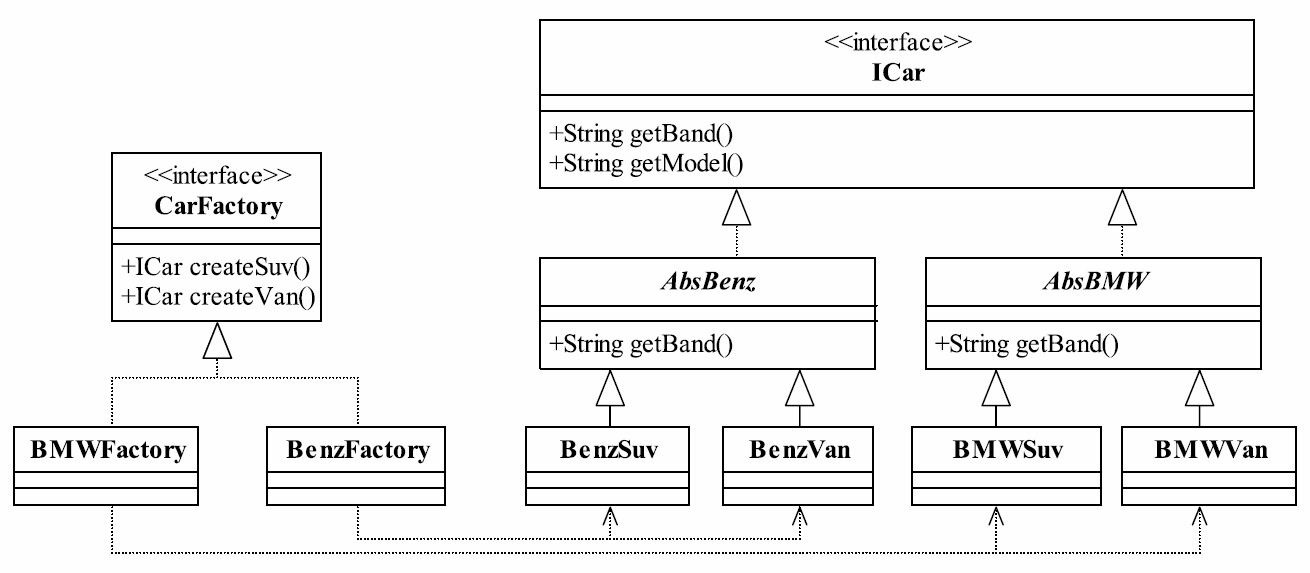
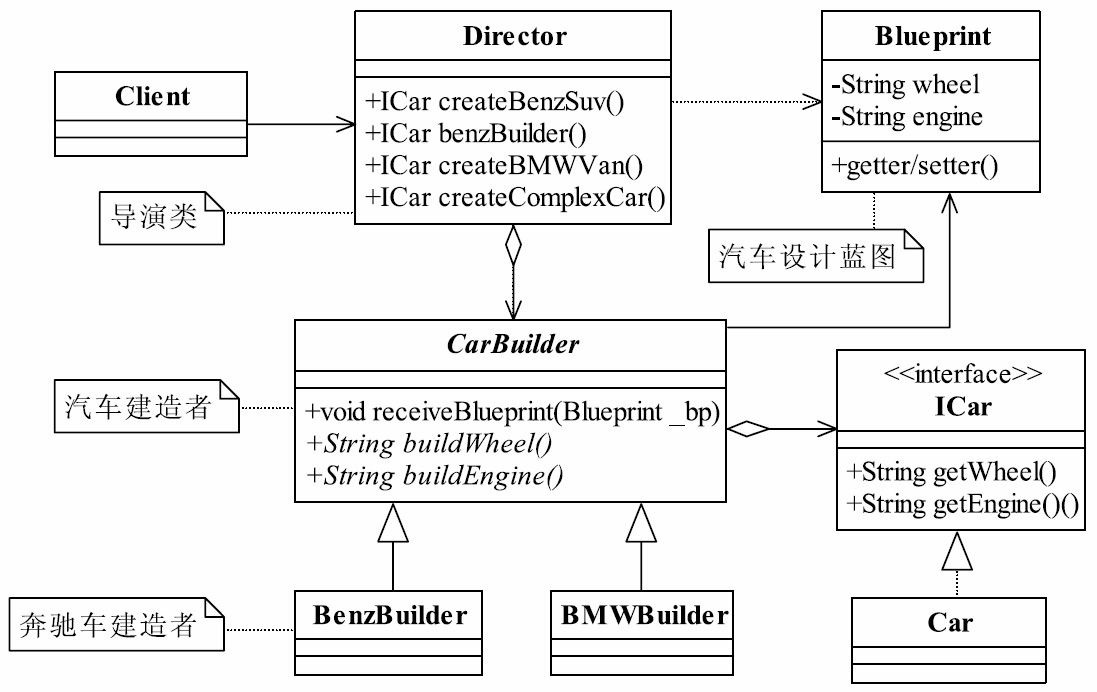
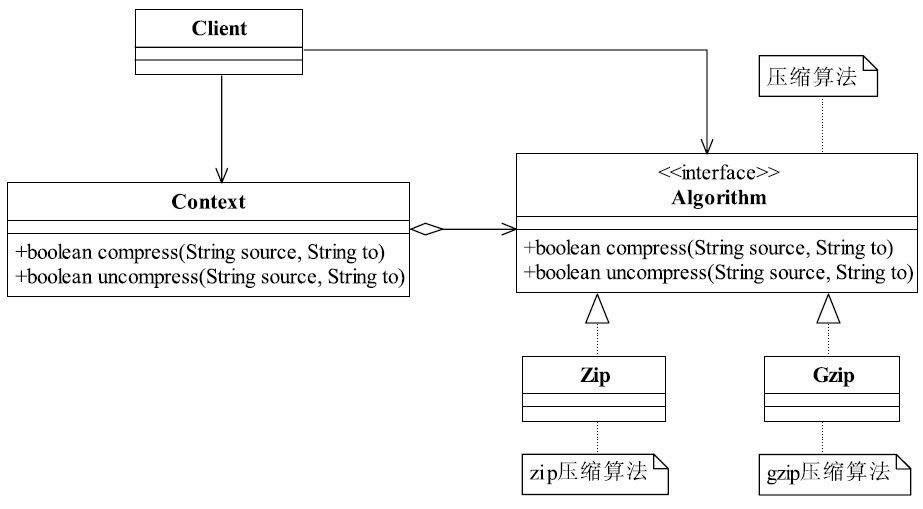
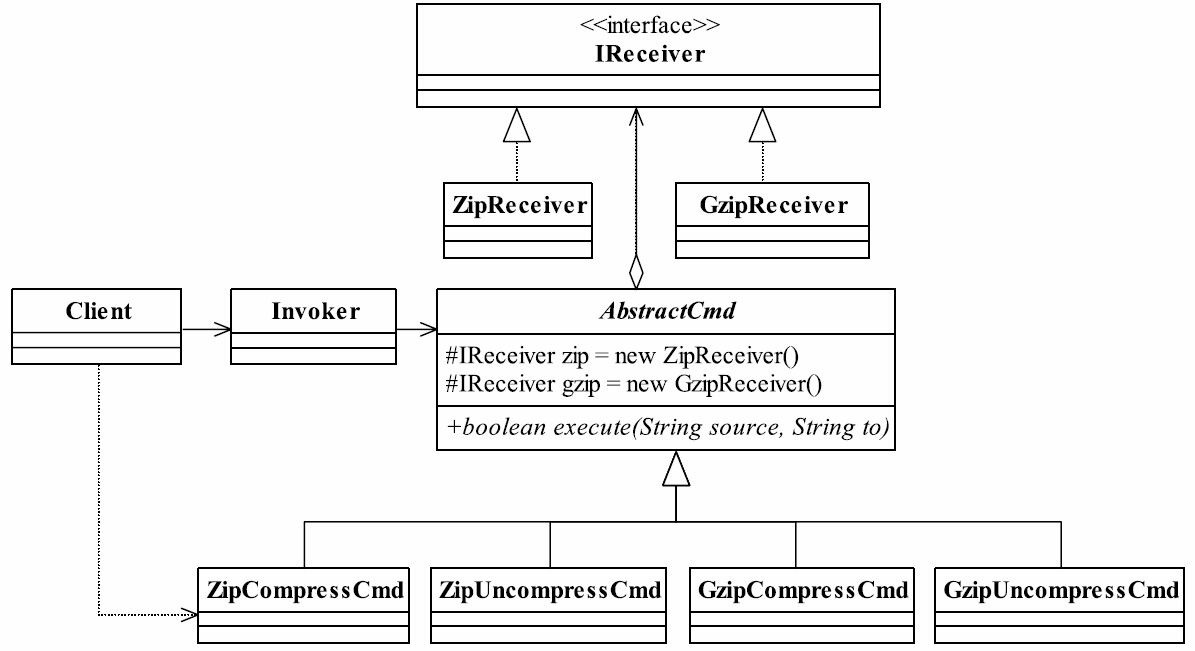
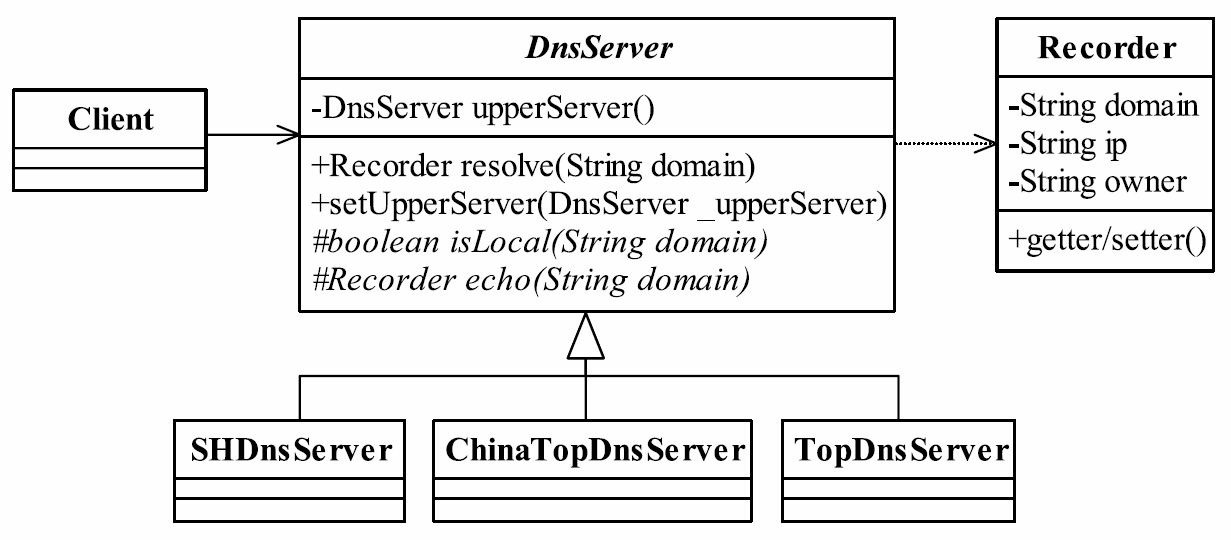
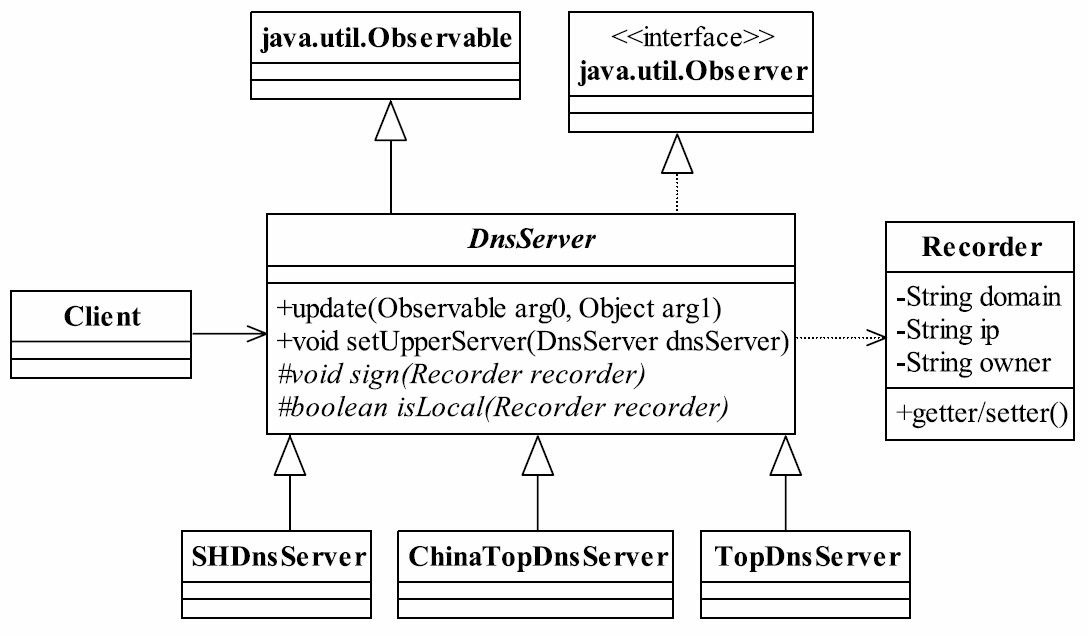
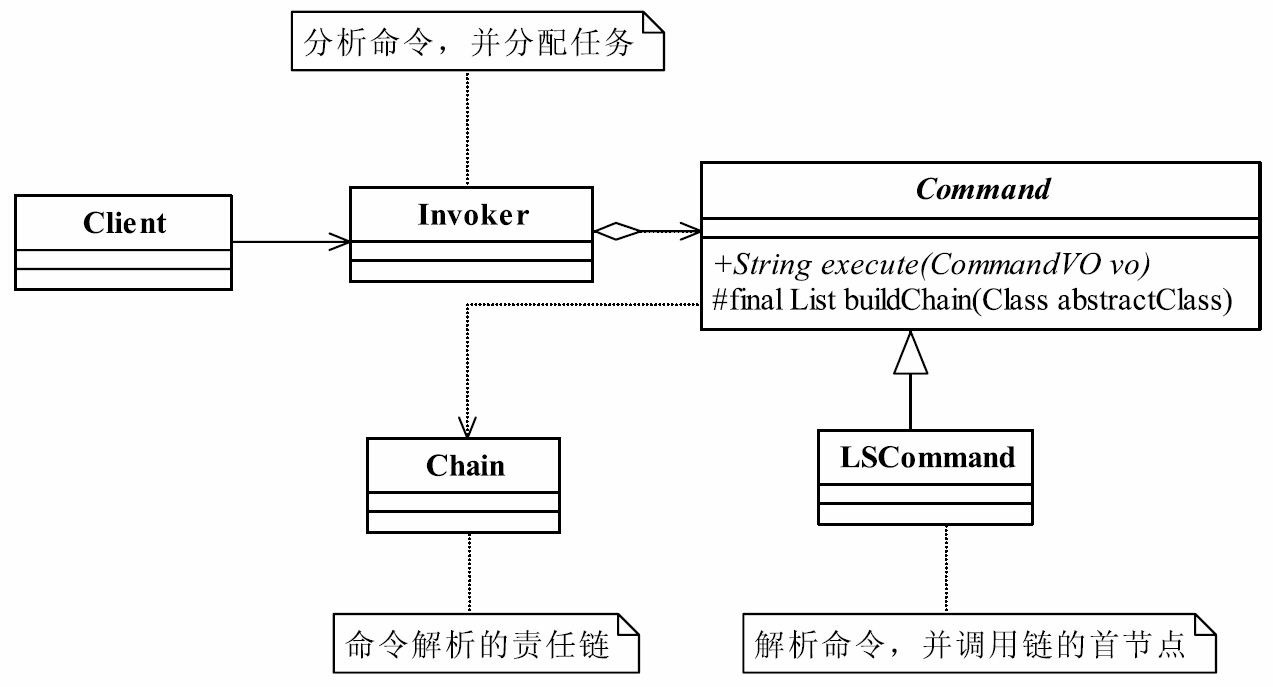
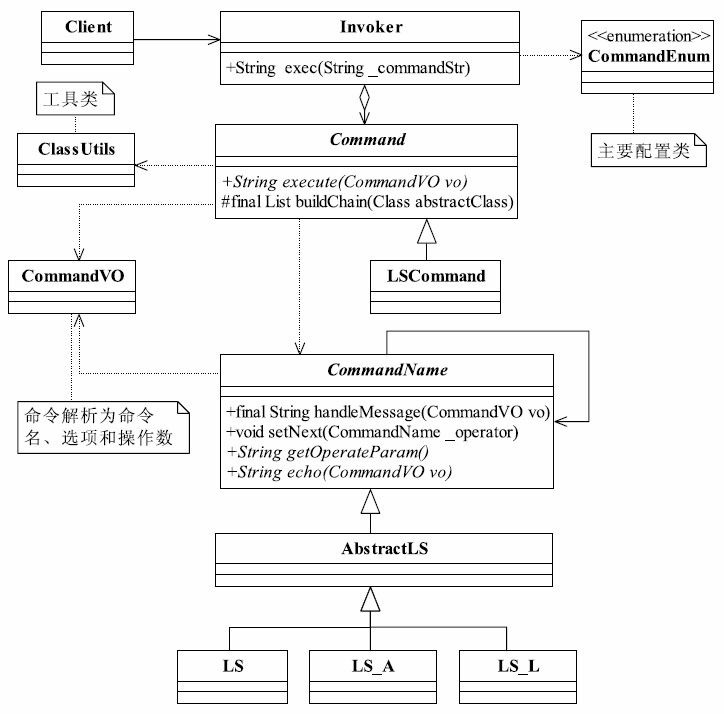
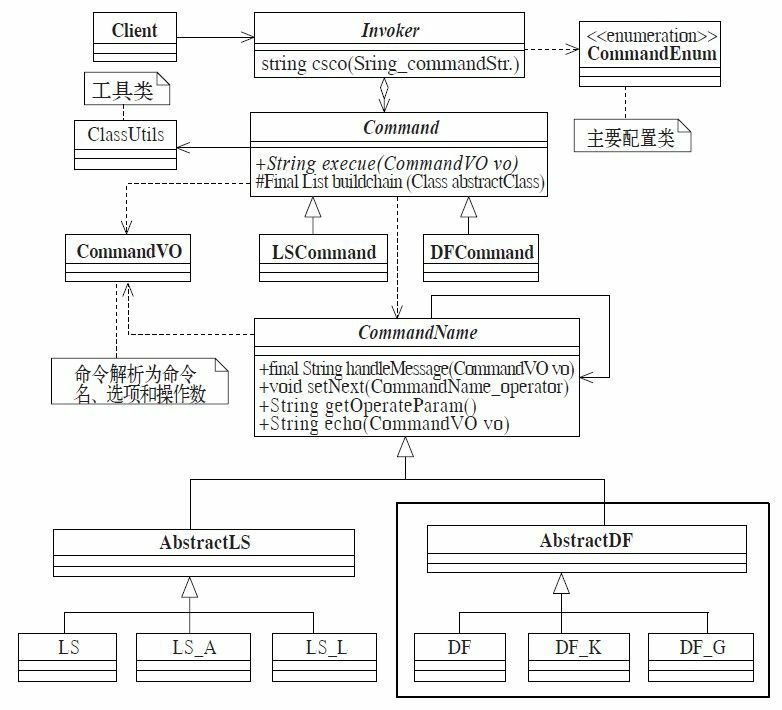
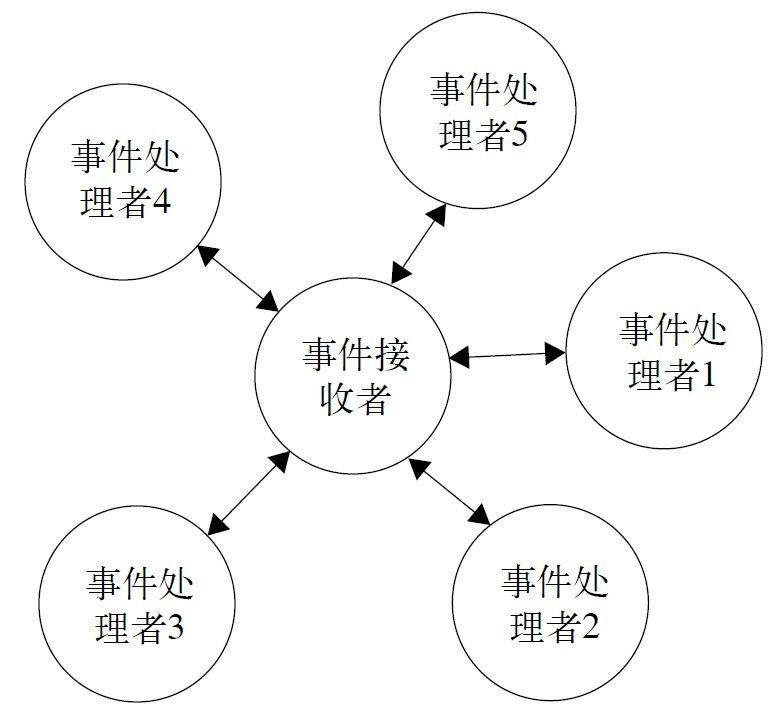
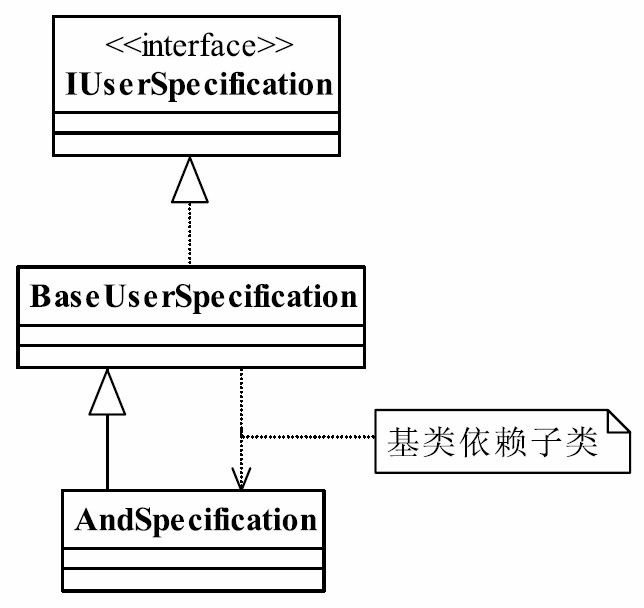
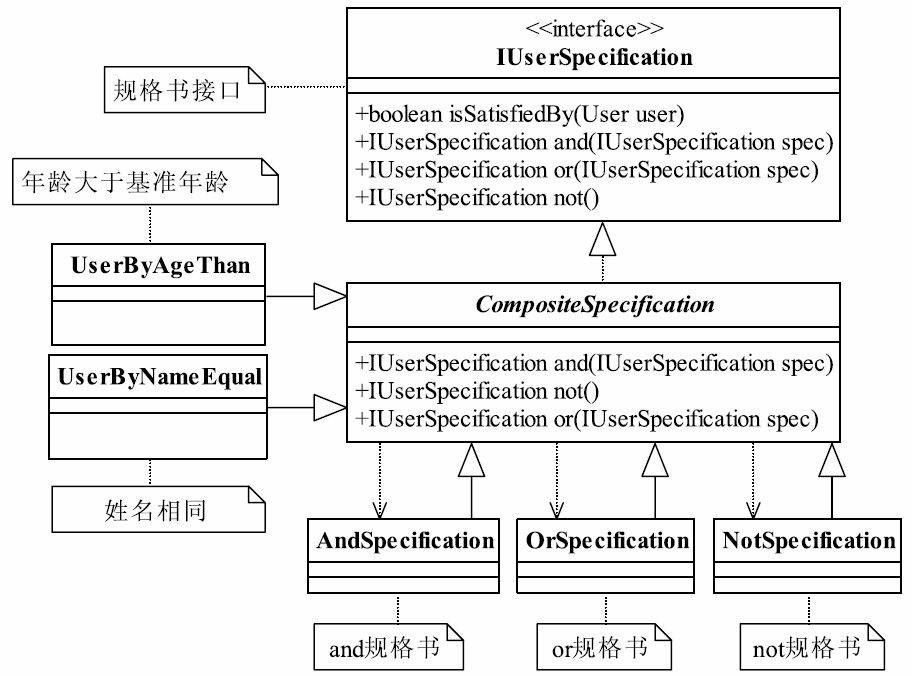
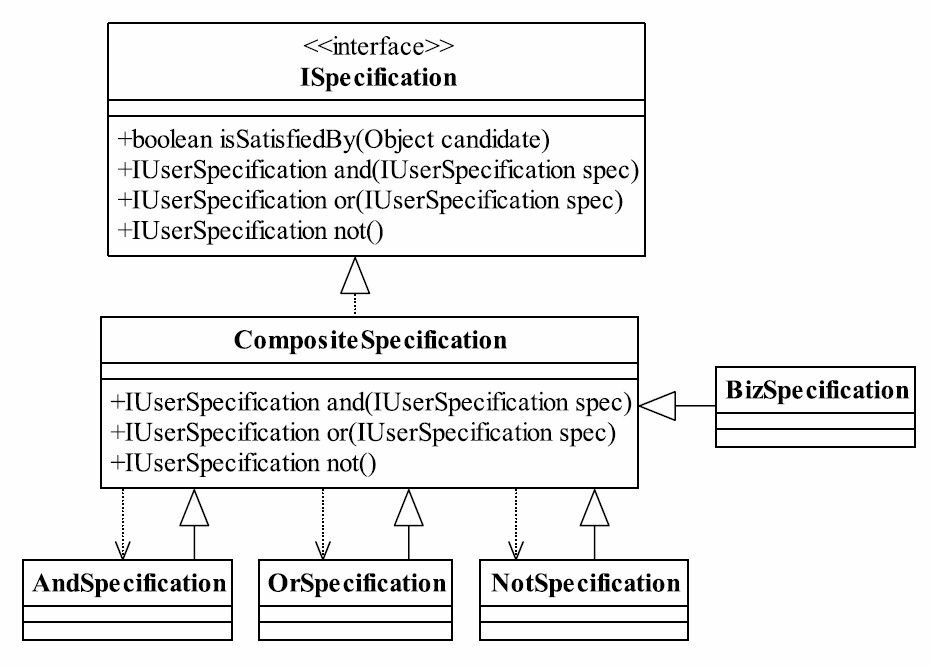
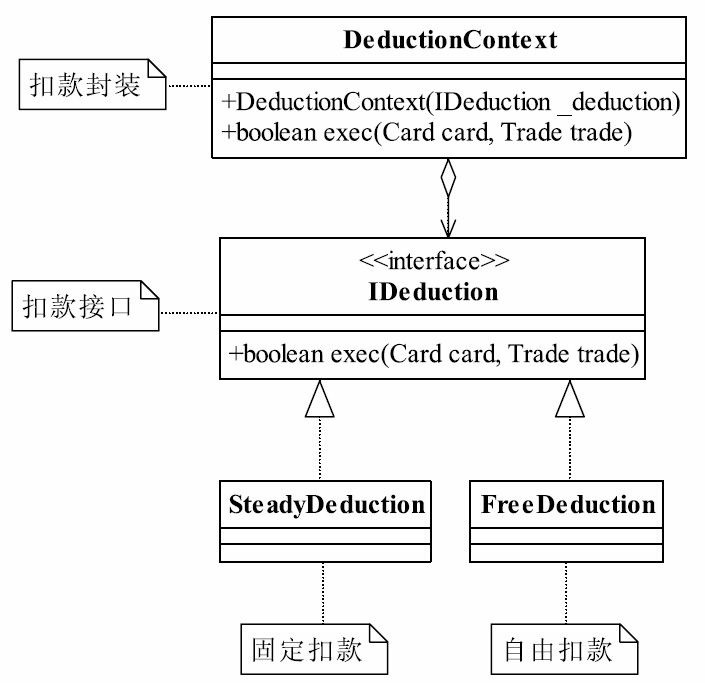
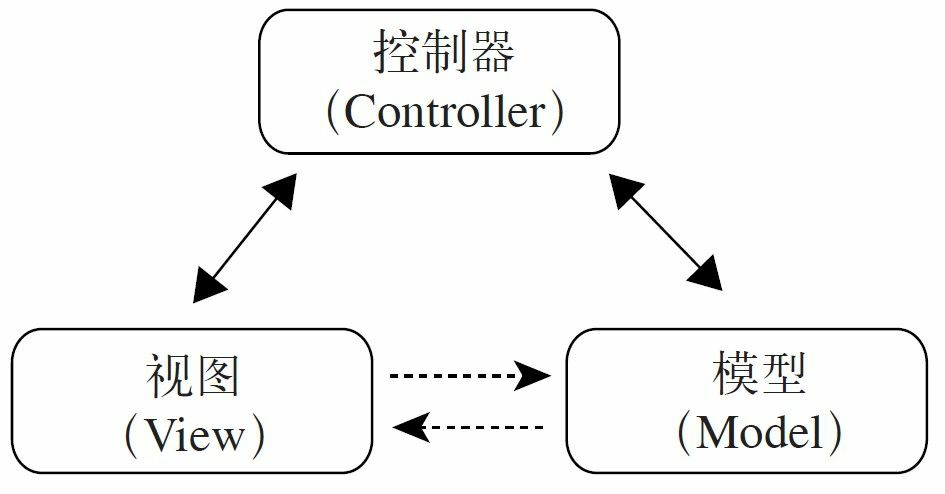
37.1 MVC框架的实现
相信这本书的读者对Struts的使用是得心应手了,也明白MVC框架有诸如视图与逻辑解耦、灵活稳定、业务逻辑可重用等优点,而且还对其他的MVC框架(例如JSF、Spring MVC、WebWork)也了解一点。SSH(Struts+Spring+Hibernate)框架是Java项目常用的框架,作为一个Java开发人员,应该对SSH框架很熟悉了!我们今天就学Struts怎么用!我们要讲的是MVC框架如何设计,你可以设计一个新的MVC框架与Struts抗衡。
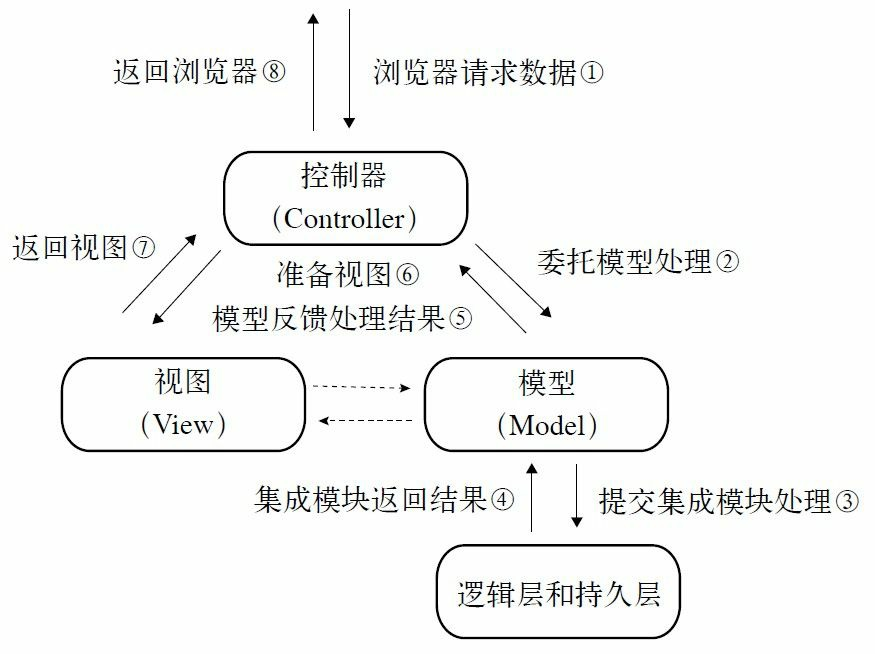
在开始设计MVC框架前,首先要对MVC框架做一个简单的介绍。MVC(Model ViewController)的中文名称叫做模型视图控制器模型,就是因为它的英文名字太流行了, 中文名字反而被忽略了。它诞生于20世纪80年代,原本是为桌面应用程序建立起来的一个框架,现在反而在Web应用中大放异彩(其实也可以把B/S认为是C/S的瘦化结构),MVC框架的目的是通过控制器C将模型M(代表的是业务数据和业务逻辑)和视图V(人机交互的界面)实现代码分离,从而使同一个逻辑或行为或数据可以具有不同的表现形式,或者是同样的应用逻辑共享相同、不同视图。比如,可以用IE浏览器访问某应用网站(页面格式遵守HTML标准),也可以用手机通过WAP浏览器访问(页面格式遵守WML格式),对MVC框架来说,后台的程序(也就是模型)不用做任何修改,只是使用的视图不同而已。MVC框架如图37-1所示。
