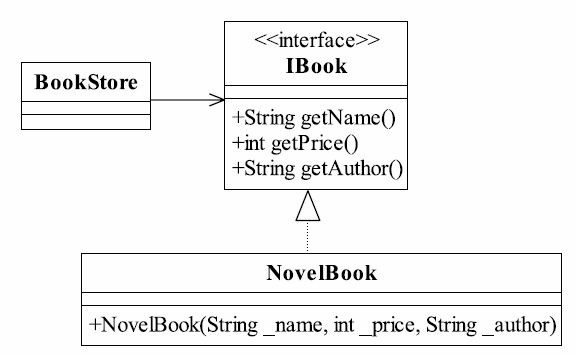
5.2 我的知识你知道得越少越好 迪米特法则对类的低耦合提出了明确的要求,其包含以下4层含义。
1. 只和朋友交流 迪米特法则还有一个英文解释是:Only talk to your immediate friends(只与直接的朋友通信。)什么叫做直接的朋友呢?每个对象都必然会与其他对象有耦合关系,两个对象之间的耦合就成为朋友关系,这种关系的类型有很多,例如组合、聚合、依赖等。下面我们将举例说明如何才能做到只与直接的朋友交流。
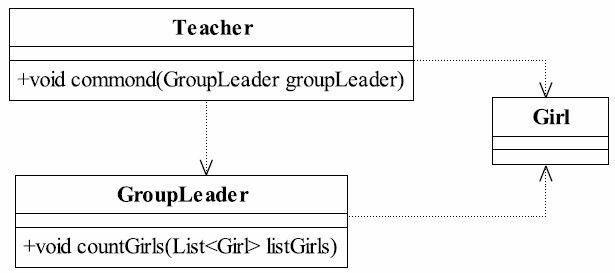
传说中有这样一个故事,老师想让体育委员确认一下全班女生来齐没有,就对他说:“你去把全班女生清一下。”体育委员没听清楚,就问道:“呀,……那亲哪个?”老师无语了,我们来看这个笑话怎么用程序来实现,类图如图5-1所示。
图5-1 老师要求清点女生类图
Teacher类的command方法负责发送命令给体育委员,命令他清点女生,其实现过程如代码清单5-1所示。
代码清单5-1 老师类
1 2 3 4 5 6 7 8 9 10 11 12 public class Teacher { public void command (GroupLeader groupLeader) { List listGirls = new ArrayList (); for (int i=0 ;i<20 ;i++){ listGirls.add(new Girl ()); } groupLeader.countGirls(listGirls); } }
老师只有一个方法command,先定义出所有的女生,然后发布命令给体育委员,去清点一下女生的数量。体育委员GroupLeader的实现过程如代码清单5-2所示。
代码清单5-2 体育委员类实现过程
1 2 3 4 5 6 public class GroupLeader { public void countGirls (List<Girl> listGirls) { System.out.println("女生数量是:" +listGirls.size()); } }
老师类和体育委员类都对女生类产生依赖,而且女生类不需要执行任何动作,因此定义一个空类,其实现过程如代码清单5-3所示。
代码清单5-3 女生类
故事中的三个角色都已经有了,再定义一个场景类来描述这个故事,其实现过程如代码清单5-4所示。
代码清单5-4 场景类
1 2 3 4 5 6 7 public class Client { public static void main (String[] args) { Teacher teacher= new Teacher (); teacher.command(new GroupLeader ()); } }
运行结果如下所示:
体育委员按照老师的要求对女生进行了清点,并得出了数量。我们回过头来思考一下这个程序有什么问题,首先确定Teacher类有几个朋友类,它仅有一个朋友类—— GroupLeader。为什么Girl不是朋友类呢?Teacher也对它产生了依赖关系呀!朋友类的定义是这样的:出现在成员变量、方法的输入输出参数中的类称为成员朋友类 ,而出现在方法体内部的类不属于朋友类,而Girl这个类就是出现在command方法体内,因此不属于Teacher类的朋友类。迪米特法则告诉我们一个类只和朋友类交流,但是我们刚刚定义的command方法却与Girl类有了交流,声明了一个List<Girls>动态数组,也就是与一个陌生的类Girl有了交流, 这样就破坏了Teacher的健壮性。方法是类的一个行为,类竟然不知道自己的行为与其他类产生依赖关系,这是不允许的,严重违反了迪米特法则。
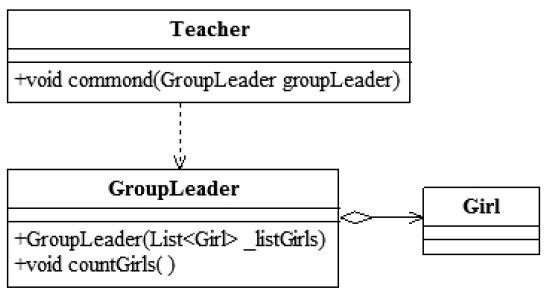
问题已经发现,我们修改一下程序,将类图稍作修改,如图5-2所示。
图5-2 修改后的类图
在类图中去掉Teacher对Girl类的依赖关系,修改后的Teacher类如代码清单5-5所示。
代码清单5-5 修改后的老师类
1 2 3 4 5 6 7 public class Teacher { public void command (GroupLeader groupLeader) { groupLeader.countGirls(); } }
修改后的GroupLeader类如代码清代5-6所示。
代码清单5-6 修改后的体育委员类
1 2 3 4 5 6 7 8 9 10 11 public class GroupLeader { private List<Girl> listGirls; public GroupLeader (List<Girl> _listGirls) { this .listGirls = _listGirls; } public void countGirls () { System.out.println("女生数量是:" +this .listGirls.size()); } }
