15.9.2 使用Buffer
15.9.2 使用Buffer
从内部结构上来看,Buffer就像一个数组,它可以保存多个类型相同的数据。Buffer是一个抽象类,其最常用的子类是ByteBuffer,它可以在底层字节数组上进行get/set操作。除ByteBuffer之外,对应于其他基本数据类型(boolean除外)都有相应的Buffer类:CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。
创建Buffer对象
上面这些Buffer类,除ByteBuffer之外,它们都采用相同或相似的方法来管理数据,只是各自管理的数据类型不同而已。这些Buffer类都没有提供构造器,通过使用如下方法来得到一个Buffer对象。
| 方法 | 描述 |
|---|---|
static XxxBuffer allocate(int capacity) |
创建一个容量为capacity的XxX Buffer对象。 |
展开/折叠
| 方法 | 描述 |
|---|---|
static ByteBuffer allocate(int capacity) |
Allocates a new byte buffer. |
static ShortBuffer allocate(int capacity) |
Allocates a new short buffer. |
static IntBuffer allocate(int capacity) |
Allocates a new int buffer. |
static LongBuffer allocate(int capacity) |
Allocates a new long buffer. |
static CharBuffer allocate(int capacity) |
Allocates a new char buffer. |
static FloatBuffer allocate(int capacity) |
Allocates a new float buffer. |
static DoubleBuffer allocate(int capacity) |
Allocates a new double buffer. |
但实际使用较多的是ByteBuffer和CharBuffer,其他Buffer子类则较少用到。
MappedByteBuffer
其中ByteBuffer类还有一个子类:MappedByteBuffer,MappedByteBuffer用于表示Channel将磁盘文件的部分或全部内容映射到内存中后得到的结果,通常MappedByteBuffer对象由Channel的map()方法返回。
容量 界限 位置
在Buffer中有三个重要的概念:容量(capacity)、界限(limit)和位置(position)
- 容量(
capacity):- 缓冲区的容量(
capacity)表示该Buffer的最大数据容量,即最多可以存储多少数据。缓冲区的容量不可能为负值,创建后不能改变。
- 缓冲区的容量(
- 界限(
limit):- 第一个不应该被读出或者写入的缓冲区位置索引。也就是说,位于
limit后的数据既不可被读,也不可被写。
- 第一个不应该被读出或者写入的缓冲区位置索引。也就是说,位于
- 位置(
position):- 用于指明下一个可以被读出的或者写入的缓冲区位置索引(类似于
IO流中的记录指针)。当使用Buffer从Channel中读取数据时,position的值恰好等于已经读到了多少数据: - 当刚刚新建一个
Buffer对象时,其position为0,也就是第1个位置的索引为0; - 如果从
Channel中读取了2个数据到该Buffer中,则position为2,指向Buffer中第3个位置
- 用于指明下一个可以被读出的或者写入的缓冲区位置索引(类似于
标记
除此之外,Buffer里还支持一个可选的标记(mark),类似于传统IO流中的mark(),Buffer允许直接将position定位到该mark处。这些值满足如下关系:
0≤mark≤position≤limit≤capacity
图15.16显示了某个Buffer读入了一些数据后的示意图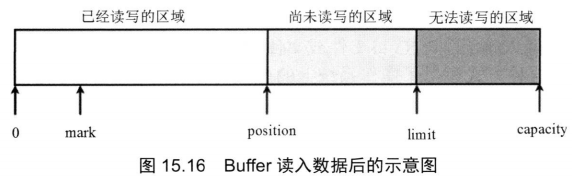
Buffer的作用
Buffer的主要作用就是装入数据,然后输出数据(其作用类似于前面介绍的取水的“竹筒”),开始时Buffer的position为0,limit为capacity
装入数据 put方法
程序可通过put()方法向Buffer中放入一些数据(或者从Channel中获取一些数据),每放入一些数据,Buffer的position相应地向后移动一些位置。
ByteBuffer的put方法
展开/折叠
ByteBuffer的put方法 |
描述 |
|---|---|
abstract ByteBuffer put(byte b) |
Relative put method (optional operation). |
ByteBuffer put(byte[] src) |
Relative bulk put method (optional operation). |
ByteBuffer put(byte[] src, int offset, int length) |
Relative bulk put method (optional operation). |
abstract ByteBuffer put(int index, byte b) |
Absolute put method (optional operation). |
ByteBuffer put(ByteBuffer src) |
Relative bulk put method (optional operation). |
| 方法 | 描述 |
|---|---|
abstract ByteBuffer putChar(char value) |