![image-20211001213320931]()
图37-1 MVC框架示意图
该框架是Model2的结构。MVC框架有两个版本,一个是Model1,也就是MVC的第一个版本,它的视图中存在着大量的流程控制和代码开发,也就是控制器和视图还具有部分的耦合。也有人不认为Model1属于MVC框架,那也说得通,因为在JSP页面中融合了控制器和视图的功能,这其实就是早期的开发模式,开发一堆的JSP页面,然后再开发一堆的JavaBean,JavaBean就是模型了,它只是把JSP和JavaBean拆分开了。Model2版本则提倡视图和模型的彻底分离,视图仅仅负责展示服务,不再参与业务的行为和数据处理。我们举例来说明MVC框架是如何图37-1 MVC框架示意图控制器(Controller)视图(View)模型 (Model)第37章运行的。
在做Web开发时,例如开发一个数据展示界面,从一张表中把数据全部读出,然后展示到页面上,也是一个简单的表格,其中页面展示的格式就是视图V,怎么从数据库中取得数据则是模型M,那控制器C是做什么的呢?它负责把接收的浏览器的请求转发通知模型M处理,然后组合视图V,最终反馈一个带数据的视图到用户端,数据处理流程如图37-2所示。
![image-20211001213507728]()
图37-2 MVC框架的逻辑流
浏览器通过HTTP协议发出数据请求①,由控制器接收请求,通过路径②委托给数据模型处理,模型通过与逻辑层和持久层的交互(路径③④),把处理结果反馈给控制器(路径 ⑤),控制器根据结果组装视图(路径⑥⑦),并最终反馈给浏览器可以接受的HTML数据 (路径⑧)。整体MVC框架还是比较简单的,但它带来的优点非常多。
一个模型可以有多个视图,比如同样是一批数据,可以是柱状展示,也可以是条形展示,还可以是波形展示。同样,多个模型也可以共享一个视图,同样是一个登录界面,不同用户看到的菜单数量(模型中的数据)不同,或者不同业务权限级别的用户在同一个视图中展示。
因为模型和视图分离,两者没有耦合关系,所以可以独立地扩展和修改而不会产生相互影响。
模型和视图分离,可以使各个开发人员自由发挥,做视图的人员和开发模型的人员可以制订自己的计划,然后在控制器的协作下实现完整的应用逻辑。
MVC框架还有很多优点,本章主要不是讲解MVC技术,主要是通过讲解设计MVC框架 来说明设计模式该怎么应用,所以想了解更详细的MVC框架信息请自行查阅资料。
37.1.1 MVC的系统架构
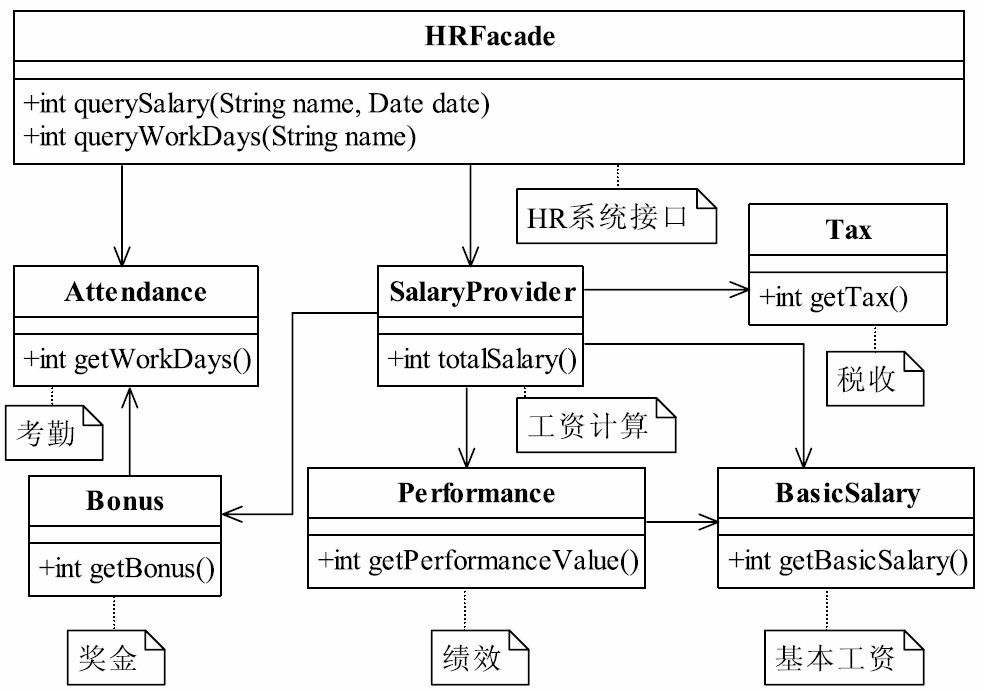
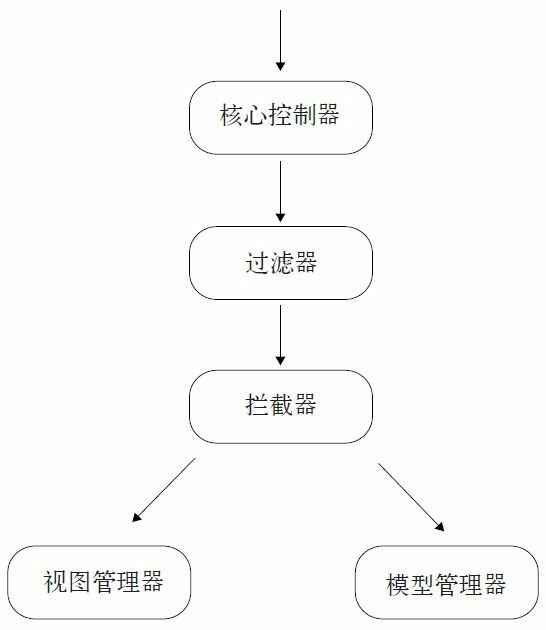
我们设计的MVC框架包含以下模块:核心控制器(FilterDispatcher)、拦截器 (Interceptor)、过滤器(Filter)、模型管理器(Model Action)、视图管理器(View Provider)等,基本上一个MVC框架上常用的功能我们都具备了,系统架构如图37-3所示。
