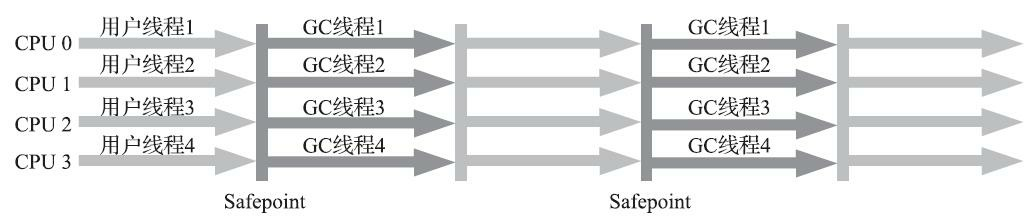
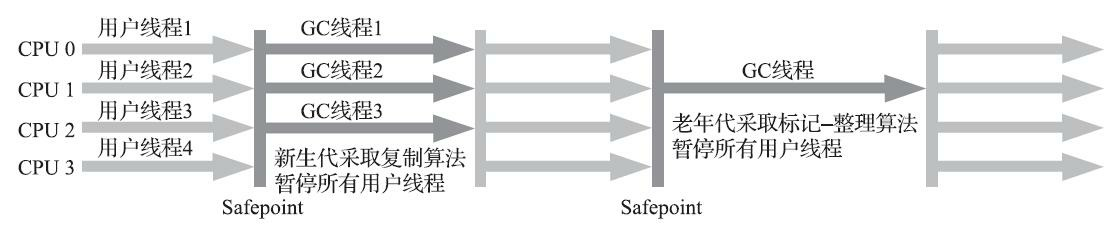
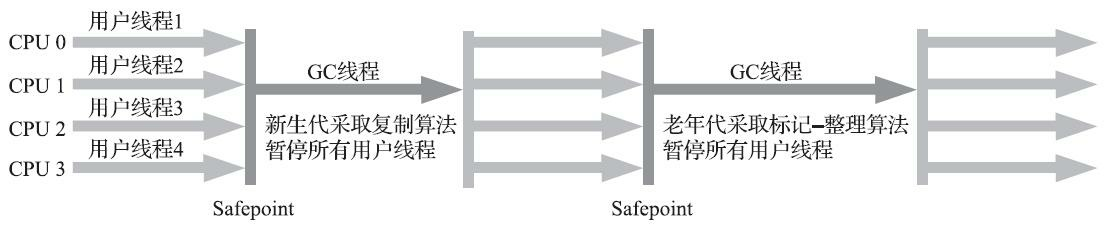
在3.2节中曾经提到了当前主流编程语言的垃圾收集器基本上都是依靠可达性分析算法来判定对象是否存活的,可达性分析算法理论上要求全过程都基于一个能保障一致性的快照中才能够进行分析, 这意味着必须全程冻结用户线程的运行。在根节点枚举(见3.4.1节)这个步骤中,由于GC Roots相比起整个Java堆中全部的对象毕竟还算是极少数,且在各种优化技巧(如OopMap)的加持下,它带来的停顿已经是非常短暂且相对固定(不随堆容量而增长)的了。可从GC Roots再继续往下遍历对象图,这一步骤的停顿时间就必定会与Java堆容量直接成正比例关系了:堆越大,存储的对象越多,对象图结构越复杂,要标记更多对象而产生的停顿时间自然就更长,这听起来是理所当然的事情。
要知道包含“标记”阶段是所有追踪式垃圾收集算法的共同特征,如果这个阶段会随着堆变大而等比例增加停顿时间,其影响就会波及几乎所有的垃圾收集器,同理可知,如果能够削减这部分停顿时间的话,那收益也将会是系统性的。
想解决或者降低用户线程的停顿,就要先搞清楚为什么必须在一个能保障一致性的快照上才能进行对象图的遍历?为了能解释清楚这个问题,我们引入三色标记(Tri-color Marking)^1作为工具来辅助推导,把遍历对象图过程中遇到的对象,按照“是否访问过”这个条件标记成以下三种颜色:
- 白色:表示对象尚未被垃圾收集器访问过。显然在可达性分析刚刚开始的阶段,所有的对象都是白色的,若在分析结束的阶段,仍然是白色的对象,即代表不可达。
