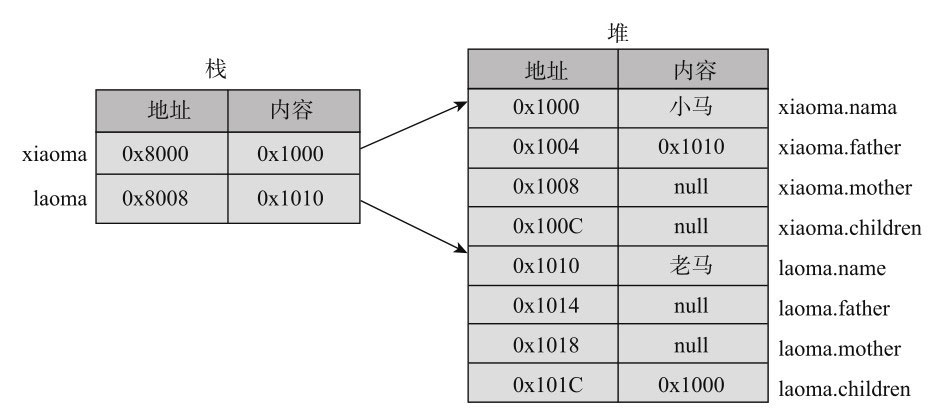
2.3 字符的编码与乱码 本节讨论与语言无关的字符和文本的编码以及乱码。我们在处理文件、浏览网页、编写程序时,时不时会碰到乱码的情况。乱码几乎总是令人心烦,让人困惑,通过阅读本节,相信你就可以自信从容地面对乱码,进而恢复乱码了。
编码和乱码听起来比较复杂,但其实并不复杂,请耐心阅读,让我们逐步来探讨。我们先介绍各种编码,然后介绍编码转换,分析乱码出现的原因,最后介绍如何从乱码中恢复。编码有两大类:一类是非Unicode编码;另一类是Unicode编码。我们先介绍非Unicode编码。
2.3.1 常见非Unicode编码 下面我们看一些主要的非Unicode编码,包括ASCII、ISO 8859-1、Windows-1252、GB2312、GBK、GB18030和Big5。
1. ASCII 世界上虽然有各种各样的字符,但计算机发明之初没有考虑那么多,基本上只考虑了美国的需求。美国大概只需要128个字符,所以就规定了128个字符的二进制表示方法。这个方法是一个标准,称为ASCII编码,全称是American StandardCode for InformationInterchange,即美国信息互换标准代码。
128个字符用7位刚好可以表示,计算机存储的最小单位是byte,即8位,ASCII码中最高位设置为0,用剩下的7位表示字符。这7位可以看作数字0~127, ASCII码规定了从0~127的每个数字代表什么含义。
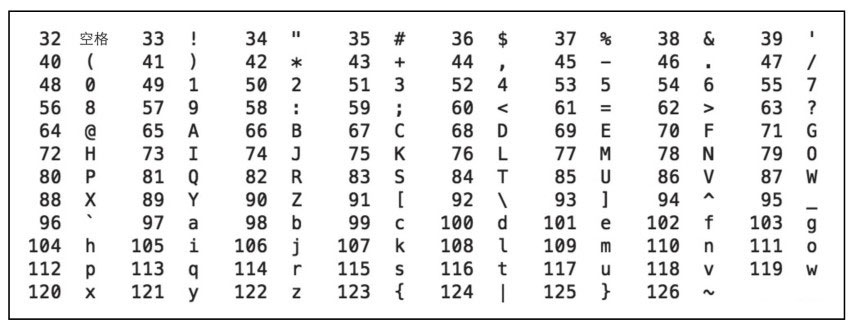
我们先来看数字32~126的含义,如图2-1所示,除了中文之外,我们平常用的字符基本都涵盖了,键盘上的字符大部分也都涵盖了。
图2-1 ASCII编码:可打印字符
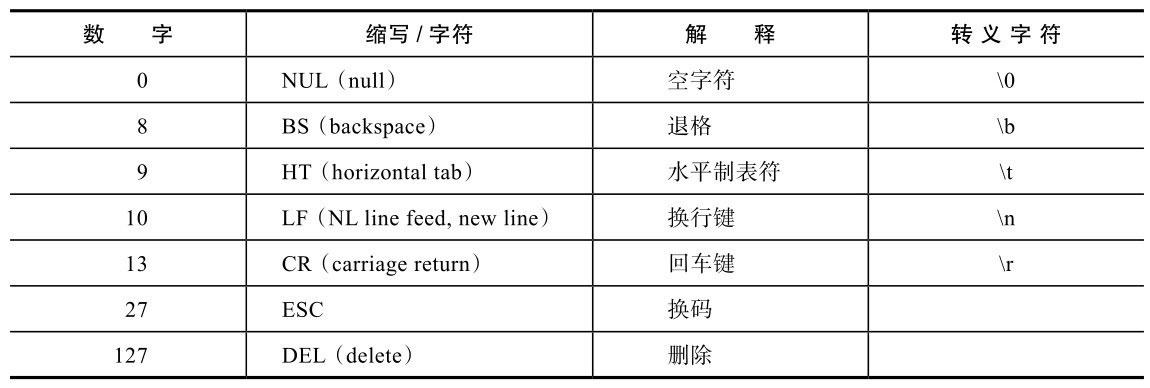
图2-1 ASCII编码:可打印字符数字32~126表示的字符都是可打印字符,0~31和127表示一些不可以打印的字符,这些字符一般用于控制目的,这些字符中大部分都是不常用的,表2-4列出了其中相对常用的字符。
表2-4 ASCII编码:常用不可打印字符
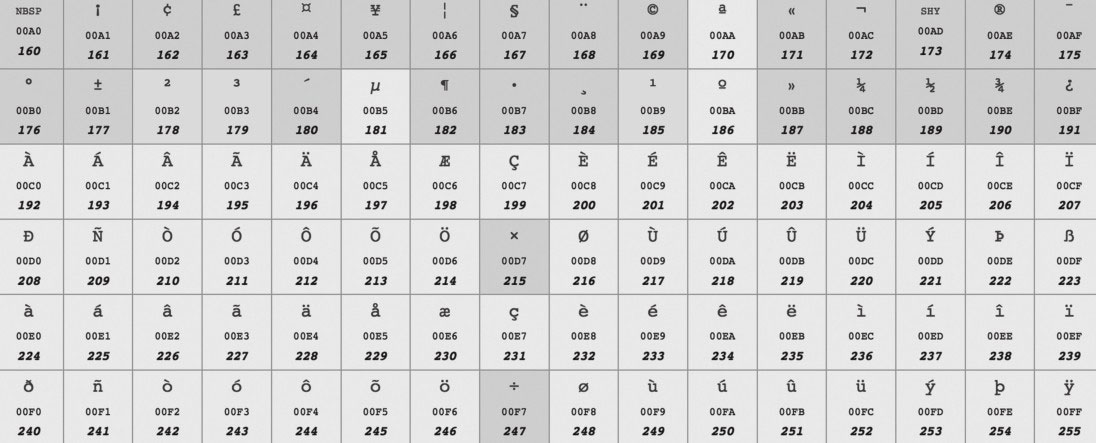
2. ISO 8859-1 ISO 8859-1又称Latin-1,它也是使用一个字节表示一个字符,其中0~127与ASCII一样,128~255规定了不同的含义。在128~255中,128~159表示一些控制字符,这些字符也不常用,就不介绍了。160~255表示一些西欧字符,如图2-2所示。
