17.1 网络编程的基础知识
17.1.1 网络基础知识
所谓计算机网络,就是把分布在不同地理区域的计算机与专门的外部设备用通信线路互连成一个规模大、功能强的网络系统,从而使众多的计算机可以方便地互相传递信息,共享硬件、软件、数据信息等资源
计算机网络是现代通信技术与计算机技术相结合的产物,计算机网络可以提供以下一些主要功能。
- 资源共享。
- 信息传输与集中处理。
- 均衡负荷与分布处理
- 综合信息服务。
通过计算机网络可以向全社会提供各种经济信息、科研情报和咨询服务。其中,国际互联网Internet上的全球信息网(WWW,World Wide Web)服务就是一个最典型也是最成功的例子。实际上,今天的网络承载绝大部分大型企业的运转,一个大型的、全球性的企业或组织的日常工作流程都是建立在互联网基础之上的。
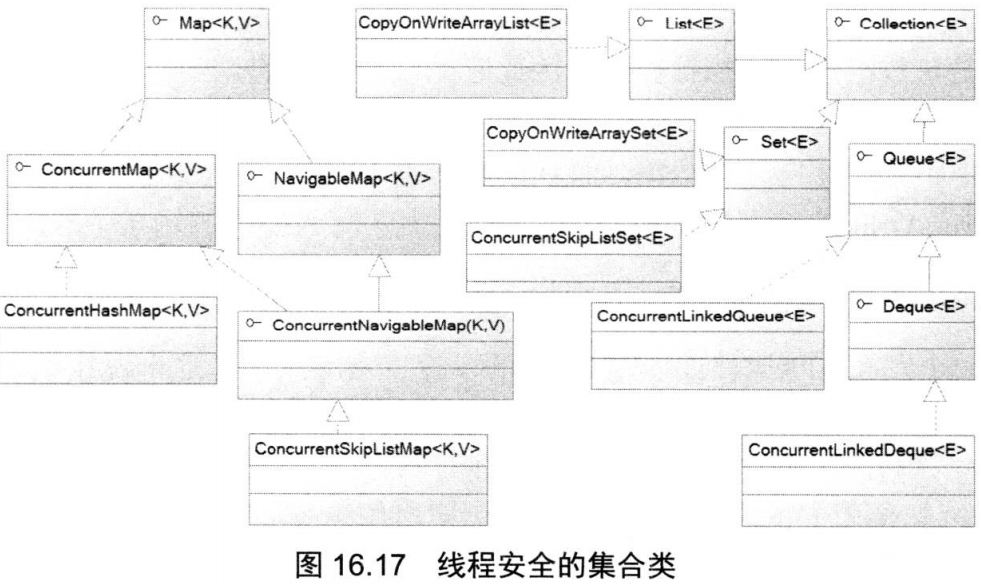
计算机网络分类
计算机网络的品种很多,根据各种不同的分类原则,可以得到各种不同类型的计算机网络。
计算机网络通常是按照规模大小和延伸范围来分类的,常见的划分为:局域网(LAN)、城域网(MAN)、厂域网(WAN)。Internet可以视为世界上最大的广域网。
如果按照网络的拓扑结构来划分,可以分为星型网络、总线型网络、环型网络、树型网络、星型环型网络等;
通信协议
如果按照网络的传输介质来划分,可以分为双绞线网、同轴电缆网、光纤网和卫星网等。
计算机网络中实现通信必须有一些约定,这些约定被称为通信协议。通信协议负责对传输速率、传输代码、代码结构、传输控制步骤、岀错控制等制定处理标准。为了让两个节点之间能进行对话,必须在它们之间建立通信工具,使彼此之间能进行信息交换。
通信协议组成
通信协议通常由三部分组成:
- 一是语义部分,用于决定双方对话的类型;
- 二是语法部分,用于决定双方对话的格式;
- 三是变换规则,用于决定通信双方的应答关系。
OSI
国际标准化组织ISO于1978年提出“开放系统互连参考模型”,即著名的OSI(Open System Interconnection)。
开放系统互连参考模型力求将网络简化,并以模块化的方式来设计网络。
开放系统互连参考模型把计算机网络分成
- 物理层、
- 数据链路层、
- 网络层、
- 传输层、
- 会话层、
- 表示层、
- 应用层
这七层
通过十多年的发展和推进,OSI模式已成为各种计算机网络结构的参考标准
图17.1显示了OSI参考模型的推荐分层。
IP
前面介绍过通信协议是网络通信的基础,IP协议则是一种非常重要的通信协议。IP(Internet Protocol)协议又称互联网协议,是支持网间互联的数据报协议。它提供网间连接的完善功能,包括IP数据报规定互联网络范围内的地址格式
TCP
经常与IP协议放在一起的还有TCP(Transmission Control protocol)协议,即传输控制协议,它规定一种可靠的数据信息传递服务。虽然IP和TCP这两个协议功能不尽相同,也可以分开单独使用,但它们是在同一个时期作为一个协议来设计的,并且在功能上也是互补的。因此实际使用中常常把这两个协议统称为TCP/IP协议,TCP/IP协议最早出现在UNIX操作系统中,现在几乎所有的操作系统都支持TCPP协议,因此TCP/IP协议也是Internet中最常用的基础协议。
TCP/IP和OSI分层的关系
