13.3.5 偏向锁
13.3.5 偏向锁
偏向锁也是JDK 6中引入的一项锁优化措施,它的目的是消除数据在无竞争情况下的同步原语, 进一步提高程序的运行性能。如果说轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连CAS操作都不去做了。
偏向锁中的“偏”,就是偏心的“偏”、偏袒的“偏”。它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。
如果读者理解了前面轻量级锁中关于对象头Mark Word与线程之间的操作过程,那偏向锁的原理就会很容易理解。假设当前虚拟机启用了偏向锁(启用参数-XX:+UseBiased Locking,这是自JDK 6 起HotSpot虚拟机的默认值),那么当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设置为“01”、把偏向模式设置为“1”,表示进入偏向模式。同时使用CAS操作把获取到这个锁的线程的ID记录在对象的Mark Word之中。如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新操作等)。
一旦出现另外一个线程去尝试获取这个锁的情况,偏向模式就马上宣告结束。根据锁对象目前是否处于被锁定的状态决定是否撤销偏向(偏向模式设置为“0”),撤销后标志位恢复到未锁定(标志位为“01”)或轻量级锁定(标志位为“00”)的状态,后续的同步操作就按照上面介绍的轻量级锁那样去执行。偏向锁、轻量级锁的状态转化及对象Mark Word的关系如图13-5所示。
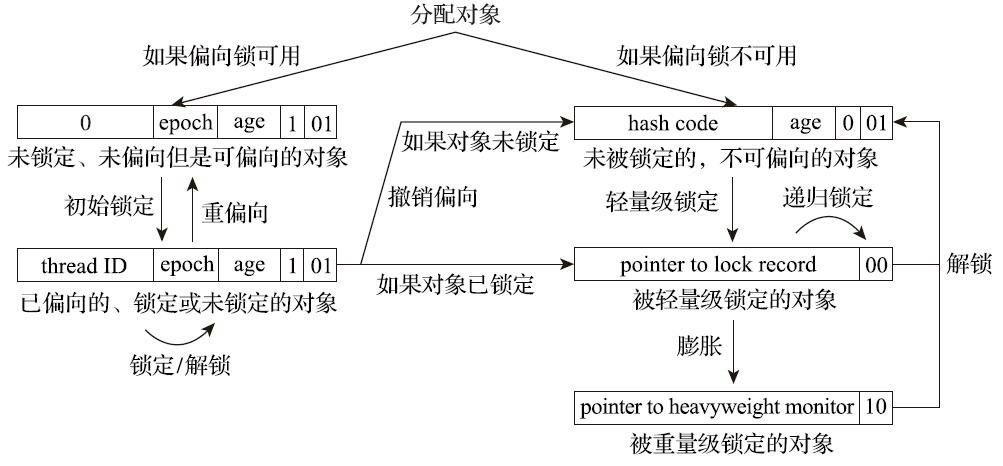
细心的读者看到这里可能会发现一个问题:当对象进入偏向状态的时候,Mark Word大部分的空间(23个比特)都用于存储持有锁的线程ID了,这部分空间占用了原有存储对象哈希码的位置,那原来对象的哈希码怎么办呢?
在Java语言里面一个对象如果计算过哈希码,就应该一直保持该值不变(强烈推荐但不强制,因为用户可以重载hashCode()方法按自己的意愿返回哈希码),否则很多依赖对象哈希码的API都可能存在出错风险。而作为绝大多数对象哈希码来源的Object::hashCode()方法,返回的是对象的一致性哈希码(Identity Hash Code),这个值是能强制保证不变的,它通过在对象头中存储计算结果来保证第一次计算之后,再次调用该方法取到的哈希码值永远不会再发生改变。因此,当一个对象已经计算过一致性哈希码后,它就再也无法进入偏向锁状态了;而当一个对象当前正处于偏向锁状态,又收到需要计算其一致性哈希码请求[^1]时,它的偏向状态会被立即撤销,并且锁会膨胀为重量级锁。在重量级锁的实现中,对象头指向了重量级锁的位置,代表重量级锁的ObjectMonitor类里有字段可以记录非加锁状态(标志位为“01”)下的Mark Word,其中自然可以存储原来的哈希码。
偏向锁可以提高带有同步但无竞争的程序性能,但它同样是一个带有效益权衡(Trade Off)性质的优化,也就是说它并非总是对程序运行有利。如果程序中大多数的锁都总是被多个不同的线程访问,那偏向模式就是多余的。在具体问题具体分析的前提下,有时候使用参数-XX:- UseBiasedLocking来禁止偏向锁优化反而可以提升性能。
[^1]: 注意,这里说的计算请求应来自于对Object::hashCode()或者System::identityHashCode(Object)方法的 调用,如果重写了对象的hashCode()方法,计算哈希码时并不会产生这里所说的请求。