3.6 低延迟垃圾收集器
HotSpot的垃圾收集器从Serial发展到CMS再到G1,经历了逾二十年时间,经过了数百上千万台服务器上的应用实践,已经被淬炼得相当成熟了,不过它们距离“完美”还是很遥远。怎样的收集器才算是“完美”呢?这听起来像是一道主观题,其实不然,完美难以实现,但是我们确实可以把它客观描述出来。
衡量垃圾收集器的三项最重要的指标是:内存占用(Footprint)、吞吐量(Throughput)和延迟 (Latency),三者共同构成了一个“不可能三角^1”。三者总体的表现会随技术进步而越来越好,但是要在这三个方面同时具有卓越表现的“完美”收集器是极其困难甚至是不可能的,一款优秀的收集器通常最多可以同时达成其中的两项。
在内存占用、吞吐量和延迟这三项指标里,延迟的重要性日益凸显,越发备受关注。其原因是随着计算机硬件的发展、性能的提升,我们越来越能容忍收集器多占用一点点内存;硬件性能增长,对软件系统的处理能力是有直接助益的,硬件的规格和性能越高,也有助于降低收集器运行时对应用程序的影响,换句话说,吞吐量会更高。但对延迟则不是这样,硬件规格提升,准确地说是内存的扩大,对延迟反而会带来负面的效果,这点也是很符合直观思维的:虚拟机要回收完整的1TB的堆内存,毫无疑问要比回收1GB的堆内存耗费更多时间。由此,我们就不难理解为何延迟会成为垃圾收集器最被重视的性能指标了。现在我们来观察一下现在已接触过的垃圾收集器的停顿状况,如图3-14所示。
图3-14中浅色阶段表示必须挂起用户线程,深色表示收集器线程与用户线程是并发工作的。由图3-14可见,在CMS和G1之前的全部收集器,其工作的所有步骤都会产生“Stop The World”式的停顿; CMS和G1分别使用增量更新和原始快照(见3.4.6节)技术,实现了标记阶段的并发,不会因管理的堆内存变大,要标记的对象变多而导致停顿时间随之增长。但是对于标记阶段之后的处理,仍未得到妥善解决。CMS使用标记-清除算法,虽然避免了整理阶段收集器带来的停顿,但是清除算法不论如何优化改进,在设计原理上避免不了空间碎片的产生,随着空间碎片不断淤积最终依然逃不过“Stop The World”的命运。G1虽然可以按更小的粒度进行回收,从而抑制整理阶段出现时间过长的停顿,但毕竟也还是要暂停的。
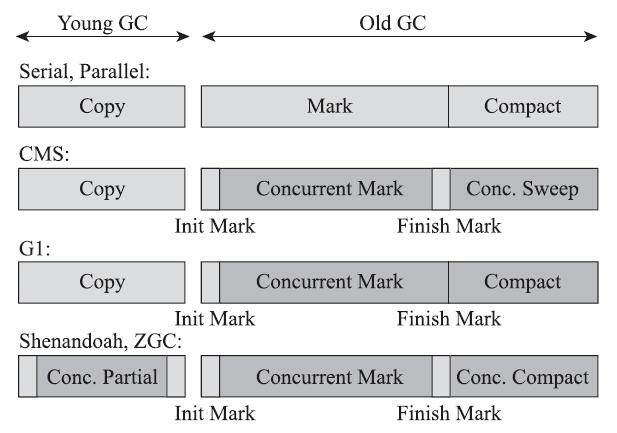
图3-14 各款收集器的并发情况
读者肯定也从图3-14中注意到了,最后的两款收集器,Shenandoah和ZGC,几乎整个工作过程全部都是并发的,只有初始标记、最终标记这些阶段有短暂的停顿,这部分停顿的时间基本上是固定的,与堆的容量、堆中对象的数量没有正比例关系。实际上,它们都可以在任意可管理的(譬如现在ZGC只能管理4TB以内的堆)堆容量下,实现垃圾收集的停顿都不超过十毫秒这种以前听起来是天方夜谭、匪夷所思的目标。这两款目前仍处于实验状态的收集器,被官方命名为“低延迟垃圾收集器”(Low-Latency Garbage Collector或者Low-Pause-Time Garbage Collector)。