/** comment for class */ publicclassTest { /** comment for a attribute */ int number; /** comment for a method */ publicvoidmyMethod() { ...... } ...... }
/** * Returns the {@code char} value at the * specified index. An index ranges from {@code 0} to * {@code length() - 1}. The first {@code char} value of the sequence * is at index {@code 0}, the next at index {@code 1}, * and so on, as for array indexing. * * <p>If the {@code char} value specified by the index is a * <a href="Character.html#unicode">surrogate</a>, the surrogate * value is returned. * * @param index the index of the {@code char} value. * @return the {@code char} value at the specified index of this string. * The first {@code char} value is at index {@code 0}. * @exception IndexOutOfBoundsException if the {@code index} * argument is negative or not less than the length of this * string. */ publiccharcharAt(int index) { if ((index < 0) || (index >= value.length)) { thrownewStringIndexOutOfBoundsException(index); } return value[index]; }
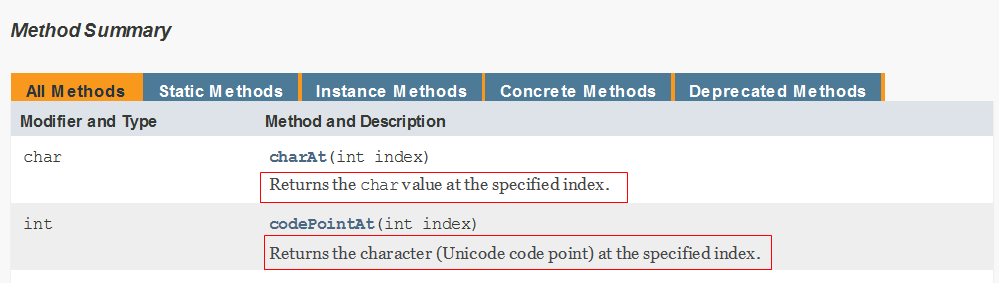
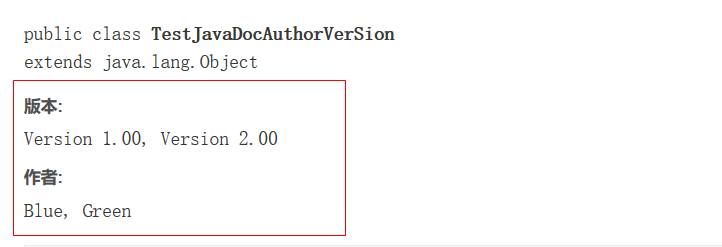
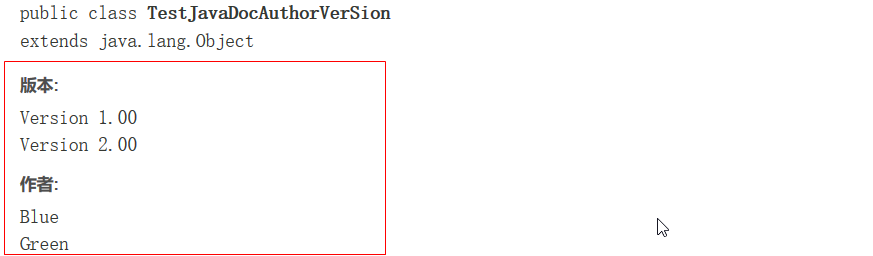
第一部分 简述
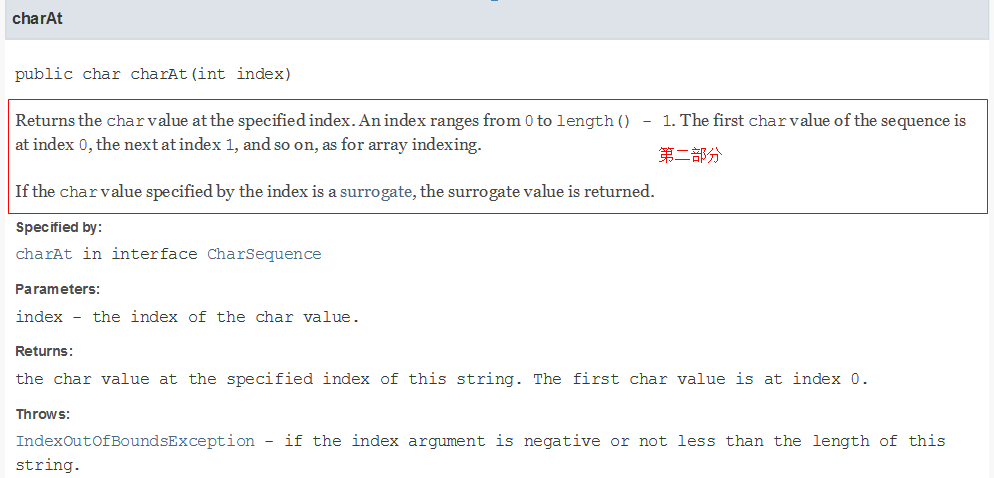
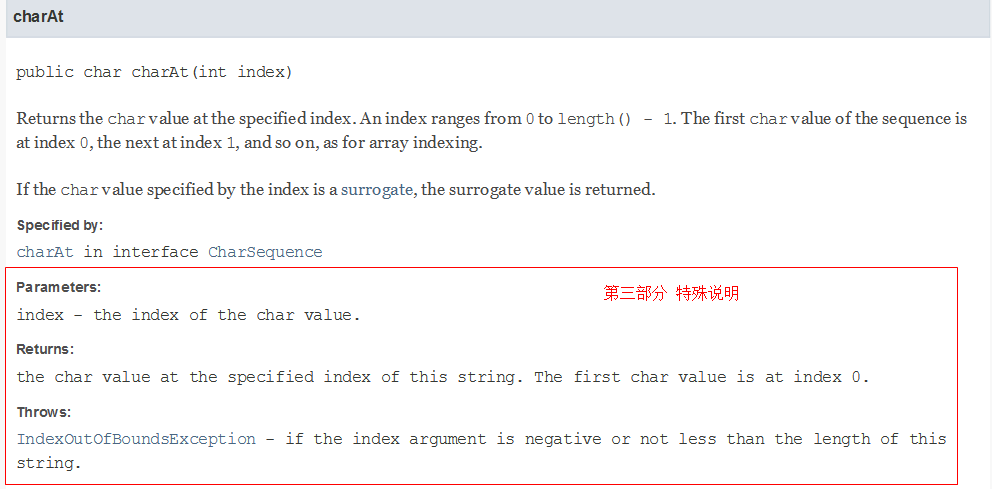
第一部分是简述。 文档中,对于属性和方法都是先有一个列表, 然后才在后面一个一个的详细的说明。 列表中属性名或者方法名后面那段说明就是简述。 如下图中被红框框选的部分: 简述部分写在一段文档注释的最前面,第一个点号(.) 之前 ( 包括点号 )。 换句话说,就是用第一个点号之前是简述,之后是第二部分和第三部分。如上例中的 “Returns the {@code char} value at the specified index.”。
/** * Returns the {@code char} value at the * specified index. An index ranges from {@code 0} to * {@code length() - 1}. The first {@code char} value of the sequence * is at index {@code 0}, the next at index {@code 1}, * and so on, as for array indexing. * * <p>If the {@code char} value specified by the index is a * <a href="Character.html#unicode">surrogate</a>, the surrogate * value is returned. *
* @param index the index of the {@codechar} value. * @return the {@codechar} value at the specified index of this string. * The first {@codechar} value is at index {@code0}. * @exception IndexOutOfBoundsException if the {@code index} * argument is negative or not less than the length of this * string.