图2-2 ISO 8859-1
3. Windows-1252 ISO 8859-1虽然号称是标准,用于西欧国家,但它连欧元(€)这个符号都没有,因为欧元比较晚,而标准比较早。实际中使用更为广泛的是Windows-1252编码,这个编码与ISO 8859-1基本是一样的,区别只在于数字128~159。Windows-1252使用其中的一些数字表示可打印字符,这些数字表示的含义如图2-3所示。
图2-3 Windows-1252编码:区别于ISO8859-1的部分
这个编码中加入了欧元符号以及一些其他常用的字符。基本上可以认为,ISO8859-1已被Windows-1252取代,在很多应用程序中,即使文件声明它采用的是ISO 8859-1编码,解析的时候依然被当作Windows-1252编码。
HTML5甚至明确规定,如果文件声明的是ISO 8859-1编码,它应该被看作Win-dows-1252编码。为什么要这样呢?因为大部分人搞不清楚ISO 8859-1和Windows-1252的区别,当他说ISO 8859-1的时候,其实他指的是Windows-1252,所以标准干脆就这么强制规定了。
4. GB2312 美国和西欧字符用一个字节就够了,但中文显然是不够的。中文第一个标准是GB2312。GB2312标准主要针对的是简体中文常见字符,包括约7000个汉字和一些罕用词和繁体字。
GB2312固定使用两个字节表示汉字,在这两个字节中,最高位都是1,如果是0,就认为是ASCII字符。在这两个字节中,其中高位字节范围是0xA1~0xF7,低位字节范围是0xA1~0xFE。
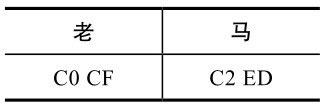
比如,“老马”的GB2312编码(十六进制表示)如表2-5所示。
表2-5 GB2312编码示例
5. GBK GBK建立在GB2312的基础上,向下兼容GB2312,也就是说,GB2312编码的字符和二进制表示,在GBK编码里是完全一样的。GBK增加了14 000多个汉字,共计约21 000个汉字,其中包括繁体字。
GBK同样使用固定的两个字节表示,其中高位字节范围是0x81~0xFE,低位字节范围是0x40~0x7E和0x80~0xFE。
需要注意的是,低位字节是从0x40(也就是64)开始的,也就是说,低位字节的最高位可能为0。那怎么知道它是汉字的一部分,还是一个ASCII字符呢?其实很简单,因为汉字是用固定两个字节表示的,在解析二进制流的时候,如果第一个字节的最高位为1,那么就将下一个字节读进来一起解析为一个汉字,而不用考虑它的最高位,解析完后,跳到第三个字节继续解析。
