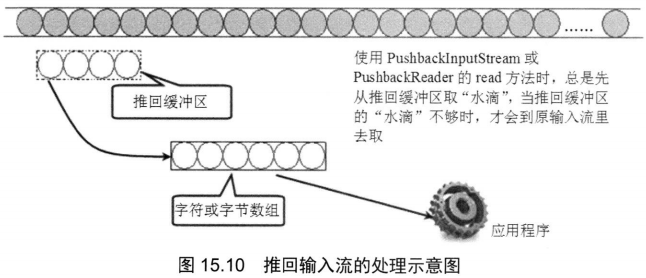
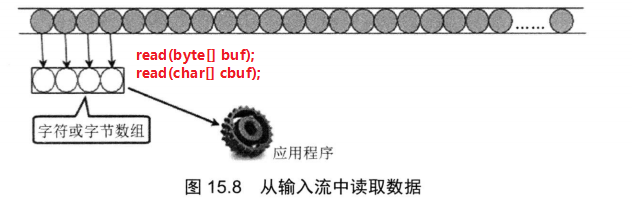
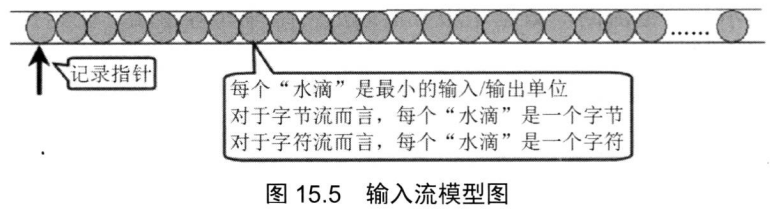
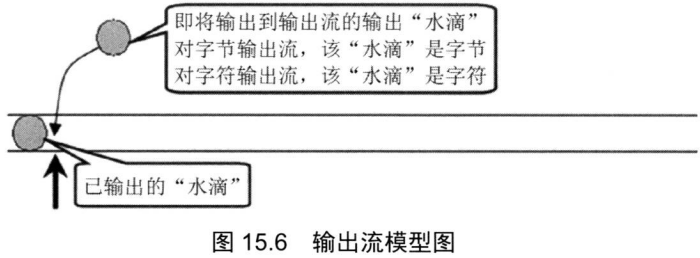
public class PushbackTest { public static void main(String[] args) { try( // 创建一个PushbackReader对象,指定推回缓冲区的长度为64 PushbackReader pr =
PushbackReader其他方法
方法
描述
void close()
Closes the stream and releases any system resources associated with it.
void mark(int readAheadLimit)
Marks the present position in the stream.
boolean markSupported()
Tells whether this stream supports the mark() operation, which it does not.
int read()
Reads a single character.
int read(char[] cbuf, int off, int len)
Reads characters into a portion of an array.
boolean ready()
Tells whether this stream is ready to be read.
void reset()
Resets the stream.
long skip(long n)
Skips characters.
PushbackInputStream其他方法
方法
描述
int available()
Returns an estimate of the number of bytes that can be read (or skipped over) from this input stream without blocking by the next invocation of a method for this input stream.
void close()
Closes this input stream and releases any system resources associated with the stream.
void mark(int readlimit)
Marks the current position in this input stream.
boolean markSupported()
Tests if this input stream supports the mark and reset methods, which it does not.
int read()
Reads the next byte of data from this input stream.
int read(byte[] b, int off, int len)
Reads up to len bytes of data from this input stream into an array of bytes.
void reset()
Repositions this stream to the position at the time the mark method was last called on this input stream.
long skip(long n)
Skips over and discards n bytes of data from this input stream.
Returns an estimate of the number of bytes that can be read(or skipped over) from this input stream without blocking by the next invocation of a method for this input stream.
void close()
Closes this input stream and releases any system resources associated with the stream.
byte[] readAllBytes()
Reads all remaining bytes from the input stream.
int readNBytes(byte[] b, int off, int len)
Reads the requested number of bytes from the input stream into the given byte array.
long transferTo(OutputStream out)
Reads all bytes from this input stream and writes the bytes to the given output stream in the order that they are read.
Reader其他方法
方法
描述
abstract void close()
Closes the stream and releases any system resources associated with it.
int read(CharBuffer target)
Attempts to read characters into the specified character buffer.