![image-20211001213719199]()
图37-3 MVC系统架构
各个模块的职责如下:
MVC框架的入口,负责接收和反馈HTTP请求。
Servlet容器内的过滤器,实现对数据的过滤处理。由于它是容器内的,因此必须依靠容 器才能运行,它是容器的一项功能,与容器息息相关,本章就不详细讲述了。
对进出模型的数据进行过滤,它不依赖系统容器,只过滤MVC框架内的业务数据。
提供一个模型框架,该框架内的所有业务操作都应该是无状态的,不关心容器对象,例如Session、线程池等。
管理所有的视图,例如提供多语言的视图等。
它其实就是一大堆的辅助管理工具,比如文件管理、对象管理等。
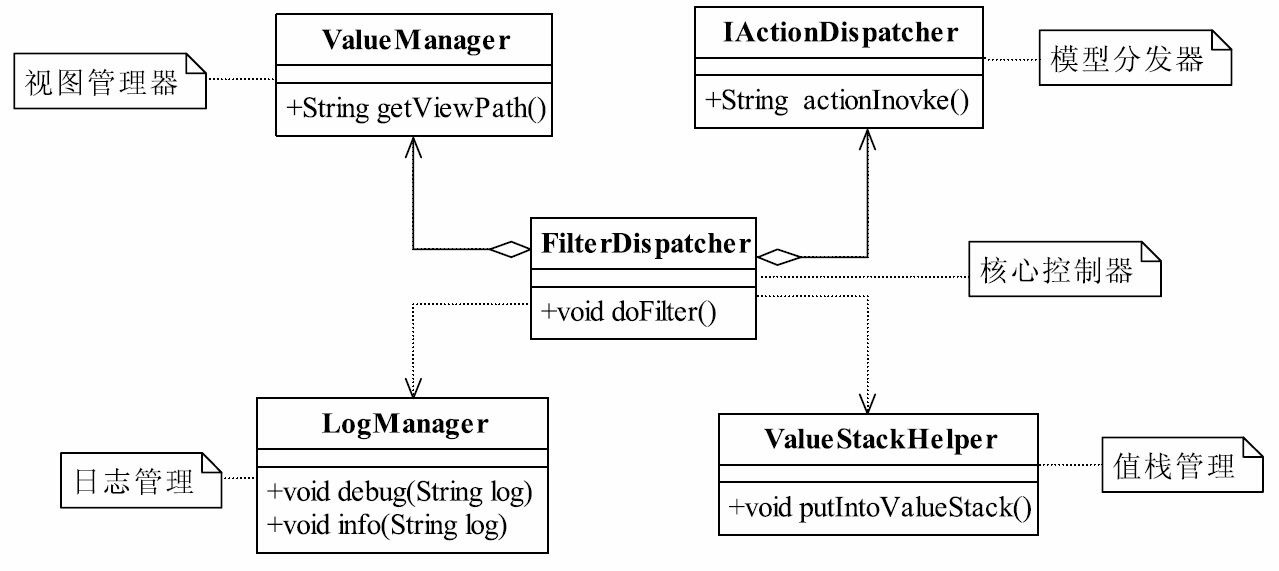
在我们的MVC框架中,核心控制器是最重要的,我们就先从它着手。核心控制器使用了Servlet容器的过滤器技术,需要编写一个过滤器,所有进入MVC框架的请求都需要经过核心控制器的转发,类图如图37-4所示。
![image-20211001213950390]()
图37-4 核心控制器类图
由于类图中的部分输入参数类型较长,省略了,请读者仔细看代码。首先阅读FilterDispatcher代码,如代码清单37-1所示。
代码清单37-1 核心控制器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| public class FilterDispatcher implements Filter {
private ValueStackHelper valueStackHelper = new ValueStackHelper();
IActionDispather actionDispatcher = new ActionDispatcher();
public void destroy() {
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest)request;
HttpServletResponse res = (HttpServletResponse)response;
chain.doFilter(req, res);
String actionName = getActionNameFromURI(req);
ViewManager viewManager = new ViewManager(actionName);
ValueStack valueStack = valueStackHelper.putIntoStack(req);
String result =actionDispatcher.actionInvoke(actionName);
String viewPath = viewManager.getViewPath(result);
RequestDispatcher rd = req.getRequestDispatcher(viewPath);