6. GB18030 GB18030向下兼容GBK,增加了55 000多个字符,共76 000多个字符,包括了很多少数民族字符,以及中日韩统一字符。
用两个字节已经表示不了GB18030中的所有字符,GB18030使用变长编码,有的字符是两个字节,有的是四个字节。在两字节编码中,字节表示范围与GBK一样。在四字节编码中,第一个字节的值为0x81~0xFE,第二个字节的值为0x30~0x39,第三个字节的值为0x81~0xFE,第四个字节的值为0x30~0x39。
解析二进制时,如何知道是两个字节还是4个字节表示一个字符呢?看第二个字节的范围,如果是0x30~0x39就是4个字节表示,因为两个字节编码中第二个字节都比这个大。
7. Big5 Big5是针对繁体中文的,广泛用于我国台湾地区和我国香港特别行政区等地。Big5包括13 000多个繁体字,和GB2312类似,一个字符同样固定使用两个字节表示。在这两个字节中,高位字节范围是0x81~0xFE,低位字节范围是0x40~0x7E和0xA1~0xFE。
8.编码汇总 我们简单汇总一下前面的内容。
ASCII码是基础,使用一个字节表示,最高位设为0,其他7位表示128个字符。其他编码都是兼容ASCII的,最高位使用1来进行区分。
西欧主要使用Windows-1252,使用一个字节,增加了额外128个字符。
我国内地的三个主要编码GB2312、GBK、GB18030有时间先后关系,表示的字符数越来越多,且后面的兼容前面的,GB2312和GBK都是用两个字节表示,而GB18030则使用两个或四个字节表示。
我国香港特别行政区和我国台湾地区的主要编码是Big5。
如果文本里的字符都是ASCII码字符,那么采用以上所说的任一编码方式都是一样的。
但如果有高位为1的字符,除了GB2312、GBK、GB18030外,其他编码都是不兼容的。比如,Windows-1252和中文的各种编码是不兼容的,即使Big5和GB18030都能表示繁体字,其表示方式也是不一样的,而这就会出现所谓的乱码,具体我们稍后介绍。
2.3.2 Unicode编码 以上我们介绍了中文和西欧的字符与编码,但世界上还有很多其他国家的字符,每个国家的各种计算机厂商都对自己常用的字符进行编码,在编码的时候基本忽略了其他国家的字符和编码,甚至忽略了同一国家的其他计算机厂商,这样造成的结果就是,出现了太多的编码,且互相不兼容。
