2021年09月02日 java
考点1:switch-case穿透 没有break的switch-case语句
1 | int i = 3; |
请给出最终输出内容。
- A
it me - B
him her it me - C
him her - D
me
解析
显示答案/隐藏答案
正确答案: A没有break,会产生穿透,从满足条件的case开始执行到底
考点2:java常用包
下面有关JDK中的包和他们的基本功能,描述错误的是?
- A
java.awt: 包含构成抽象窗口工具集的多个类,用来构建和管理应用程序的图形用户界面 - B
java.io: 包含提供多种输出输入功能的类 - C
java.lang: 包含执行与网络有关的类,如URL,SCOKET,SEVERSOCKET - D
java.util: 包含一些实用性的类
解析
显示答案/隐藏答案
正确答案: C- java.awt:提供了绘图和图像类,主要用于编写GUI程序,包括按钮、标签等常用组件以及相应的事件类。
- java.lang:java的语言包,是核心包,默认导入到用户程序,包中有object类,数据类型包装类,数学类,字符串类,系统和运行时类,操作类,线程类,错误和异常处理类,过程类。
- java.io:包含提供多种输出输入功能的类。
- java.net: 包含执行与网络有关的类,如URL,SCOKET,SEVERSOCKET等。
- java.applet:包含java小应用程序的类。
- java.util:包含集合框架、遗留的 collection 类、事件模型、日期和时间设施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组、日期Date类、堆栈Stack类、向量Vector类等)。集合类、时间处理模式、日期时间工具等各类常用工具包。
- java.sql:提供使用 JavaTM 编程语言访问并处理存储在数据源(通常是一个关系数据库)中的数据的 API。
java.lang——包含一些Java语言的核心类,如String、Math、Integer、System和Thread,提供常用功能。
java.net——包含执行与网络相关的操作的类和接口。
java.io——包含提供多种输入/输出功能的类。
java.util——包含一些实用性工具类,如定义系统特性、接口的集合框架类、使用与日期日历相关的函数。
java.text——包含了一些java格式化相关的类
java.sql——包含了java进行JDBC数据库编程的相关类/接口
java.awt——包含了构成抽象窗口工具集(abstract window toolkits)的多个类,这些类被用来构建和管理应用程序的图形用户界面(GUI)。
考点3:运算符
Java中只有整型才能使用的运算符为?
- A
* - B
/ - C
% - D
+
解析
显示答案/隐藏答案
正确答案: C答案:C
ABD选项的操作符都可用于float和double
只有%取余操作,只适用于整型
运算对象为整型的运算符:%取余~取反,&按位与, |按位或,^按位异或.
C不对,%可以应用于doube,并非整型才能用。感觉这道题没有正确答案
这题有问题吧,java中浮点数也可以用%,只不过由于精度问题,结果常会不准确。
取余如何实现
java取余就是用被除数一直减去除数,直到差小于除数为止,这也正是余数的定义。
例如:
1 | double a = 10%3.0; |
可以看出,在求余时的减法过程中,就已经丢失精度了,所以最后的结果当然不准确。
考点4:循环
以下代码的循环次数是
1 | public class Test { |
- A 0
- B 1
- C 7
- D 无限次
解析
显示答案/隐藏答案
正确答案: D执行1次,5
执行2次,3
执行3次,1
执行4次,-1
永远执行不到0
每一次循环都会减二,7每次减2都是成奇数。永远执行不到0。
考点5:异常处理
在异常处理中,以下描述不正确的有
- A
try块不可以省略 - B 可以使用多重
catch块 - C
finally块可以省略 - D
catch块和finally块可以同时省略
解析
显示答案/隐藏答案
正确答案: D选D 假如try中有异常抛出,则会去执行catch块,再去执行finally块;假如没有catch 块,可以直接执行finally
块。catch和finally不能同时都省略。
1 | package base; |
运行结果:
1 | catch-1... |
可以看到
- finally块一定会执行,
- 只有在catch块中调用System.exit()结束了虚拟机,finally才不会执行。
考点6:接口修饰符
能用来修饰interface的有()
- A
private - B
public - C
protected - D
static
解析
显示答案/隐藏答案