rd.forward(req, res);
}
public void init(FilterConfig arg0) throws ServletException {
}
private String getActionNameFromURI(HttpServletRequest req){
String path = (String) req.getRequestURI();
String actionName = path.substring(path.lastIndexOf("/") + 1, path.lastIndexOf("."));
return actionName;
}
}
|
我们按照系统的执行顺序来讲解,首先在容器的配置文件中需要配置该过滤器,以tomcat为例,配置如代码清单37-2所示。
代码清单37-2 核心控制器的配置
1
2
3
4
5
6
7
8
9
10
11
12
| <?xml version="1.0" encoding="UTF-8"?>
<web-app>
<filter>
<display-name>FilterDispatcher</display-name>
<filter-name>FilterDispatcher</filter-name>
<filter-class>{包名}.FilterDispatcher</filter-class>
</filter>
<filter-mapping>
<filter-name>FilterDispatcher</filter-name>
<url-pattern>*.do</url-pattern>
</filter-mapping>
</web-app>
|
在这里定义了对所有以.do结尾的请求进行拦截,拦截后由FilterDispatcher的doFilter方法处理。过滤器是在启动时自动初始化,初始化完毕后立刻调用inti方法,在init方法中我们做了两件事情。
所有的Action与视图的对应关系是在配置文件中配置的,因此若配置文件出错,该应用应该停止响应,这就需要在启动时对XML文件进行完整性检查和语法分析。
配置文件随时都可以修改,但是它修改后不应该需要重新启动应用才能生效,否则对系统的正常运行有非常大的影响,因此这里要使用到Listener(监听)行为了。
init方法需要做的这两件事情是非常重要的,而且都还包含了几种不同的设计模式。首 先我们来看检查XML配置文件如何实现。先看我们定义的XML格式(框架中应该定义一个 DTD文件,XML文件的模板,读者可以自行实现),如代码清单37-3所示。
代码清单37-3 XML配置文件
1
2
3
4
5
6
7
| <?xml version="1.0" encoding="UTF-8"?>
<mvc>
<action name="loginAction" class="{类名全路径}" method="execute">