按TCP/IP协议模型,网络通常被分为一个四层模型,这个四层模型和前面的OSI七层模型有大致的对应关系,图17.2显示了TCPP分层模型和OSI分层模型之间的对应关系。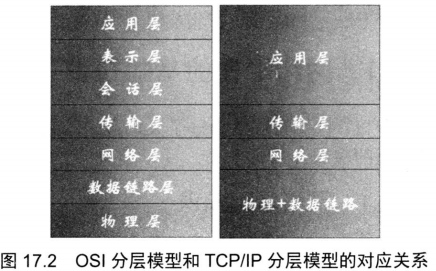
17.1.2 IP地址和端口号
IP地址用于唯一地标识网络中的一个通信实体,这个通信实体既可以是一台主机,也可以是一台打印机,或者是路由器的某一个端口。而在基于IP协议网络中传输的数据包,都必须使用P地址来进行标识。
就像写一封信,要标明收信人的通信地址和发信人的地址,而邮政工作人员则通过该地址来决定邮件的去向。类似的过程也发生在计算机网络里,每个被传输的数据包也要包括一个源IP地址和一个目的IP地址,当该数据包在网络中进行传输时,这两个地址要保持不变,以确保网络设备总能根据确定的P地址,将数据包从源通信实体送往指定的目的通信实体。
IP地址是数字型的,IP地址是一个32位(32 bit)整数,但通常为了便于记忆,通常把它分成4个8位的二进制数,每8位之间用圆点隔开,每个8位整数可以转换成一个0~255的十进制整数,因此日常看到的IP地址常常是这种形式:202.9.128.88。
NIC(Internet Network Information Center)统一负责全球Internet IP地址的规划、管理,而Inter NIC、 APNIC、RIPE三大网络信息中心具体负责美国及其他地区的IP地址分配。其中APNIC负责亚太地区的IP管理,我国申请IP地址也要通过APNIC,APNIC的总部设在日本东京大学。
五类IP地址
IP地址被分成了A、B、C、D、E五类,每个类别的网络标识和主机标识各有规则。
- A类:10.0.0.0~10.255.255.255
- B类:172.16.0.0~172.31.255.255
- C类:192.168.0.0~192.168.255.255
端口
IP地址用于唯一地标识网络上的一个通信实体,但一个通信实体可以有多个通信程序同时提供网络服务,此时还需要使用端口。
端口是一个16位的整数,用于表示数据交给哪个通信程序处理。因此,端口就是应用程序与外界交流的出入口,它是一种抽象的软件结构,包括一些数据结构和IO(基本输入输出)缓冲区。
不同的应用程序处理不同端口上的数据,同一台机器上不能有两个程序使用同一个端口,端口号可以从0到65535。
端口分类
通常将端口分为如下三类:
- 公认端口(
Well Known Ports):从0到1023,它们紧密绑定(Binding)一些特定的服务 - 注册端口(
Registered Ports):从1024到49151,它们松散地绑定一些服务。应用程序通常应该使用这个范围内的端口. - 动态和或私有端口(
Dynamic And/or Private Ports):从49152到65535,这些端口是应用程序使用的动态端口,应用程序一般不会主动使用这些端口
如果把IP地址理解为某个人所在地方的地址(包括街道和门牌号),但仅有地址还是找不到这个人,还需要知道他所在的房号才可以找到这个人。因此如果把应用程序当作人,把计算机网络当作类似邮递员的角色,当一个程序需要发送数据时,需要指定目的地的IP地址和端口,如果指定了正确的IP地址和端口号,计算机网络就可以将数据送给该IP地址和端口所对应的程序。