应的二进制形式可能是不一样的。我们看个例子,对同样的文本:
1)UTF-8编码,十六进制如图13-5所示。
图13-5 示例文本的UTF-8编码
英文和数字字符每个占一个字节,而每个中文占三个字节。
2)GB18030编码,十六进制如图13-6所示。
图13-6 示例文本的GB18030编码
英文和数字字符与UTF-8编码是一样的,但中文不一样,每个中文占两个字节。
3)UTF-16BE编码,十六进制为如图13-7所示。
图13-7 示例文本的UTF-16BE编码
无论是英文还是中文字符,每个字符都占两个字节。UTF-16BE也是Java内存中对字符的编码方式。
3.字符流 字节流是按字节读取的,而字符流则是按char读取 的,一个char在文件中保存的是几个字节与编码有关,但字符流封装了这种细节,我们操作的对象就是char。
需要说明的是,一个char不完全等同于一个字符 ,对于绝大部分字符,一个字符就是一个char,但我们之前介绍过,对于增补字符集中的字符,需要两个char表示,对于这种字符,Java中的字符流是按char而不是一个完整字符处理的。
理解了文本文件、编码和字符流的概念,我们再来看Java中的相关类,从基类开始。
13.3.2 Reader/Writer Reader与字节流的InputStream类似,也是抽象类,部分主要方法有:
1 2 3 4 5 public int read () throws IOExceptionpublic int read (char cbuf[]) throws IOExceptionabstract public void close () throws IOExceptionpublic long skip (long n) throws IOExceptionpublic boolean ready () throws IOException
方法的名称和含义与InputStream中的对应方法基本类似,但Reader中处理的单位是char,比如read读取的是一个char,取值范围为0~65 535。Reader没有available方法,对应的方法是ready()。
Writer与字节流的OutputStream类似,也是抽象类,部分主要方法有:
1 2 3 4 5 public void write (int c) public void write (char cbuf[]) public void write (String str) throws IOExceptionabstract public void close () throws IOException;abstract public void flush () throws IOException;
含义与OutputStream的对应方法基本类似,但Writer处理的单位是char, Writer还接受String类型,我们知道,String的内部就是char数组,处理时,会调用String的getChar方法先获取char数组。
InputStreamReader和OutputStreamWriter是适配器类,能将InputStream/OutputStream转换为Reader/Writer。
1. OutputStreamWriter OutputStreamWriter的主要构造方法为:
1 2 public OutputStreamWriter (OutputStream out) public OutputStreamWriter (OutputStream out, String charsetName)
一个重要的参数是编码类型,可以通过名字charsetName或Charset对象传入,如果没有传入,则为系统默认编码,默认编码可以通过Charset.defaultCharset()得到。Output-StreamWriter内部有一个类型为StreamEncoder的编码器,能将char转换为对应编码的字节。
我们看一段简单的代码,将字符串”hello, 123,老马”写到文件hello.txt中,编码格式为GB2312:
1 2 3 4 5 6 7 8 Writer writer = new OutputStreamWriter ( new FileOutputStream ("hello.txt" ), "GB2312" ); try { String str = "hello, 123, 老马" ; writer.write(str); }finally { writer.close(); }
创建一个FileOutputStream,然后将其包在一个OutputStreamWriter中,就可以直接以字符串写入了。
InputStreamReader的主要构造方法为:
1 2 public InputStreamReader (InputStream in) public InputStreamReader (InputStream in, String charsetName)
与OutputStreamWriter一样,一个重要的参数是编码类型。InputStreamReader内部有一个类型为StreamDecoder的解码器,能将字节根据编码转换为char。
我们看一段简单的代码,将上面写入的文件读进来:
1 2 3 4 5 6 7 8 9 Reader reader = new InputStreamReader ( new FileInputStream ("hello.txt" ), "GB2312" ); try { char [] cbuf = new char [1024 ]; int charsRead = reader.read(cbuf); System.out.println(new String (cbuf, 0 , charsRead)); }finally { reader.close(); }
这段代码假定一次read调用就读到了所有内容,且假定长度不超过1024。为了确保读到所有内容,可以借助待会介绍的CharArrayWriter或StringWriter。
13.3.4 FileReader/FileWriter FileReader/FileWriter的输入和目的是文件。FileReader是InputStreamReader的子类,它的主要构造方法有:
1 2 public FileReader (File file) throws FileNotFoundExceptionpublic FileReader (String fileName) throws FileNotFoundException
FileWriter是OutputStreamWriter的子类,它的主要构造方法有:
1 2 public FileWriter (File file) throws IOExceptionpublic FileWriter (String fileName, boolean append) throws IOException
append参数指定是追加还是覆盖,如果没传,则为覆盖。
需要注意的是,FileReader/FileWriter不能指定编码类型,只能使用默认编码,如果需要指定编码类型,可以使用InputStreamReader/OutputStreamWriter 。
13.3.5 CharArrayReader/CharArrayWriter CharArrayWriter与ByteArrayOutputStream类似,它的输出目标是char数组,这个数组的长度可以根据数据内容动态扩展。