世界上所有的字符能不能统一编码呢?可以,这就是Unicode。
Unicode 做了一件事,就是给世界上所有字符都分配了一个唯一的数字编号,这个编号范围从0x000000~0x10FFFF,包括110多万。但大部分常用字符都在0x0000~0xFFFF之间,即65 536个数字之内。每个字符都有一个Unicode编号,这个编号一般写成十六进制,在前面加U+。大部分中文的编号范围为U+4E00~U+9FFF,例如,“马”的Unicode是U+9A6C。
简单理解,Unicode主要做了这么一件事,就是给所有字符分配了唯一数字编号。它并没有规定这个编号怎么对应到二进制表示,这是与上面介绍的其他编码不同的,其他编码都既规定了能表示哪些字符,又规定了每个字符对应的二进制是什么,而Unicode本身只规定了每个字符的数字编号是多少。
那编号怎么对应到二进制表示呢?有多种方案,主要有UTF-32、UTF-16和UTF-8。
1. UTF-32 这个最简单,就是字符编号的整数二进制形式,4个字节。
但有个细节,就是字节的排列顺序,如果第一个字节是整数二进制中的最高位,最后一个字节是整数二进制中的最低位,那这种字节序就叫“大端”(Big Endian,BE),否则,就叫“小端”(Little Endian, LE)。对应的编码方式分别是UTF-32BE和UTF-32LE。
可以看出,每个字符都用4个字节表示,非常浪费空间,实际采用的也比较少。
2. UTF-16 UTF-16使用变长字节表示:
1)对于编号在U+0000~U+FFFF的字符(常用字符集),直接用两个字节表示。需要说明的是,U+D800~U+DBFF的编号其实是没有定义的。
2)字符值在U+10000~U+10FFFF的字符(也叫做增补字符集),需要用4个字节表示。前两个字节叫高代理项,范围是U+D800~U+DBFF;后两个字节叫低代理项,范围是U+DC00~U+DFFF。数字编号和这个二进制表示之间有一个转换算法,本书就不介绍了。
区分是两个字节还是4个字节表示一个字符就看前两个字节的编号范围,如果是U+D800~U+DBFF,就是4个字节,否则就是两个字节。
UTF-16也有和UTF-32一样的字节序问题,如果高位存放在前面就叫大端(BE),编码就叫UTF-16BE,否则就叫小端,编码就叫UTF-16LE。
UTF-16常用于系统内部编码,UTF-16比UTF-32节省了很多空间,但是任何一个字符都至少需要两个字节表示,对于美国和西欧国家而言,还是很浪费的。