在GroupLeader类中定义了一个构造函数,通过构造函数传递了依赖关系。同时,对场景类也进行了一些修改,如代码清单5-7所示。
代码清单5-7 修改后的场景类
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Client { public static void main (String[] args) { List<Girl> listGirls = new ArrayList <Girl>(); for (int i=0 ;i<20 ;i++){ listGirls.add(new Girl ()); } Teacher teacher= new Teacher (); teacher.command(new GroupLeader (listGirls)); } }
对程序进行了简单的修改,把Teacher中对List<Girl>的初始化移动到了场景类中,同时在GroupLeader中增加了对Girl的注入,避开了Teacher类对陌生类Girl的访问,降低了系统间的耦合,提高了系统的健壮性。
注意 一个类只和朋友交流,不与陌生类交流,不要出现getA().getB().getC().getD()这种情况(在一种极端的情况下允许出现这种访问,即每一个点号后面的返回类型都相同),类与类之间的关系是建立在类间的,而不是方法间,因此一个方法尽量不引入一个类中不存在的对象,当然,JDK API提供的类除外。
2. 朋友间也是有距离的 人和人之间是有距离的,太远关系逐渐疏远,最终形同陌路;太近就相互刺伤。对朋友关系描述最贴切的故事就是:两只刺猬取暖,太远取不到暖,太近刺伤了对方,必须保持一个既能取暖又不刺伤对方的距离。迪米特法则就是对这个距离进行描述,即使是朋友类之间也不能无话不说,无所不知。
我们在安装软件的时候,经常会有一个导向动作,第一步是确认是否安装,第二步确认License,再然后选择安装目录……这是一个典型的顺序执行动作,具体到程序中就是:调用一个或多个类,先执行第一个方法,然后是第二个方法,根据返回结果再来看是否可以调用第三个方法,或者第四个方法,等等,其类图如图5-3所示。
图5-3 软件安装过程类图
很简单的类图,实现软件安装的过程,其中first方法定义第一步做什么,second方法定义第二步做什么,third方法定义第三步做什么,其实现过程如代码清单5-8所示。
代码清单5-8 导向类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Wizard { private Random rand = new Random (System.currentTimeMillis()); public int first () { System.out.println("执行第一个方法..." ); return rand.nextInt(100 ); } public int second () { System.out.println("执行第二个方法..." ); return rand.nextInt(100 ); } public int third () { System.out.println("执行第三个方法..." ); return rand.nextInt(100 ); } }
在Wizard类中分别定义了三个步骤方法,每个步骤中都有相关的业务逻辑完成指定的任务,我们使用一个随机函数来代替业务执行的返回值。软件安装InstallSoftware类如代码清单5-9所示。
代码清单5-9 InstallSoftware类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class InstallSoftware { public void installWizard (Wizard wizard) { int first = wizard.first(); if (first>50 ){ int second = wizard.second(); if (second>50 ){ int third = wizard.third(); if (third >50 ){ wizard.first(); } } } } }
根据每个方法执行的结果决定是否继续执行下一个方法,模拟人工的选择操作。场景类如代码清单5-10所示。
代码清单5-10 场景类
1 2 3 4 5 6 public class Client { public static void main (String[] args) { InstallSoftware invoker = new InstallSoftware (); invoker.installWizard(new Wizard ()); } }
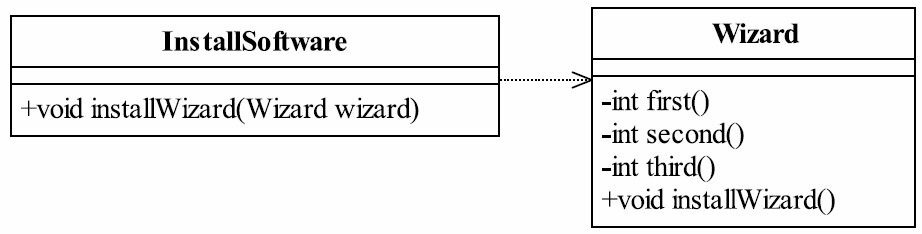