CharArrayWriter有如下方法,可以方便地将数据转换为char数组或字符串:
1 2 public char [] toCharArray()public String toString ()
使用CharArrayWriter,我们可以改进上面的读文件代码,确保将所有文件内容读入:
1 2 3 4 5 6 7 8 9 10 11 12 13 Reader reader = new InputStreamReader ( new FileInputStream ("hello.txt" ), "GB2312" ); try { CharArrayWriter writer = new CharArrayWriter (); char [] cbuf = new char [1024 ]; int charsRead = 0 ; while ((charsRead=reader.read(cbuf))! =-1 ){ writer.write(cbuf, 0 , charsRead); } System.out.println(writer.toString()); }finally { reader.close(); }
读入的数据先写入CharArrayWriter中,读完后,再调用其toString()方法获取完整数据。
CharArrayReader与上节介绍的ByteArrayInputStream类似,它将char数组包装为一个Reader,是一种适配器模式,它的构造方法有:
1 2 public CharArrayReader (char buf[]) public CharArrayReader (char buf[], int offset, int length)
13.3.6 StringReader/StringWriter StringReader/StringWriter与CharArrayReader/CharArrayWriter类似,只是输入源为String,输出目标为StringBuffer,而且,String/StringBuffer内部是由char数组组成的,所以它们本质上是一样的,具体我们就不赘述了。之所以要将char数组和String与Reader/Writer进行转换,也是为了能够方便地参与Reader/Writer构成的协作体系,复用代码。
13.3.7 BufferedReader/BufferedWriter BufferedReader/BufferedWriter是装饰类,提供缓冲,以及按行读写功能。Buffered-Writer的构造方法有:
1 2 public BufferedWriter (Writer out) public BufferedWriter (Writer out, int sz)
参数sz是缓冲大小,如果没有提供,默认为8192。它有如下方法,可以输出平台特定的换行符:
1 public void newLine () throws IOException
BufferedReader的构造方法有:
1 2 public BufferedReader (Reader in) public BufferedReader (Reader in, int sz)
参数sz是缓冲大小,如果没有提供,默认为8192。它有如下方法,可以读入一行:
1 public String readLine () throws IOException
字符’\r’或’\n’或’\r\n’被视为换行符,readLine返回一行内容,但不会包含换行符,当读到流结尾时,返回null。
FileReader/FileWriter是没有缓冲的,也不能按行读写,所以,一般应该在它们的外面包上对应的缓冲类 。我们来看个例子,还是学生列表,这次我们使用可读的文本进行保存,一行保存一条学生信息,学生字段之间用逗号分隔,保存的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void writeStudents (List<Student> students) throws IOException{ BufferedWriter writer = null ; try { writer = new BufferedWriter (new FileWriter ("students.txt" )); for (Student s : students){ writer.write(s.getName()+", " +s.getAge()+", " +s.getScore()); writer.newLine(); } }finally { if (writer! =null ){ writer.close(); } } }
保存后的文件内容显示为:
从文件中读取的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static List<Student> readStudents () throws IOException{ BufferedReader reader = null ; try { reader = new BufferedReader ( new FileReader ("students.txt" )); List<Student> students = new ArrayList <>(); String line = reader.readLine(); while (line! =null ){ String[] fields = line.split(", " ); Student s = new Student (); s.setName(fields[0 ]); s.setAge(Integer.parseInt(fields[1 ])); s.setScore(Double.parseDouble(fields[2 ])); students.add(s); line = reader.readLine(); } return students; }finally { if (reader! =null ){ reader.close(); } } }
使用readLine读入每一行,然后使用String的方法分隔字段,再调用Integer和Double的方法将字符串转换为int和double。这种对每一行的解析可以使用类Scanner进行简化,待会我们介绍。
13.3.8 PrintWriter PrintWriter有很多重载的print方法,如:
1 2 public void print (int i) public void print (Object obj)
它会将这些参数转换为其字符串形式,即调用String.valueOf(),然后再调用write。它也有很多重载形式的println方法,println除了调用对应的print,还会输出一个换行符。除此之外,PrintWriter还有格式化输出方法,如:
1 public PrintWriter printf (String format, Object ... args)
format表示格式化形式,比如,保留小数点后两位,格式可以为:
1 2 PrintWriter writer = …writer.format("%.2f" , 123.456f );
输出为:
更多格式化的内容可以参看API文档,本节就不赘述了。