正确答案: B定义非内部java接口可以使用public和package修饰,这一点可以在Eclipse创建接口时查看:
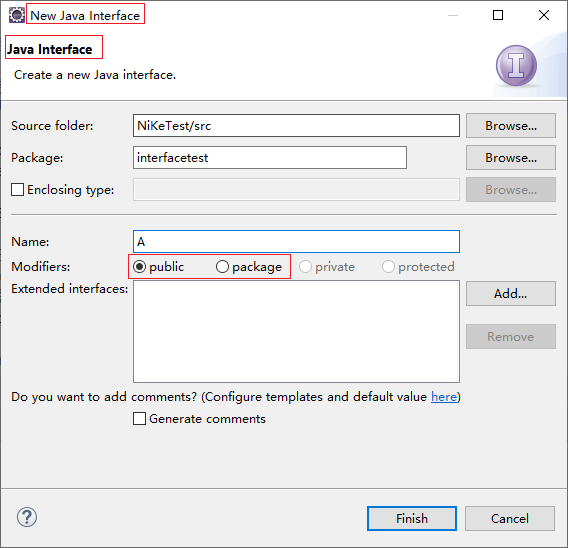
package权限的接口
所以的package权限,就是什么都不写:
1 | package interfacetest; |
public修饰的接口
1 | package interfacetest; |
内部接口没有限制
内部接口与类的成员变量一样,如下的代码是没有错误的:
1 | package interfacetest; |
考点7:调动线程的start方法才会启动线程
以下程序运行的结果为 ( )
1 | public class Example extends Thread{ |
- A
run main - B
main run - C
main - D
run - E 不能确定
解析
显示答案/隐藏答案
正确答案: A调用example.run(),并没有创建新线程,只有main线程由上而下执行,Thread.sleep(1000)只是让main线程休眠了1000ms;最终打印出了run main
调用example.start(),创建了一个新线程,运行到Thread.sleep(1000),该线程休眠了1000ms;main线程先打印main,新创建的线程结束休眠后,打印run,最终打印出了main run
考点8:多态 向上转型 类的加载顺序 运行时表现子类特性
下面代码的输出是什么?
1 | public class Base { |
- A
null - B
sub - C
base
解析
显示答案/隐藏答案
正确答案: Anew Sub();在创造派生类的过程中首先创建基类对象,然后才能创建派生类。
创建基类即默认调用Base()方法,在方法中调用callName()方法,由于派生类中存在此方法,则被调用的callName()方法是派生类中的方法,此时派生类还未构造,所以变量baseName的值为null
本题与内部类无关系,去掉内部类后代码如上,
1 | public class Base { |
编译时表现为父类特性,运行时表现为子类特性
执行Base b = new Sub();时由于多态 b编译时表现为Base类特性,运行时表现为Sub类特性,
Base b = new Sub();不管是哪种状态都会调用Base构造器执行callName()方法;
执行方法时,由于多台表现为子类特性,所以会先在子类是否有callName();如果有就执行,没有再去父类寻找
现在,子类有这个方法,所以执行子类重写的方法。而此时子类尚未初始化(执行完父类构造器后才会开始执行子类构造器),
优先执行子类重写的方法
向上转型加载顺序
本题考查知识点是多态(上转型)以及类的先后加载顺序
上转型 类似 Father father = new Son();
1:父类中的静态代码块
2:子类中的静态代码块
3:父类中构造方法
4:子类当中的构造方法
下面来简单分析一下加载顺序
当执行到Base b =newSub()时,本题的加载顺序是:
加载父类Base类中的构造方法Base()进而调用callName()(因为子类把父类的这个方法给覆盖了,所以此方法执行的是子类中的)
因为子类中的baseName变量还没进行初始化,故为null
解题要点:
1、静态内部类是不依赖于外部类的,静态内部类中只能访问外部类的静态成员(变量和方法),此处的内部类没有意义,静态非静态,只是在构造内部类对象时写法不同,但程序执行没有差异;
2、继承关系类的加载顺序(不考虑静态属性和静态代码的情况下):初始化父类的非静态成员属性或非静态代码块–>执行父类的构造函数–>初始化子类的非静态成员属性或非静态代码块–>执行子类的构造函数;本题中首先执行父类的 private String baseName = “base”;,然后执行父类的构造函数;执行过程中调用callName()方法;
3、多态:父类引用指向子类对象,父类引用b指向了子类对象new
Sub();多态中,实际执行时如果子类重写了父类的方法,则执行子类的方法;
4、根据多态的原则,再执行父类的构造方法中调用callName方法,实际调用的是子类的callName方法,子类的callName方法输出的是属性baseName的值,可是这时子类的baseName属性还没有被初始化,因为此时仍处在父类构造函数执行过程中。
多态 编译看左 运行看右
Base b = new Sub(),因为是多态,遵循着编译看左运行看右,所以首先调用Base的构造方法,
1 | public Base () {callName();} |
调试一下就可以很清楚的看到执行步骤,当执行父类的callName方法时,直接跳到子类的输出 System.out.println(baseName),此时子类还没有初始化,所以是null