- 黑色:表示对象已经被垃圾收集器访问过,且这个对象的所有引用都已经扫描过。黑色的对象代表已经扫描过,它是安全存活的,如果有其他对象引用指向了黑色对象,无须重新扫描一遍。黑色对象不可能直接(不经过灰色对象)指向某个白色对象。
- 灰色:表示对象已经被垃圾收集器访问过,但这个对象上至少存在一个引用还没有被扫描过。
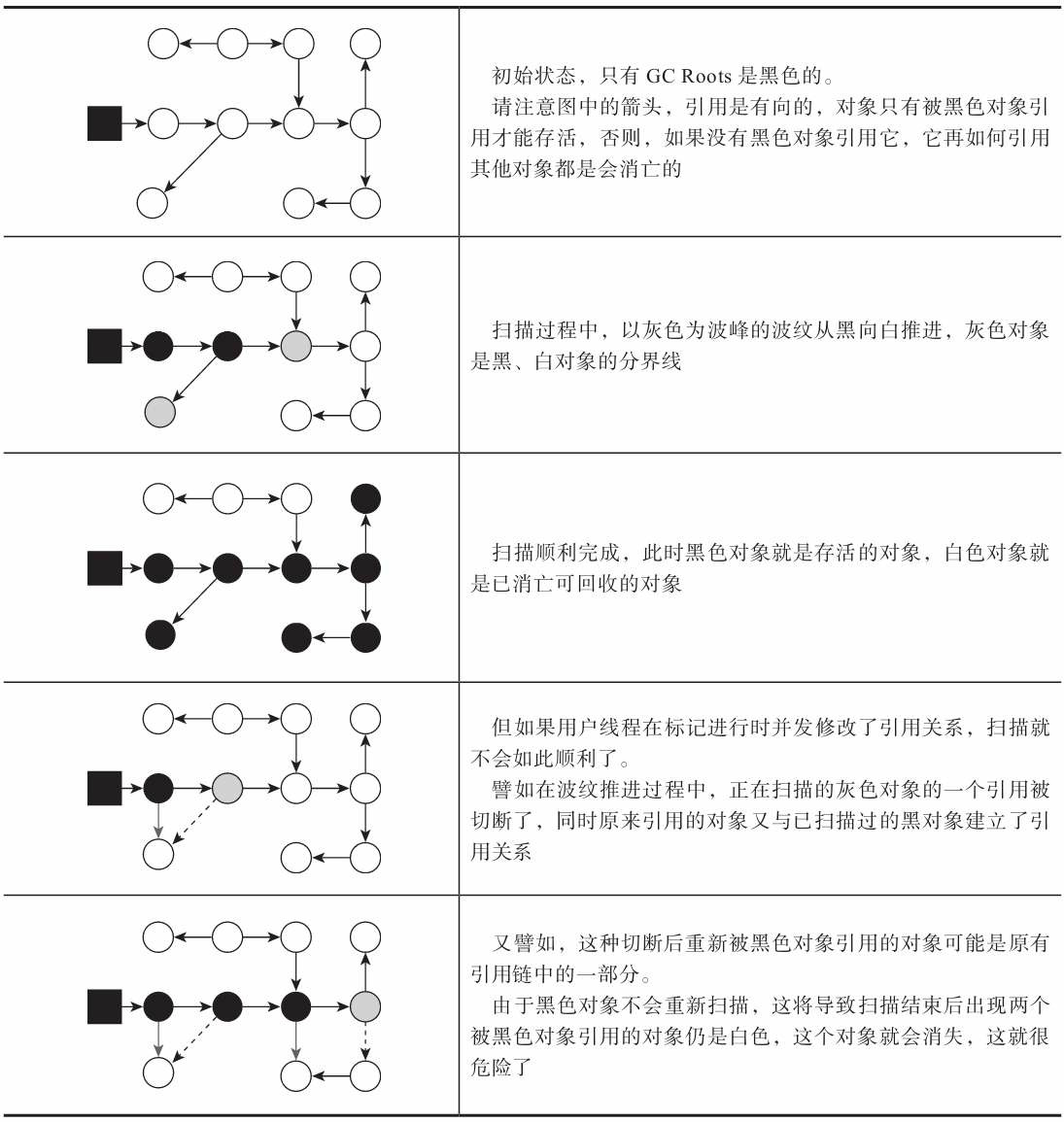
关于可达性分析的扫描过程,读者不妨发挥一下想象力,把它看作对象图上一股以灰色为波峰的波纹从黑向白推进的过程,如果用户线程此时是冻结的,只有收集器线程在工作,那不会有任何问题。但如果用户线程与收集器是并发工作呢?收集器在对象图上标记颜色,同时用户线程在修改引用关系——即修改对象图的结构,这样可能出现两种后果。一种是把原本消亡的对象错误标记为存活, 这不是好事,但其实是可以容忍的,只不过产生了一点逃过本次收集的浮动垃圾而已,下次收集清理掉就好。另一种是把原本存活的对象错误标记为已消亡,这就是非常致命的后果了,程序肯定会因此发生错误,下面表3-1演示了这样的致命错误具体是如何产生的。
表3-1 并发出现“对象消失”问题的示意[^2]
![image-20210916172542328]()
Wilson于1994年在理论上证明了,当且仅当以下两个条件同时满足时,会产生“对象消失”的问题,即原本应该是黑色的对象被误标为白色:
- 赋值器插入了一条或多条从黑色对象到白色对象的新引用;
- 赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。
因此,我们要解决并发扫描时的对象消失问题,只需破坏这两个条件的任意一个即可。由此分别产生了两种解决方案:增量更新(Incremental Update)和原始快照(Snapshot At The Beginning, SATB)。