<result name="success">/index2.jsp</result>
<result name="fail">/index.jsp</result>
</action>
</mvc>
|
读者思考一下该怎么检查这个XML文件,有两个不同的检查策略:一是检查XML文件的语法是否正确;二是框架逻辑检查,这是什么意思呢?比如我们在XML文件中配置了一个类A,它只有一个方法methodA,在method中编写的配置文件为method=”methoda”,方法名写错了,那这样的配置是肯定不能运行的,需要框架逻辑检查把它揪出来。这两种不同的算法是完全可以替换的,而且很有必要替换,逻辑检查在应用启动的时候需要对所有的类进行过滤处理,牺牲的是效率,这在测试机上没有问题,在生产机上要花20分钟才能把一个应用启动起来,在分秒必争的业务系统中这是不允许的,因此就要求该算法可以退休,想用的时候 (测试机环境)就用,不想用的时候(生产环境)就不用,想到什么模式了吗?策略模式, 这两个算法都是对同样的源文件进行检查,只是算法不同,当然可以相互替换了。类图比较简单,就不再画了,我们直接看代码,抽象策略如代码清单37-4所示。
代码清单37-4 XML文件校验
1
2
3
4
| public interface IXmlValidate {
public boolean validate(String xmlPath);
}
|
根据一个指定的路径,对XML进行校验,返回校验结果。普通XML校验如代码清单37-5 所示。
代码清单37-5 普通XML校验
1
2
3
4
5
6
| public class CommonXmlValidate implements IXmlValidate {
public boolean validate(String xmlPath) {
return false;
}
}
|
由于读写XML文件一般使用DOM4J或者JDOM,都提供对XML文件的语法校验功能,不符合XML语法(比如一个节点少写了结束标志</node>)的文件是不能解析的,读者可以在自己编写框架时使用该类型工具。
框架的逻辑算法如代码清单37-6所示。
代码清单37-6 框架逻辑校验
1
2
3
4
5
6
| public class LogicXmlValidate implements IXmlValidate {
public boolean validate(String xmlPath) {
return false;
}
}
|
逻辑校验相对比较复杂,它的逻辑流程如下:
- 读取XML文件。
- 使用反射技术初始化一个对象(配置文件中的class属性值)。
- 检查是否存在配置文件中配置的方法。
- 检查方法的返回值是否是String,并且无输入参数,同时必须继承指定类或接口。
逻辑校验需要把所有的对象都初始化一遍,在Action类较多的情况下,效率较低,但它可以提前发现出现访问异常的情况,把问题解决在萌芽状态。我们继续来看两个策略的场景类,如代码清单37-7所示。