考点9:线程安全的集合
线程安全的map在JDK 1.5及其更高版本环境 有哪几种方法可以实现?
- A
Map map = new HashMap() - B
Map map = new TreeMap() - C
Map map = new ConcurrentHashMap(); - D
Map map = Collections.synchronizedMap(new HashMap());
解析
显示答案/隐藏答案
正确答案: CD答案 : C D
- HashMap,TreeMap 未进行同步考虑,是线程不安全的。
- HashTable 和 ConcurrentHashMap 都是线程安全的。区别在于他们对加锁的范围不同,HashTable
对整张Hash表进行加锁,而ConcurrentHashMap将Hash表分为16桶(segment),每次只对需要的桶进行加锁。 - Collections 类提供了synchronizedXxx()方法,可以将指定的集合包装成线程同步的集合。比如,
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Hashtable线程安全效率低
HashMap不是线程安全的; Hashtable线程安全,但效率低,因为是Hashtable是使用synchronized的,所有线程竞争同一把锁;
ConcurrentHashMap线程安全效率高
ConcurrentHashMap不仅线程安全而且效率高,因为它包含一个segment数组,将数据分段存储,给每一段数据配一把锁,也就是所谓的锁分段技术
为什么HashMap不是线程安全的?
1、如果多个线程同时使用put方法添加元素,而且假设正好存在两个put的key发生了碰撞(根据hash值计算的bucket一样),那么根据HashMap的实现,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。
2、如果多个线程同时检测到元素个数超过 数组大小*loadFactor,这样就会发生多个线程同时对Node数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。
hashMap实现线程安全:
1 | //1、 |
考点10:CMS垃圾回收器
CMS垃圾回收器在那些阶段是没用用户线程参与的
- A 初始标记
- B 并发标记
- C 重新标记
- D 并发清理
解析
显示答案/隐藏答案
正确答案: ACCMS
CMS全称Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器,对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
CMS的基础算法是:标记—清除。
它的过程可以分为以下6个步骤:
- 初始标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)

- 初始标记:在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的”根对象”开始,只扫描到能够和”根对象”直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
- 并发标记:这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
- 并发预清理:并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段”重新标记”的工作,因为下一个阶段会Stop The World。
- 重新标记:这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从”根对象”开始向下追溯,并处理对象关联。
- 并发清理:清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
- 并发重置:这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
CMS不会整理、压缩堆空间,这样就带来一个问题:经过CMS收集的堆会产生空间碎片,CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。 为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。;而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切 换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。
B.并发标记 和 D.并发清理 这两个阶段是有用户线程参与的,所以答案选A和C。