PrintWriter的方便之处在于,它有很多构造方法,可以接受文件路径名、文件对象、OutputStream、Writer等,对于文件路径名和File对象,还可以接受编码类型作为参数,比如:
1 2 3 4 public PrintWriter (File file) throws FileNotFoundExceptionpublic PrintWriter (String fileName, String csn) public PrintWriter (OutputStream out, boolean autoFlush) public PrintWriter (Writer out)
参数csn表示编码类型,对于以文件对象和文件名为参数的构造方法,PrintWriter内部会构造一个BufferedWriter,比如:
1 2 3 4 public PrintWriter (String fileName) throws FileNotFoundException { this (new BufferedWriter (new OutputStreamWriter ( new FileOutputStream (fileName))), false ); }
对于以OutputSream为参数的构造方法,PrintWriter也会构造一个BufferedWriter,比如:
1 2 3 4 public PrintWriter (OutputStream out, boolean autoFlush) { this (new BufferedWriter (new OutputStreamWriter (out)), autoFlush); … }
对于以Writer为参数的构造方法,PrintWriter就不会包装BufferedWriter了。
构造方法中的autoFlush参数表示同步缓冲区的时机,如果为true,则在调用println、printf或format方法的时候,同步缓冲区,如果没有传,则不会自动同步,需要根据情况调用flush方法。
可以看出,PrintWriter是一个非常方便的类,可以直接指定文件名作为参数,可以指定编码类型,可以自动缓冲,可以自动将多种类型转换为字符串,在输出到文件时,可以优先选择该类。
上面的保存学生列表代码,使用PrintWriter,可以写为:
1 2 3 4 5 6 7 8 9 10 public static void writeStudents (List<Student> students) throws IOException{ PrintWriter writer = new PrintWriter ("students.txt" ); try { for (Student s : students){ writer.println(s.getName()+", " +s.getAge()+", " +s.getScore()); } }finally { writer.close(); } }
PrintWriter有一个非常相似的类PrintStream,除了不能接受Writer作为构造方法外, PrintStream的其他构造方法与PrintWriter一样。PrintStream也有几乎一样的重载的print和println方法,只是自动同步缓冲区的时机略有不同,在PrintStream中,只要碰到一个换行字符’\n’,就会自动同步缓冲区。PrintStream与PrintWriter的另一个区别是,虽然它们都有如下方法:
1 public void write (int b)
但含义是不一样的,PrintStream只使用最低的8位,输出一个字节,而PrintWriter是使用最低的两位,输出一个char。
13.3.9 Scanner Scanner是一个单独的类,它是一个简单的文本扫描器,能够分析基本类型和字符串,它需要一个分隔符来将不同数据区分开来,默认是使用空白符,可以通过useDelimiter()方法进行指定。Scanner有很多形式的next()方法,可以读取下一个基本类型或行,如:
1 2 3 public float nextFloat () public int nextInt () public String nextLine ()
Scanner也有很多构造方法,可以接受File对象、InputStream、Reader作为参数,它也可以将字符串作为参数,这时,它会创建一个StringReader。比如,以前面的解析学生记录为例,使用Scanner,代码可以改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static List<Student> readStudents () throws IOException{ BufferedReader reader = new BufferedReader ( new FileReader ("students.txt" )); try { List<Student> students = new ArrayList <Student>(); String line = reader.readLine(); while (line! =null ){ Student s = new Student (); Scanner scanner = new Scanner (line).useDelimiter(", " ); s.setName(scanner.next()); s.setAge(scanner.nextInt()); s.setScore(scanner.nextDouble()); students.add(s); line = reader.readLine(); } return students; }finally { reader.close(); } }
13.3.10 标准流 我们之前一直在使用System.out向屏幕上输出,它是一个PrintStream对象,输出目标就是所谓的“标准”输出,经常是屏幕。除了System.out, Java中还有两个标准流:System. in和System.err。
System.in表示标准输入,它是一个InputStream对象,输入源经常是键盘。比如,从键盘接受一个整数并输出,代码可以为:
1 2 3 Scanner in = new Scanner (System.in);int num = in.nextInt();System.out.println(num);
System.err表示标准错误流,一般异常和错误信息输出到这个流,它也是一个Print-Stream对象,输出目标默认与System.out一样,一般也是屏幕。
标准流的一个重要特点是,它们可以重定向 ,比如可以重定向到文件,从文件中接受输入,输出也写到文件中。在Java中,可以使用System类的setIn、setOut、setErr进行重定向,比如:
1 2 3 4 5 6 7 8 9 10 System.setIn(new ByteArrayInputStream ("hello" .getBytes("UTF-8" ))); System.setOut(new PrintStream ("out.txt" )); System.setErr(new PrintStream ("err.txt" )); try { Scanner in = new Scanner (System.in); System.out.println(in.nextLine()); System.out.println(in.nextLine()); }catch (Exception e){ System.err.println(e.getMessage()); }