增量更新要破坏的是第一个条件,当黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描结束之后,再将这些记录过的引用关系中的黑色对象为根,重新扫描一次。这可以简化理解为,黑色对象一旦新插入了指向白色对象的引用之后,它就变回灰色对象了。
原始快照要破坏的是第二个条件,当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束之后,再将这些记录过的引用关系中的灰色对象为根,重新扫描一次。这也可以简化理解为,无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照来进行搜索。
以上无论是对引用关系记录的插入还是删除,虚拟机的记录操作都是通过写屏障实现的。在HotSpot虚拟机中,增量更新和原始快照这两种解决方案都有实际应用,譬如,CMS是基于增量更新来做并发标记的,G1、Shenandoah则是用原始快照来实现。
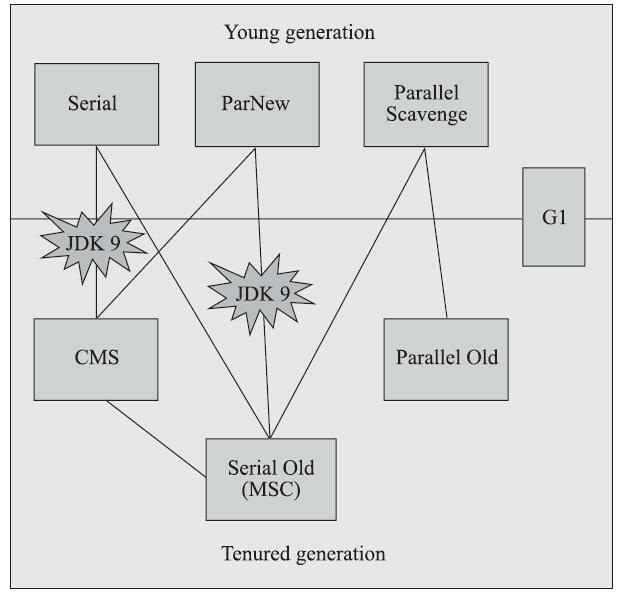
到这里,笔者简要介绍了HotSpot虚拟机如何发起内存回收、如何加速内存回收,以及如何保证回收正确性等问题,但是虚拟机如何具体地进行内存回收动作仍然未涉及。因为内存回收如何进行是由虚拟机所采用哪一款垃圾收集器所决定的,而通常虚拟机中往往有多种垃圾收集器,下面笔者将逐一介绍HotSpot虚拟机中出现过的垃圾收集器。
[^2]: 此例子中的图片引用了Aleksey Shipilev在DEVOXX 2017上的主题演讲:《Shenandoah GC Part I: The Garbage Collector That Could》。