Relative put method for writing a char value (optional operation). |
abstract ByteBuffer putChar(int index, char value) |
Absolute put method for writing a char value (optional operation). |
abstract ByteBuffer putDouble(double value) |
Relative put method for writing a double value (optional operation). |
abstract ByteBuffer putDouble(int index, double value) |
Absolute put method for writing a double value (optional operation). |
abstract ByteBuffer putFloat(float value) |
Relative put method for writing a float value (optional operation). |
abstract ByteBuffer putFloat(int index, float value) |
Absolute put method for writing a float value (optional operation). |
abstract ByteBuffer putInt(int value) |
Relative put method for writing an int value (optional operation). |
abstract ByteBuffer putInt(int index, int value) |
Absolute put method for writing an int value (optional operation). |
abstract ByteBuffer putLong(int index, long value) |
Absolute put method for writing a long value (optional operation). |
abstract ByteBuffer putLong(long value) |
Relative put method for writing a long value (optional operation). |
abstract ByteBuffer putShort(int index, short value) |
Absolute put method for writing a short value (optional operation). |
abstract ByteBuffer putShort(short value) |
Relative put method for writing a short value (optional operation). |
CharBuffer的put方法
展开/折叠
| 方法 | 描述 |
|---|---|
abstract CharBuffer put(char c) |
Relative put method (optional operation). |
CharBuffer put(char[] src) |
Relative bulk put method (optional operation). |
CharBuffer put(char[] src, int offset, int length) |
Relative bulk put method (optional operation). |
abstract CharBuffer put(int index, char c) |
Absolute put method (optional operation). |
CharBuffer put(String src) |
Relative bulk put method (optional operation). |
CharBuffer put(String src, int start, int end) |
Relative bulk put method (optional operation). |
CharBuffer put(CharBuffer src) |
Relative bulk put method (optional operation). |
准备输出数据 flip方法
当Buffer装入数据结束后,调用Buffer的flip()方法,该方法将limit设置为position所在位置,并将position设为0,这就使得Buffer的读写指针又移到了开始位置。
需要读取Buffer中的数据时调用flip方法
也就是说,Buffer调用flip()方法之后,Buffer为输出数据做好了准备;
| Buffer类的flip方法 | 描述 |
|---|---|
Buffer flip() |
Flips this buffer. |
准备再次装入数据 clear方法
当Buffer输出数据结束后,Buffer调用clear()方法,clear方法不是清空Buffer的数据,它仅仅将position置为0,将limit置为capacity,这样为再次向Buffer中装入数据做好准备。
| Buffer类的clear方法 | 描述 |
|---|---|
Buffer clear() |
Clears this buffer. |
取出flip 再次装入clear
Buffer中包含两个重要的方法,即flip()和clear(),
flip为从Buffer中取出数据做好准备,clear为再次向Buffer中装入数据做好准备
Buffer其他常用方法