标准输入重定向到了一个ByteArrayInputStream,标准输出和错误重定向到了文件,所以第一次调用in.nextLine就会读取到”hello”,输出文件out.txt中也包含该字符串,第二次调用in.nextLine会触发异常,异常消息会写到错误流中,即文件err.txt中会包含异常消息,为”No line found”。
在实际开发中,经常需要重定向标准流。比如,在一些自动化程序中,经常需要重定向标准输入流,以从文件中接受参数,自动执行,避免人手工输入。在后台运行的程序中,一般都需要重定向标准输出和错误流到日志文件,以记录和分析运行的状态和问题。
在Linux系统中,标准输入输出流也是一种重要的协作机制 。很多命令都很小,只完成单一功能,实际完成一项工作经常需要组合使用多条命令,它们协作的模式就是通过标准输入输出流,每个命令都可以从标准输入接受参数,处理结果写到标准输出,这个标准输出可以连接到下一个命令作为标准输入,构成管道式的处理链条。比如,查找一个日志文件access.log中127.0.0.1出现的行数,可以使用命令:
1 cat access.log | grep 127.0.0.1 | wc -l
有三个程序cat、grep、wc, |是管道符号,它将cat的标准输出重定向为了grep的标准输入,而grep的标准输出又成了wc的标准输入。
13.3.11 实用方法 可以看出,字符流也包含了很多的类,虽然很灵活,但对于一些简单的需求,却需要写很多代码,实际开发中,经常需要将一些常用功能进行封装,提供更为简单的接口。下面我们提供一些实用方法,以供参考,代码比较简单,就不解释了。
复制Reader到Writer,代码为:
1 2 3 4 5 6 7 8 public static void copy (final Reader input, final Writer output) throws IOException { char [] buf = new char [4096 ]; int charsRead = 0 ; while ((charsRead = input.read(buf)) ! = -1 ) { output.write(buf, 0 , charsRead); } }
将文件全部内容读入到一个字符串,参数为文件名和编码类型,代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static String readFileToString (final String fileName, final String encoding) throws IOException{ BufferedReader reader = null ; try { reader = new BufferedReader (new InputStreamReader ( new FileInputStream (fileName), encoding)); StringWriter writer = new StringWriter (); copy(reader, writer); return writer.toString(); }finally { if (reader! =null ){ reader.close(); } } }
这个方法利用了StringWriter,并调用了上面的复制方法。
将字符串写到文件,参数为文件名、字符串内容和编码类型,代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void writeStringToFile (final String fileName, final String data, final String encoding) throws IOException { Writer writer = null ; try { writer = new OutputStreamWriter ( new FileOutputStream (fileName), encoding); writer.write(data); }finally { if (writer! =null ){ writer.close(); } } }
按行将多行数据写到文件,参数为文件名、编码类型、行的集合,代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void writeLines (final String fileName, final String encoding, final Collection<? > lines) throws IOException { PrintWriter writer = null ; try { writer = new PrintWriter (fileName, encoding); for (Object line : lines){ writer.println(line); } }finally { if (writer! =null ){ writer.close(); } } }
按行将文件内容读到一个列表中,参数为文件名、编码类型,代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public static List<String> readLines (final String fileName, final String encoding) throws IOException{ BufferedReader reader = null ; try { reader = new BufferedReader (new InputStreamReader ( new FileInputStream (fileName), encoding)); List<String> list = new ArrayList <>(); String line = reader.readLine(); while (line! =null ){ list.add(line); line = reader.readLine(); } return list; }finally { if (reader! =null ){ reader.close(); } } }
13.3.12 小结 本节介绍了如何在Java中以字符流的方式读写文本文件,我们强调了二进制思维、文本文本与二进制文件的区别、编码,以及字符流与字节流的不同,介绍了个各种字符流、Scanner以及标准流,最后总结了一些实用方法。完整的代码在github上,地址为https://github.com/swiftma/program-logic ,位于包shuo.laoma.file.c58下。
写文件时,可以优先考虑PrintWriter,因为它使用方便,支持自动缓冲、指定编码类型、类型转换等。读文件时,如果需要指定编码类型,需要使用InputStreamReader;如果不需要指定编码类型,可使用FileReader,但都应该考虑在外面包上缓冲类Buffered-Reader。
通过前面两个小节,我们应该可以从容地读写文件内容了,但文件和目录本身的操作,如查看元数据信息、文件重命名、遍历文件、查找文件、新建目录等,又该如何进行呢?让我们下节介绍。