@echo off setlocal enabledelayedexpansion set remain=%path% echo %remain% echo. ::待查找字符串 set toFind=D:\dev\workspace\MarkdownTools :loop for /f "tokens=1* delims=;" %%a in ("%remain%") do ( if "%toFind%"=="%%a" (echo 找到:%%a) rem 将截取剩下的部分赋给变量remain,其实这里可以使用延迟变量开关 set remain=%%b ) ::如果还有剩余,则继续分割 if defined remain goto :loop
pause
运行结果:
1 2 3 4 5 6 7
D:\dev\workspace\MarkdownTools;D:\dev\workspace\HexoTools\runable;D:\dev\workspace\BaiduTranslatorPronunciationGenerator\runable;C:\Windows;C:\windows\sy stem32;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;C:\Windows\System32\OpenSSH\;D:\快捷方式;D:\dev\java\jdk1.8.0_91\bin;F:\Progr am Files\nodejs\node_global;F:\Program Files\nodejs\;F:\Program Files\Git\bin;D:\dev\apache-maven-3.5.4\bin;C:\Program Files\Microsoft VS Code\bin;D:\Min GW\bin;D:\dev\apache-tomcat-8.5.35\bin;D:\dev\java\my\runable\openwith;D:\GitHub\latex;F:\texlive\2018\texlive\2018\bin\win32;D:\GitHub\MD;
@echo off ::定义一个以分号作为分隔的字符串 set str=AAA;BBB;CCC;DDD;EEE;FFF ::str的副本 set remain=%str% :loop for /f "tokens=1* delims=;" %%ain ("%remain%") do ( ::输出第一个分段(令牌) echo%%a rem 将截取剩下的部分赋给变量remain,其实这里可以使用延迟变量开关 set remain=%%b ) ::如果还有剩余,则继续分割 ifdefined remain goto :loop pause
@echo off setlocal enabledelayedexpansion ::定义一个以分号作为分隔的字符串 set str=%path% ::str的副本 set remain=%str% :loop for /f "tokens=1* delims=;" %%ain ("%remain%") do ( ::输出第一个分段(令牌) echo%%a rem 将截取剩下的部分赋给变量remain,其实这里可以使用延迟变量开关 set remain=%%b ) ::如果还有剩余,则继续分割 ifdefined remain goto :loop pause
@echo off setlocal enabledelayedexpansion ::定义一个以分号作为分隔的字符串 ::set str=AAA;BBB;CCC;DDD;EEE;FFF set str=%path% ::str的副本 set remain=%str% set toFind=D:\dev\workspace\MarkdownTools set isFind=false :loop for /f "tokens=1* delims=;" %%ain ("%remain%") do ( if "%toFind%"=="%%a" ( ::设置标记,以便后续使用 set isFind=true ::找到了就不找了 goto :finded ) rem 将截取剩下的部分赋给变量remain,其实这里可以使用延迟变量开关 set remain=%%b ) ::如果还有剩余,则继续分割 ifdefined remain goto :loop :finded echo%isFind% pause
for /f ["options"] %variable in (file-set) do command [command-parameters] for /f ["options"] %variable in ("string") do command [command-parameters] for /f ["options"] %variable in ('command') do command [command-parameters]