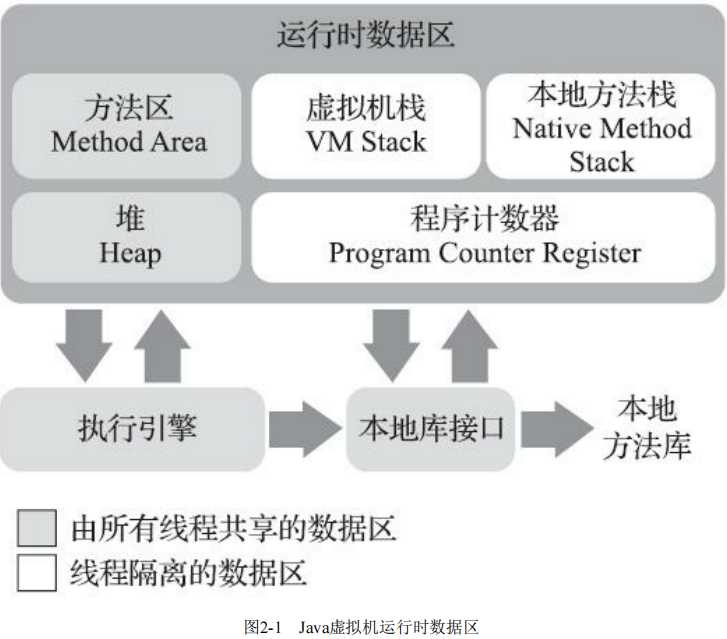
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定(如何确定将在2.3.2节中介绍),为对象分配空间的任务实际上便等同于把一块确定大小的内存块从Java堆中划分出来。假设Java堆中内存是绝对规整的,所有被使用过的内存都被放在一边,空闲的内存被放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间方向挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”(Bump The Pointer)。但如果Java堆中的内存并不是规整的,已被使用的内存和空闲的内存相互交错在一起,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”(Free List)。选择哪种分配方式由Java堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有空间压缩整理(Compact)的能力决定。因此,当使用Serial、ParNew等带压缩整理过程的收集器时,系统采用的分配算法是指针碰撞,既简单又高效;而当使用CMS这种基于清除 (Sweep)算法的收集器时,理论上[^1]就只能采用较为复杂的空闲列表来分配内存。
除如何划分可用空间之外,还有另外一个需要考虑的问题:对象创建在虚拟机中是非常频繁的行为,即使仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。解决这个问题有两种可选方案:一种是对分配内存空间的动作进行同步处理——实际上虚拟机是采用CAS配上失败重试的方式保证更新操作的原子性;另外一种是把内存分配的动作按照线程划分在不同的空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),哪个线程要分配内存,就在哪个线程的本地缓冲区中分配,只有本地缓冲区用完了,分配新的缓存区时才需要同步锁定。虚拟机是否使用TLAB,可以通过-XX:+/-UseTLAB参数来设定。
[^1]: 《Java虚拟机规范》中的原文:The heap is the runtime data area from which memory for all class instances and arrays is allocated。 [^2]: 逃逸分析与标量替换的相关内容,请参见第11章的相关内容。 [^3]: 指新生代(其中又包含一个Eden和两个Survivor)、老年代这种划分,源自UC Berkeley在20世纪80年代中期开发的Berkeley Smalltalk。历史上有多款虚拟机采用了这种设计,包括HotSpot和它的前身Self 和Strongtalk虚拟机(见第1章),原始论文是:https://dl.acm.org/citation.cfm?id=808261。