代码清单37-7 策略的场景类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class Checker {
private IXmlValidate validate;
String xmlPath;
public Checker(IXmlValidate _validate){
this.validate = _validate;
}
public void setXmlPath(String _xmlPath){
this.xmlPath = _xmlPath;
}
public boolean check(){
return validate.validate(xmlPath);
}
}
|
与通用策略模式稍有不同,每个模式在实际应用环境中都有其个性,很少出现完全照搬一个模式的情况,灵活应用设计模式才是关键。
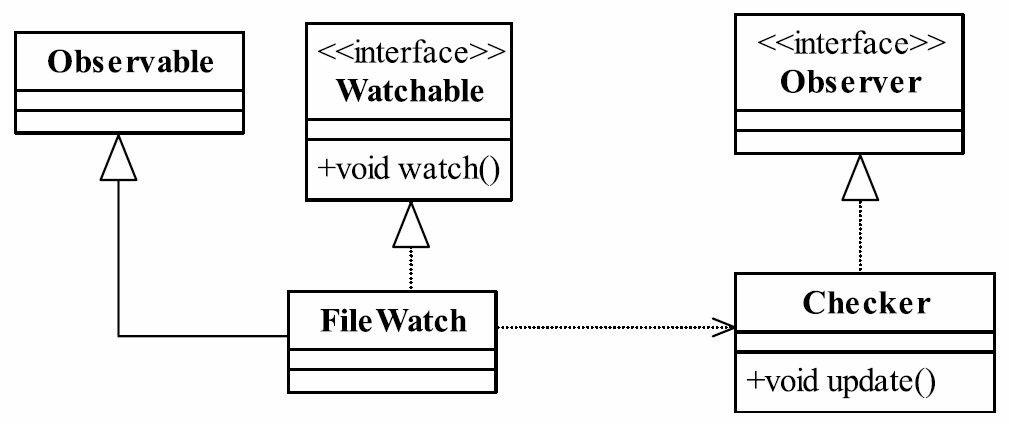
在FilterDispatcher的init方法中,我们刚刚说它有两个职责:第一个职责是XML文件校验,这个我们完成了;第二个职责是启动监控程序。问题是要监控什么呢?监控XML有没有被修改,如果修改了就立刻通知校验程序对它进行校验。这就又用到了观察者模式:发现文件被修改,它立刻通知检查者处理,该片段的类图如图37-5所示。
![image-20211001215149343]()
图37-5 XML文件监控类图
为什么要在这里定义一个Watchable接口呢?它表示所有可以监视的资源,比如数据库、日志文件、磁盘空间等。我们来看代码,监听接口如代码清单37-8所示。
代码清单37-8 监听接口
1
2
3
4
| public interface Watchable {
public void watch();
}
|
文件监听者是观察者模式的被观察者,它一旦发现文件发生变化立刻通知观察者,如代码清单37-9所示。
代码清单37-9 文件监听者
1
2
3
4
5
6
7
8
9
10
11
| public class FileWatcher extends Observable implements Watchable{
private boolean isReload = false;
public void watch(){
super.addObserver(new Checker());
super.setChanged();
super.notifyObservers(isReload);
}
}
|
由于框架是在操作系统之上运行的,文件变化时操作系统是不会通知应用系统的,因此我们能做的就是启动一个线程监视一批文件,发现文件改变了,立刻通知相关的处理者,它虽然有时间延迟,但对于一个应用框架来说是非常有必要的,避免了重启应用才能使配置生效的情况。
读者可能很疑惑,这种死循环的监控方式会不会对性能产生影响,答案是不会!为什么呢?
