JSP基础语法
JSP注释
JSP页面中共有三种注释
- HTML注释
<!--html注释-->,HTML注释在客户端(浏览器)是可以看到的。 - JSP注释
<%--JSP注释--%>,JSP注释在客户端不可见。注意了不要和html注释混淆<%!--JSP注释--%>这样写是不对的。 - JSP脚本注释(Java注释),JSP脚本中写的是Java代码,用到的注释也就是Java的注释,有:
- 单行注释:
//, - 多行注释:
/**/, - 文档注释
/** */ - JSP脚本注释同样在客户端不可见。
- 单行注释:
- 动态注释:,在html注释中写入jsp表达式,由于HIML注释对JSP嵌入的代码不起作用,因此可以利用它们的组合构成动态的HTML注释文本,例如:
1
<!-- <%= new Date0)%> -->
实例
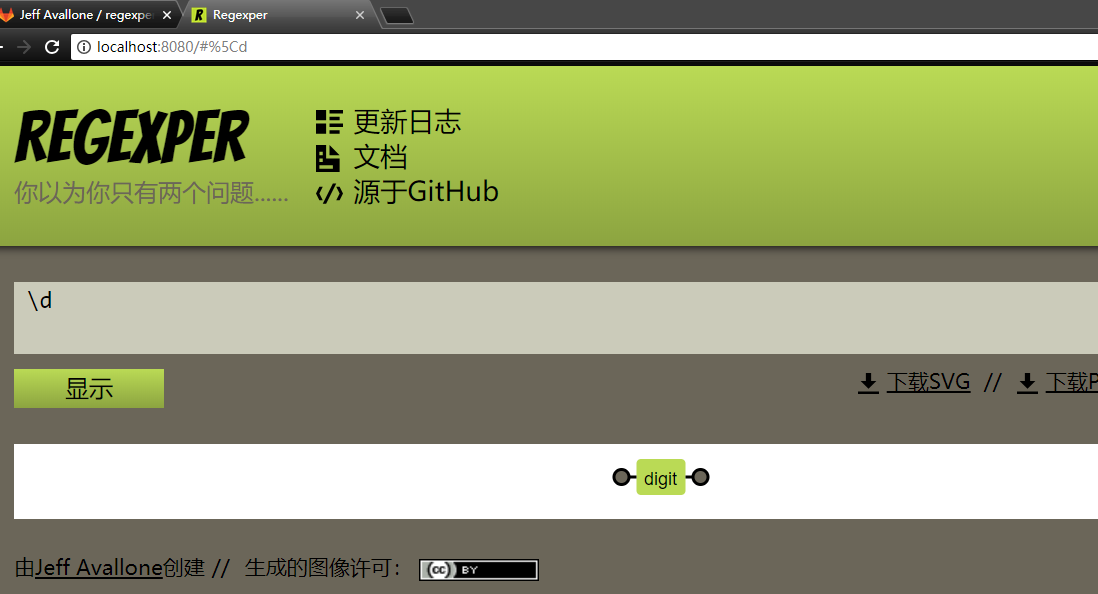
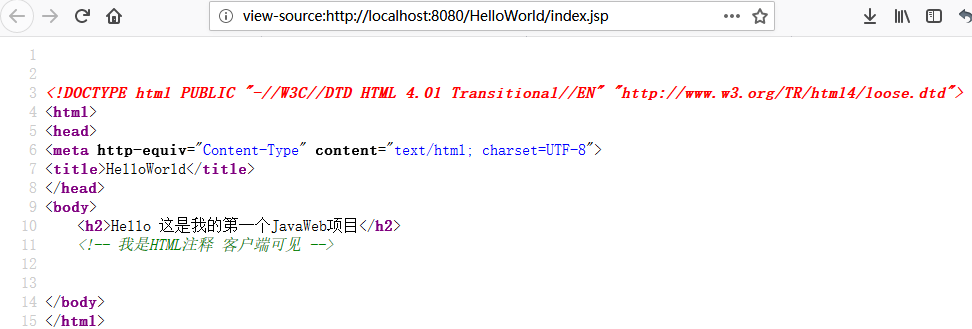
在index.jsp写输入下面的注释:然后打开浏览器查看index.jsp源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<%@ page language="java" import="java.util.*" contentType="text/html; charset=utf-8" %>
<%-- <%@ page language="java" import="java.util.*" contentType="text/html; charset=ISO-8859-1" %> --%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>HelloWorld</title>
</head>
<body>
<h2>Hello 这是我的第一个JavaWeb项目</h2>
<!-- 我是HTML注释 客户端可见 -->
<%-- 我是JSP注释 客户端不可见--%>
<%
//单行注释 客户端不可见
/*
多行注释 客户端不可见
*/
%>
</body>
</html>![]()
可以发现我们可以看到HTML注释,但是是看不到JSP注释和JSP脚本注释的.
英文
| 单词 | 读音 |
|---|---|
| annotation |  |
JSP页面生命周期
JSP生命周期就是从创建到销毁的整个过程
- 编译阶段:
- servlet容器编译servlet源文件,生成servlet类
- 初始化阶段:
- 加载与JSP对应的servlet类,创建其实例,并调用它的初始化方法
- 执行阶段:
- 调用与JSP对应的servlet实例的服务方法
- 销毁阶段:
- 调用与JSP对应的servlet实例的销毁方法,然后销毁servlet实例
JSP编译
当浏览器请求JSP页面时,JSP引擎会首先去检查是否需要编译这个文件。如果这个文件没有被编译过,或者在上次编译后被更改过,则编译这个JSP文件。
编译的过程包括三个步骤:
- 解析JSP文件。
- 将JSP文件转为servlet。
- 编译servlet。
JSP初始化
容器载入JSP文件后,它会在为请求提供任何服务前调用jspInit()方法。如果您需要执行自定义的JSP初始化任务,复写jspInit()方法就行了,就像下面这样:
1 | public void jspInit(){ |
一般来讲程序只初始化一次,通常情况下您可以在jspInit()方法中初始化数据库连接、打开文件和创建查询表。
JSP执行
这一阶段描述了JSP生命周期中一切与请求相关的交互行为,直到被销毁。
当JSP网页完成初始化后,JSP引擎将会调用_jspService()方法。
_jspService()方法需要一个HttpServletRequest对象和一个HttpServletResponse对象作为它的参数,就像下面这样:
1 | void _jspService(HttpServletRequest request, |
_jspService()方法在每个request中被调用一次,并且负责产生与之相对应的response,并且它还负责产生所有7个HTTP方法的回应,比如GET、POST、DELETE等等。
_jspService()方法被调用来处理客户端的请求。对每一个请求,JSP引擎创建一个新的线程来处理该请求。如果有多个客户端同时请求该JSP文件,则JSP引擎会创建多个线程。每个客户端请求对应一个线程。以多线程方式执行可以大大降低对系统的资源需求,提高系统的并发量及响应时间。但也要注意多线程的编程带来的同步问题,由于该 Servlet始终驻于内存,所以响应是非常快的。
JSP清理
JSP生命周期的销毁阶段描述了当一个JSP网页从容器中被移除时所发生的一切。
jspDestroy()方法在JSP中等价于servlet中的销毁方法。当您需要执行任何清理工作时复写jspDestroy()方法,比如释放数据库连接或者关闭文件夹等等。
jspDestroy()方法的格式如下:
1 | public void jspDestroy() |
实例
参考链接
http://www.runoob.com/jsp/jsp-life-cycle.html
https://www.cnblogs.com/x_wukong/p/3646848.html