3. UTF-8 UTF-8使用变长字节表示,每个字符使用的字节个数与其Unicode编号的大小有关,编号小的使用的字节就少,编号大的使用的字节就多,使用的字节个数为1~4不等。
具体来说,各个Unicode编号范围对应的二进制格式如表2-6所示。
表2-6 UTF-8编码的编号范围与对应的二进制格式
小于128的,编码与ASCII码一样,最高位为0。其他编号的第一个字节有特殊含义,最高位有几个连续的1就表示用几个字节表示,而其他字节都以10开头。
对于一个Unicode编号,具体怎么编码呢?首先将其看作整数,转化为二进制形式(去掉高位的0),然后将二进制位从右向左依次填入对应的二进制格式x中,填完后,如果对应的二进制格式还有没填的x,则设为0。
我们来看个例子,“马”的Unicode编号是0x9A6C,整数编号是39 532,其对应的UTF-8二进制格式是:
1 1110xxxx 10xxxxxx 10xxxxxx
整数编号39 532的二进制格式是:
将这个二进制位从右到左依次填入二进制格式中,结果就是其UTF-8编码:
1 11101001 10101001 10101100
十六进制表示为0xE9A9AC。
和UTF-32/UTF-16不同,UTF-8是兼容ASCII的,对大部分中文而言,一个中文字符需要用三个字节表示。
4. Unicode编码小结 Unicode给世界上所有字符都规定了一个统一的编号,编号范围达到110多万,但大部分字符都在65 536以内。Unicode本身没有规定怎么把这个编号对应到二进制形式。
UTF-32/UTF-16/UTF-8都在做一件事,就是把Unicode编号对应到二进制形式,其对应方法不同而已。UTF-32使用4个字节,UTF-16大部分是两个字节,少部分是4个字节,它们都不兼容ASCII编码,都有字节顺序的问题。UTF-8使用1~4个字节表示,兼容ASCII编码,英文字符使用1个字节,中文字符大多用3个字节。
2.3.3 编码转换 有了Unicode之后,每一个字符就有了多种不兼容的编码方式,比如说“马”这个字符,它的各种编码方式对应的十六进制如表2-7所示。
表2-7 字符“马”多种编码方式
编码转换的具体过程可以是:一个字符从A编码转到B编码,先找到字符的A编码格式,通过A的映射表找到其Unicode编号,然后通过Unicode编号再查B的映射表,找到字符的B编码格式。
举例来说,“马”从GB18030转到UTF-8,先查GB18030->Unicode编号表,得到其编号是9A 6C,然后查Uncode编号->UTF-8表,得到其UTF-8编码:E9 A9AC。