检查一个文件的时间一般是毫秒级的,相对于我们设置的运行周期(比如15秒执行一次)是一个非常微小的运行时间,对应用不会产生任何影响。大家都在使用Log4j进行日志处理,它有一个线程是每5秒检查一次日志是否满,大家觉得性能受影响了吗?基本上性能影响可以忽略不计。
由于Checker还要作为观察者,因此它要实现Observer接口,同时实现update方法,如代码清单37-10所示。
代码清单37-10 修正后的检查者
1
2
3
4
5
6
| public class Checker implements Observer{
public void update(Observable arg0, Object arg1) {
arg1 = check();
}
}
|
到此为止,我们把init方法已经讲解完毕,它是在容器初始化时调用。有一个HTTP请求发送过来,容器调用我们编写的doFilter方法。仔细看一下我们的代码,其中有这样一句话:Chain.doFilter(req,res),这句话是什么意思呢?是说让后续的过滤器先运行,等它们运行完毕后该过滤器再运行,应该想到这是一个责任链模式,它的类型是FilterChain。Servlet 容器把所有的过滤器组合在一起形成了一个过滤器链,它是怎么做到的呢?容器启动的时候,把所有的过滤器都初始化完毕,然后根据它们在web.xml中的配置顺序,从上向下组装一个过滤器链。注意所有的过滤器都必须实现Filter接口,这是建立过滤器链的首要前提。
我们再回过头来仔细看看类图,是不是有点熟悉?对,类似于中介者模式,我们并没有把中介者传递到各个同事类,只是我们采用中介者模式的思想,把中介者的职责分发出去由各个同事类来处理。
37.1.2 模型管理器
模型管理器是整个MVC框架的难点,在这里我们会看到非常多的设计模式。我们在核心控制器的类图中看到有一个IActionDispatcher接口,它实现的模型行为分发是一个门面模式,如代码清单37-11所示。
代码清单37-11 模型行为分发接口
1
2
3
4
| public interface IActionDispather {
public String actionInvoke(String actionName);
}
|
它的职责非常简单,得到actionName就执行,熟悉Struts的读者可能很清楚这个方法是非常复杂的,它要从配置文件中找到执行对象,然后执行方法,还要考虑值栈、异常等,非常复杂。我们这里就有一个方法,它对外提供一个门面,所有的访问都是通过该门面来完成, 其实现类如代码清单37-12所示。
代码清单37-12 模型分发实现
1
2
3
4
5
6
7
8
9
10
11
| public class ActionDispather implements IActionDispather {
private ActionManager actionManager = new ActionManager();
private ArrayList<Interceptors> listInterceptors = InterceptorFactory.createInterceptors();
public String actionInvoke(String actionName) {
return actionManager.execAction(actionName);
}
}
|
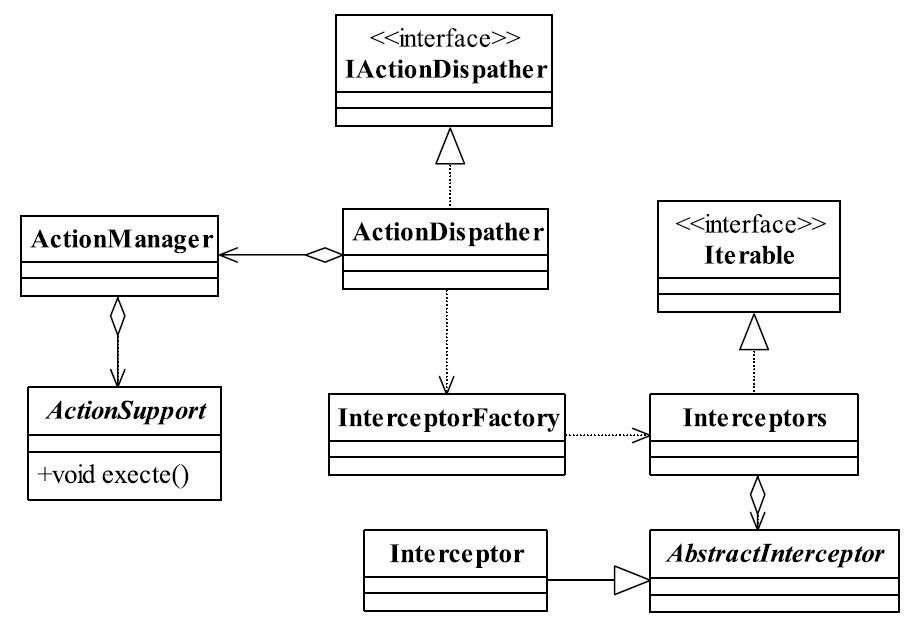
它是一个非常简单的类,对外部提供统一封装好的行为。模型管理器的类图如图37-6所示。
首先说ActionManager类,它负责管理所有的行为类Action,那就必须定义一个行为类的接口或抽象类,如代码清单37-13所示。
代码清单37-13 抽象Action
1
2
3
4
5
6
7
8
| public abstract class ActionSupport {
public final static String SUCCESS = "success";
public final static String FAIL = "fail";
public String execute(){
return SUCCESS;
}
}
|
![image-20211001215608539]()
图37-6 模型管理器类图
抽象的ActionSupport类看起来很简单,其实它可不简单,所有的模型行为都继承该类, 它之所以提供一个默认的execute方法,是因为在xml的配置文件中,可以省略掉method="XXX"这句话,默认就是调用该方法。它还有一个非常重要的行为:对象映射,把HTTP传递过来的字符串映射到一个业务对象上,我们会在值栈中详细讲解。
读者可能很疑惑,Action的操作是需要获得环境数据的,比如HTTPServletRequest的数据,还有系统中的Session数据,单单一个ActionManager如何获得这些数据呢?通过值栈,在值栈中保存着该Action需要的所有数据。
我们再来看ActionManager类,如代码清单37-14所示。
代码清单37-14 Action管理类
1
2
3
4
5
6
| public class ActionManager {
public String execAction(String actionName){
return null;
}
}
|
就这么简单吗?非也,其中的参数actionName指xml配置中的name属性值,它与从HTTP 传递过来的请求对象是一致的,根据HTTP传递过来的actionName在xml文件中查找对应的节点(Node),然后就可以获取到该类的名称和方法,通过动态代理的方式执行该方法,在这里我们使用到了代理模式。
有读者可能听说过反射是影响性能的,它提供解释型操作。是这样的,但是实际应用还没有这么高的要求,把数据库设计得优秀一点,系统架构多考虑一点,提升的性能远比这个多。
然后我们再来看拦截器,拦截器和过滤器的区别就是:拦截器可以脱离容器(J2EE容器)运行,而过滤器不行。拦截器的目的是对数据和行为进行过滤,符合条件的才可以执行Action,或者是在Action执行完毕后,调用拦截器进行回收处理。我们定义一个抽象的拦截器,如代码清单37-15所示。
代码清单37-15 抽象拦截器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public abstract class AbstractInterceptor {
private ValueStack valueStack = ValueStackHelper.getValueStack();
private int type =0;
protected ValueStack getValueStack(){
return valueStack;
}
public final void exec(){
}
protected abstract void setType(int type);
protected abstract void intercept();
}
|
这怎么和Struts的拦截器不相同呀!是的,Struts的拦截器的拦截方法intercept是要接收一个ActionInvocation对象,这里却没有,我们主要是讲解模式,是为了技术实现,而类似Struts 的MVC框架属于工业级别的应用框架,考虑了太多的外界因素。拦截器分为三种。
在Action调用前执行,对Action需要的场景数据进行过滤或重构。
在Action调用后执行,负责回收场景,或对Action的后续事务进行处理。
在Action调用前后都执行。
我们的框架在这里使用了一个模板方法模式,开发者继承AbstractInterceptor后,只要完成两个职责即可:定义拦截类型(setType)和实现拦截器要拦截的方法(intercept),不用考虑它到底如何调用ActionInvocation,相对来说简单又实用。
有拦截器就肯定有拦截器链,多个拦截器组合在一起就成了拦截器链,如代码清单37- 16所示。
代码清单37-16 拦截器链
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class Interceptors implements Iterable<AbstractInterceptor> {
public Interceptors(ArrayList<AbstractInterceptor> list){
}
public Iterator<AbstractInterceptor> iterator() {
return null;
}
public void intercept(){
}
}
|
它实现了Iterable接口,提供了一个方便遍历拦截器的方法,这是迭代器模式。同时,由于是一个链结构,我们就想到了责任链,这里确实也是一个责任链模式,只是核心控制器上的过滤链是Servlet容器自己实现的,而拦截器链则需要我们自己编码实现。代码不复杂,读者可以参考责任链章节。
这里还有两个很有意思的方法。我们来看构造函数,它通过一个容纳有拦截器的动态数组生成一个拦截器链,它是一个自激行为,在XML文件中配置一个拦截器,其中包含多个拦截器,我们的构造函数就是这样的用途,自己建立一条链,而不是父类或者高层模块。再看intercept方法,链中每个节点都是一个拦截器,都有一个intercept方法,拦截器链中的intercept方法行为是委托第一个节点拦截器的intercept方法,然后所有的拦截器都会按照顺序执行一遍,这一点和我们的责任链模式是不同的,责任链模式是只要有节点处理就可以认为是结束,后续节点可以不再参与处理。