除此之外,Buffer还包含如下一些常用的方法。
| 方法 | 描述 |
|---|---|
int capacity() |
返回Buffer的capacity大小。 |
boolean hasRemaining() |
判断当前位置(position)和界限(limit)之间是否还有元素可供处理 |
int limit() |
返回Buffer的界限(limit)的位置。 |
Buffer limit(int newLimit) |
重新设置界限(limit)的值,并返回一个具有新的limit的缓冲区对象 |
Buffer mark() |
设置Buffer的mark位置,它只能在0和位置(position)之间做mark。 |
int position() |
返回Buffer中的position值 |
Buffer position(int newPosition) |
设置Buffer的position,并返回position被修改后的Buffer对象 |
int remaining() |
返回当前位置和界限(limit)之间的元素个数 |
Buffer reset() |
将位置(position)转到mark所在的位置。 |
Buffer rewind() |
将位置(position)设置成0,取消设置的mark |
放入 取出
除这些移动position、limit、mark的方法之外,Buffer的所有子类还提供了两个重要的方法:put()和get()方法,用于向Buffer中放入数据和从Buffer中取出数据。当使用put()和get()方法放入、取出数据时,Buffer既支持对单个数据的访问,也支持对批量数据的访问(以数组作为参数)。
相对 绝对
当使用put()和get()来访问Buffer中的数据时,分为相对和绝对两种。
- 相对(
Relative):- 从
Buffer的当前position处开始读取或写入数据,然后将位置(position)的值按处理元素的个数增加
- 从
- 绝对(
Absolute):- 直接**根据索引向
Buffer中读取或写入数据**,使用绝对方式访问Buffer里的数据时,并不会影响位置(position)的值。
- 直接**根据索引向
程序示例
下面程序示范了Buffer的一些常规操作。
1 | import java.nio.*; |
在上面程序的①号代码处:
1 | CharBuffer buff = CharBuffer.allocate(8); // ① |
通过CharBuffer的一个静态方法allocate()创建了一个capacity为8的CharBuffer,此时该Buffer的limit和capacity为8,position为0,如图15.17所示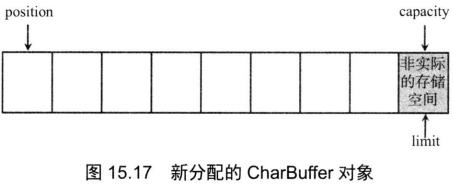
接下来程序执行到②号代码处:
1 | buff.put('a'); |
程序向CharBuffer中放入3个数值,放入3个数值后的CharBuffer效果如图15.18所示。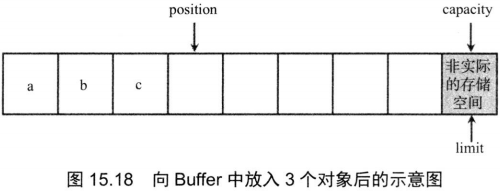
程序执行到③号代码处:
1 | buff.flip(); // ③ |
调用了Buffer的flip()方法,该方法将把limit设为position处,把position设为0,如图15.19所示。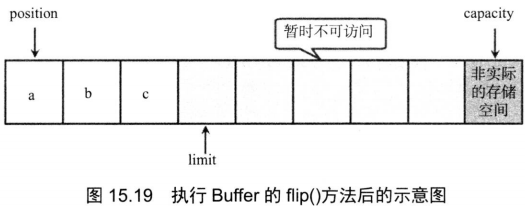
从图15.19中可以看出,当Buffer调用了flip()方法之后,limit就移到了原来position所在位置,这样相当于把Buffer中没有数据的存储空间“封印”起来,从而避免读取Buffer数据时读到null值。
无参get方法会使得position加一
接下来程序在④号代码处:
1 | System.out.println("第一个元素(position=0):" + buff.get()); // ④ |
取出一个元素,取出一个元素后position向后移动一位,也就是该Buffer的position等于1。
程序执行到⑤号代码处:
1 | buff.clear(); // ⑤ |
Buffer调用clear()方法将position设为0,将limit设为与capacity相等。执行clear()方法后的Buffer示意图如图15.20所示。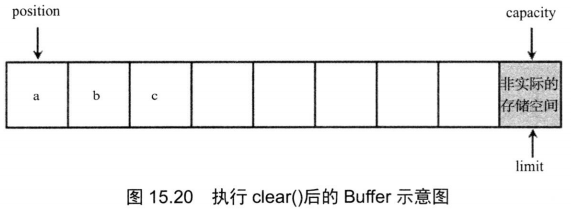
根据索引获取值的get方法不会影响position
从图15.20中可以看出,对Buffer执行clear方法后,该Buffer对象里的数据依然存在,所以程序在⑥号代码处依然可以取出位置为2的值,也就是字符c。因为⑥号代码:
1 | System.out.println("执行clear()后,缓冲区内容并没有被清除:" + |
采用的是根据索引来取值的方式,所以该方法不会影响Buffer的position.
普通Buffer 直接Buffer
通过allocate方法创建的Buffer对象是普通Buffer.ByteBuffer还提供了一个allocateDirect()方法来创建直接Buffer。直接Buffer的创建成本比普通Buffer的创建成本高,但直接Buffer的读取效率更高。
只有在ByteBuffer级别上才能创建直接Buffer
由于直接Buffer的创建成本很高,所以**直接Buffer只适用于长生存期的Buffer,而不适用于短生存期、一次用完就丢弃的Buffer。而且只有ByteBuffer才提供了allocateDirect()方法,所以只有在ByteBuffer级别上才能创建直接Buffer。如果希望使用其他类型,则应该将该直接Buffer**转换成其他类型的Buffer。
| 方法 | 描述 |
|---|---|
static ByteBuffer allocateDirect(int capacity) |
Allocates a new direct byte buffer. |