以上程序很简单,运行结果和随机数有关,每次的执行结果都不相同,需要读者自己运行并查看结果。程序虽然简单,但是隐藏的问题可不简单,思考一下程序有什么问题。 Wizard类把太多的方法暴露给InstallSoftware类,两者的朋友关系太亲密了,耦合关系变得异常牢固。如果要将Wizard类中的first方法返回值的类型由int改为boolean,就需要修改InstallSoftware类,从而把修改变更的风险扩散开了。因此,这样的耦合是极度不合适的,我们需要对设计进行重构,重构后的类图如图5-4所示。
图5-4 重构后的软件安装过程类图
在Wizard类中增加一个installWizard方法,对安装过程进行封装,同时把原有的三个public方法修改为private方法,如代码清单5-11所示。
代码清单5-11 修改后的导向类实现过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class Wizard { private Random rand = new Random (System.currentTimeMillis()); private int first () { System.out.println("执行第一个方法..." ); return rand.nextInt(100 ); } private int second () { System.out.println("执行第二个方法..." ); return rand.nextInt(100 ); } private int third () { System.out.println("执行第三个方法..." ); return rand.nextInt(100 ); } public void installWizard () { int first = this .first(); if (first>50 ){ int second = this .second(); if (second>50 ){ int third = this .third(); if (third >50 ){ this .first(); } } } } }
将三个步骤的访问权限修改为private,同时把InstallSoftware中的方法installWizad移动到Wizard方法中。通过这样的重构后,Wizard类就只对外公布了一个public方法,即使要修改first方法的返回值,影响的也仅仅只是Wizard本身,其他类不受影响,这显示了类的高内聚特性。
对InstallSoftware类进行少量的修改,如代码清单5-12所示。
代码清单5-12 修改后的InstallSoftware类
1 2 3 4 5 6 public class InstallSoftware { public void installWizard (Wizard wizard) { wizard.installWizard(); } }
场景类Client没有任何改变,如代码清单5-10所示。通过进行重构,类间的耦合关系变弱了,结构也清晰了,变更引起的风险也变小了。
一个类公开的public属性或方法越多,修改时涉及的面也就越大,变更引起的风险扩散也就越大 。因此,为了保持朋友类间的距离,在设计时需要反复衡量:是否还可以再减少public方法和属性,是否可以修改为private、package-private(包类型,在类、方法、变量前不加访问权限,则默认为包类型)、protected等访问权限,是否可以加上final关键字等 。
注意 迪米特法则要求类“羞涩”一点,尽量不要对外公布太多的public方法和非静态的public变量,尽量内敛,多使用private、package-private、protected等访问权限 。
3. 是自己的就是自己的 在实际应用中经常会出现这样一个方法:放在本类中也可以,放在其他类中也没有错, 那怎么去衡量呢?你可以坚持这样一个原则:如果一个方法放在本类中,既不增加类间关系,也对本类不产生负面影响,那就放置在本类中。
4. 谨慎使用Serializable 在实际应用中,这个问题是很少出现的,即使出现也会立即被发现并得到解决。是怎么回事呢?举个例子来说,在一个项目中使用RMI(Remote Method Invocation,远程方法调用)方式传递一个VO(Value Object,值对象),这个对象就必须实现Serializable接口(仅仅是一个标志性接口,不需要实现具体的方法),也就是把需要网络传输的对象进行序列化,否则就会出现NotSerializableException异常。突然有一天,客户端的VO修改了一个属性的访问权限,从private变更为public,访问权限扩大了,如果服务器上没有做出相应的变更,就会报序列化失败,就这么简单。但是这个问题的产生应该属于项目管理范畴,一个类或接口在客户端已经变更了,而服务器端却没有同步更新,难道不是项目管理的失职吗?