编码转换改变了字符的二进制内容,但并没有改变字符看上去的样子。
2.3.4 乱码的原因 理解了编码,我们来看乱码。乱码有两种常见原因:一种比较简单,就是简单的解析错误;另外一种比较复杂,在错误解析的基础上进行了编码转换。我们分别介绍。
1.解析错误 看个简单的例子。一个法国人采用Windows-1252编码写了个文件,发送给了一个中国人,中国人使用GB18030来解析这个字符,看到的可能就是乱码。比如,法国人发送的是Pékin, Windows-1252的二进制(采用十六进制)是50 E9 6B 696E,第二个字节E9对应é,其他都是ASCII码,中国人收到的也是这个二进制,但是他把它看成了GB18030编码,GB18030中E9 6B对应的是字符“閗”,于是他看到的就是“P閗in”,这看来就是一个乱码。
反之也是一样的,一个GB18030编码的文件如果被看作Windows-1252也是乱码。
这种情况下,之所以看起来是乱码,是因为看待或者说解析数据的方式错了。只要使用正确的编码方式进行解读就可以纠正了。很多文件编辑器,如EditPlus、NotePad++、UltraEdit都有切换查看编码方式的功能,浏览器也都有切换查看编码方式的功能,如Fire-fox,在菜单“查看”→“文字编码”中即可找到该功能。
切换查看编码的方式并没有改变数据的二进制本身,而只是改变了解析数据的方式,从而改变了数据看起来的样子,这与前面提到的编码转换正好相反。很多时候,做这样一个编码查看方式的切换就可以解决乱码的问题,但有的时候这样是不够的。
2.错误的解析和编码转换 如果怎么改变查看方式都不对,那很有可能就不仅仅是解析二进制的方式不对,而是文本在错误解析的基础上还进行了编码转换。我们举个例子来说明:
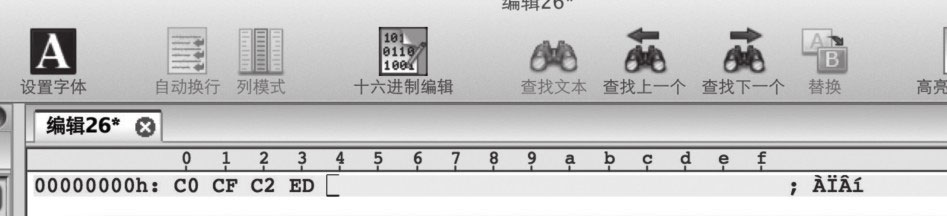
1)两个字“老马”,本来的编码格式是GB18030,编码(十六进制)是C0 CF C2ED。
这种情况是乱码产生的主要原因。
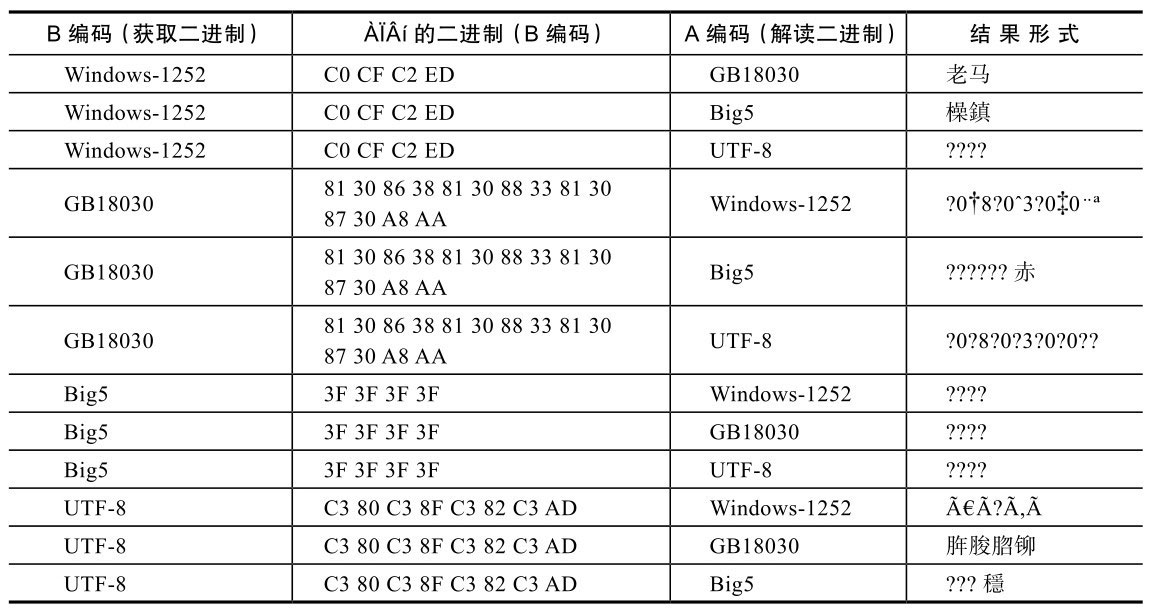
这种情况其实很常见,计算机程序为了便于统一处理,经常会将所有编码转换为一种方式,比如UTF-8,在转换的时候,需要知道原来的编码是什么,但可能会搞错,而一旦搞错并进行了转换,就会出现这种乱码。这种情况下,无论怎么切换查看编码方式都是不行的,如表2-8所示。
表2-8 用不同编码方式查看错误转换后的二进制
那有没有办法恢复呢?如果有,怎么恢复呢?
2.3.5 从乱码中恢复 “乱”主要是因为发生了一次错误的编码转换,所谓恢复,是指要恢复两个关键信息:一个是原来的二进制编码方式A;另一个是错误解读的编码方式B。
恢复的基本思路是尝试进行逆向操作,假定按一种编码转换方式B获取乱码的二进制格式,然后再假定一种编码解读方式A解读这个二进制,查看其看上去的形式,这要尝试多种编码,如果能找到看着正常的字符形式,应该就可以恢复。
这听上去可能比较抽象,我们举个例子来说明,假定乱码形式是“ÀÏÂí”,尝试多种B和A来看字符形式。我们先使用编辑器,以UltraEdit为例,然后使用Java编程来看。
1.使用UltraEdit UltraEdit支持编码转换和切换查看编码方式,也支持文件的二进制显示和编辑,所以我们以UltraEdit为例,其他一些编辑器可能也有类似功能。
新建一个UTF-8编码的文件,复制“ÀÏÂí”到文件中。使用编码转换,转换到Win-dows-1252编码,执行“文件”→“转换到”→“西欧”→WIN-1252命令。
转换完后,打开十六进制编辑,查看其二进制形式,如图2-4所示。
图2-4 使用UltraEdit查看二进制
可以看出,其形式还是“ÀÏÂí”,但二进制格式变成了 C0 CF C2 ED。这个过程相当于假设B是Windows-1252。这个时候,再按照多种编码格式查看这个二进制,在UltraEdit中,关闭十六进制编辑,切换查看编码方式为GB18030,执行“视图”→“查看方式(文件编码)”→“东亚语言”→GB18030命令,切换完后,同样的二进制神奇地变为了正确的字符形式“老马”,打开十六进制编辑器,可以看出二进制还是C0 CF C2 ED,这个GB18030相当于假设A是GB18030。
这个例子我们碰巧第一次就猜对了。实际中,可能要做多次尝试,过程是类似的,先进行编码转换(使用B编码),然后使用不同编码方式查看(使用A编码),如果能找到看上去对的形式,就恢复了。表2-9列出了主要的B编码格式、对应的二进制,以及按A编码解读的各种形式。
表2-9 尝试不同编码方式进行恢复
2.使用Java 下面我们来看如何使用Java恢复乱码。关于使用Java我们还有很多知识没有介绍,为了完整性起见,本节一并列出相关代码,初学者不明白的可以暂时略过。Java中处理字符串的类有String, String中有我们需要的两个重要方法。
将A看作GB18030,将B看作Windows-1252,进行恢复的Java代码如下所示:
1 2 3 String str = "ÀÏÂí" ;String newStr = new String (str.getBytes("windows-1252" ), "GB18030" );System.out.println(newStr);
先按照B编码(Windows-1252)获取字符串的二进制,然后按A编码(GB18030)解读这个二进制,得到一个新的字符串,然后输出这个字符串的形式,输出为“老马”。
同样,一次碰巧就对了,实际中,我们可以写一个循环,测试不同的A/B编码中的结果形式,如代码清单2-1所示。
代码清单2-1 恢复乱码的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void recover (String str) throws UnsupportedEncodingException{ String[] charsets = new String []{ "windows-1252" , "GB18030" , "Big5" , "UTF-8" }; for (int i=0 ; i<charsets.length; i++){ for (int j=0 ; j<charsets.length; j++){ if (i! =j){ String s = new String (str.getBytes(charsets[i]), charsets[j]); System.out.println("---- 原来编码(A)假设是: " +charsets[j]+", 被错误解读为了(B): " +charsets[i]); System.out.println(s); System.out.println(); } } } }
以上代码使用不同的编码格式进行测试,如果输出有正确的,那么就可以恢复。
可以看出,恢复的尝试需要进行很多次,上面例子尝试了常见编码GB18030、Windows 1252、Big5、UTF-8共12种组合。这4种编码是常见编码,在大部分实际应用中应该够了。如果有其他编码,可以增加一些尝试。
不是所有的乱码形式都是可以恢复的,如果形式中有很多不能识别的字符(如?),则很难恢复。另外,如果乱码是由于进行了多次解析和转换错误造成的,也很难恢复。