Struts还实现了方法拦截器,只要继承MethodFilterInterceptor即可,主要使用了反射技 术,有兴趣的话可以看看源代码。注意我们这里使用了拦截器链而不像Struts那样是拦截器 栈,一字之差,系统设计差别可就大了。
注意 拦截器是会影响系统性能的,所有的Action在执行前后都会被拦截器过滤一遍,即使不符合拦截条件的也会被检查一遍,所以非必要情况不要使用拦截器。
由于在XML配置文档中有太多的拦截器链,因此需要有一个工厂来创建它,否则太烦琐。如代码清单37-17所示。
代码清单37-17 拦截器链工厂
1
2
3
4
5
6
| public class InterceptorFactory {
public static ArrayList<Interceptors> createInterceptors(){
return null;
}
}
|
它的作用是根据配置文件一次性地创建出所有的拦截器,很简单的工厂方法模式。如果读者还记得我们刚刚讲的配置文件更新问题的话,应该想到这里也应该有一个观察者,配置文件修改了,拦截器链当然也要重建了,确实应该有这样一个观察者,读者可以自行思考如何实现。
37.1.3 值栈
值栈按道理说应该很简单,就是把HTTP传递过来的String字符串压到堆栈中。听起来很简单,实现起来就比较有难度了,它要完成两个职责。
不仅仅是出栈、入栈这么简单,它要管理栈中数据,同时还要允许前置拦截器对栈中数据进行修改,限制后置拦截器对栈的修改,还要把栈中数据与HTTPServletRequest中的数据建立关联。
从HTTP传递过来的数据都是字符串结构,那怎么才能转化成一个业务对象呢?比如在页面上有一个登录框,输入用户名(userName)和密码(password)。提交到MVC框架中怎么才能转为一个User对象呢?这也是值栈要完成的职责。
这里说一下值映射,怎么实现一个值的映射,这也是一个反射操作的结果。首先是HTTP传递过来的参数名称中要明确映射到哪一个对象,例如使用点号(.)区分,点号前是对象名称,点号后是属性名,如此规定后就可以轻松地处理了。由于使用的模式较少,这里就不再赘述。读者若有兴趣可以考虑使用一些开源工具,比如dozer等。
37.1.4 视图管理器
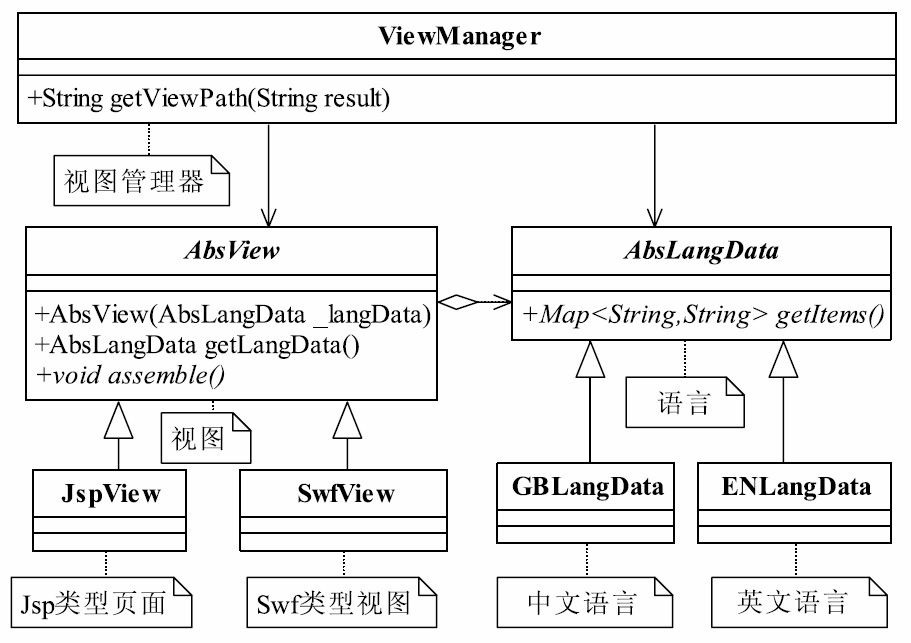
视图管理器的功能很单一,按照模型指定的要求返回视图,在这里用到的主要模式就是桥梁模式,如果大家做过多语言的开发就非常清楚了,比如一个外部网站,提供中日英三种语言版本,我们不可能每个语言都写一套页面吧。一般是定义一个语言资源文件,然后视图根据不同的语言环境加载不同的语言。我们先来说视图,它包含三部分。
比如图片放在什么地方,字体大小是什么样子,菜单应该放置在什么地方,这部分工作是由前台人员开发的,不涉及业务逻辑和业务数据。
它指的是在一个固定场景下不发生变化但在异构场景中发生变化的元素,其中语言就属于动态页面元素,还有为使用不同浏览器而开发的代码。比如浏览器IE、Firefox、Chrome 等,虽然基本上都是符合HTML,但是还有一些细节差异,特别是在JavaScript的处理方面, 稍不注意就可能产生灾难。
由模型产生的数据,它对视图来说是结构固定,并可反复加载。
在这三部分中,静态页面是完全静态的,动态页面元素是稍微有点动感,动态数据完全是多变的(数据结构不发生变化,否则页面无法展现)。把动态数据融入到静态页面中比较容易,已经在配置文件中指定要把模型中的数据放到哪个页面中,现在的问题是怎么把动态页面元素融入到静态页面中。静态页面有很多,语言类型也有很多,怎么融合在一起提供给浏览器访问呢?
桥梁模式可以解决用什么笔(圆珠笔、铅笔)和画什么图形(圆形、方形)的问题,我们遇到的问题与此场景类似。先看类图,如图37-7所示。
![image-20211001220257520]()
图37-7 视图与语言类图
大家还记得Struts是怎么配置多语言的文件吗?我们采用类似的结构,如代码清单37-18 所示。
代码清单37-18 资源配置文件
英文配置菜单与此类似,它的结构就是一个Map类型,我们把它读入到Map中,抽象类如代码清单37-19所示。
代码清单37-19 抽象语言
1
2
3
4
| public abstract class AbsLangData {
public abstract Map<String,String> getItems();
}
|
getItems方法是获得一种语言下的所有配置。我们来看中文语言包,如代码清单37-20所 示。
代码清单37-20 中文语言
1
2
3
4
5
6
7
8
9
10
11
| public class GBLangData extends AbsLangData {
@Override
public Map<String, String> getItems() {
return null;
}
}
|
英文语言如代码清单37-21所示。
代码清单37-21 英文语言
1
2
3
4
5
6
7
8
9
10
11
| public class ENLangData extends AbsLangData {
@Override
public Map<String, String> getItems() {
return null;
}
}
|
视图分为两种类图,一种是需要直接替换资源文件的视图,比如JSP文件,框架直接把语言包中的资源项替换掉JSP中的条目即可,把{title}替换为“标题”,把{menu}替换为“菜单”,替换后存在框架的缓存目录中,提高系统的访问效率。另一种视图是不能替换的,比如SWF文件,它的资源可以通过类似HTTP传递参数的形式传递,重写一个URL即可。我们首先来看抽象视图,如代码清单37-22所示。
代码清单37-22 抽象视图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public abstract class AbsView {
private AbsLangData langData;
public AbsView(AbsLangData _langData){
this.langData = _langData;
}
public AbsLangData getLangData(){
return langData;
}
public String getURI(){
return null;
}
public abstract void assemble();
}
|
JSP视图是需要替换资源项,如代码清单37-23所示。
代码清单37-23 JSP视图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class JspView extends AbsView {
public JspView(AbsLangData _langData){
super(_langData);
}
@Override
public void assemble() {
Map<String,String> langMap = getLangData().getItems();
for(String key:langMap.keySet()){
}
}
}
|
SWF文件是不能替换的,采用重写URL的方式,如代码清单37-24所示。
代码清单37-24 SWF视图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class SwfView extends AbsView {
public SwfView(AbsLangData _langData){
super(_langData);
}
@Override
public void assemble() {
Map<String,String> langMap = getLangData().getItems();
for(String key:langMap.keySet()){
}
}
}
|
ViewManager是一个视图模块的入口,所有的访问都是通过它传递进来的,如代码清单 37-25所示。
代码清单37-25 视图管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class ViewManager {
private String actionName;
private ValueStack valueStack = ValueStackHelper.getValueStack();
public ViewManager(String _actionName){
this.actionName = _actionName;
}
public String getViewPath(String result){
AbsLangData langData = new GBLangData();
AbsView view = new JspView(langData);
return view.getURI();
}
}
|
通过桥梁模式我们把不同的语言和不同类型的视图结合起来,共同提供一个多语言的应用系统,即使以后增加语言也非常容易扩展。
37.1.5 工具类
每个框架或项目都有大量的工具类,MVC框架也不例外。先来看操作XML文件的工具类,不可能自己读写XML文件,我们使用DOM4J来实现,它在大文件的处理上性能很有优势,而且比较简单,架构也非常优秀。
使用DOM4J从XML文件中读出的对象是节点(Node)、元素(Element)、属性(Attribute)等,这些对象还是比较容易理解的,但是不能保证一个开发组的人对这些都了解,因此需要把它转换成每个开发成员都理解的对象,比如我们处理这样一段XML代码,如代码清单37-26所示。
代码清单37-26 XML文件片段
1
2
3
4
| <action name="loginAction" class="{类名全路径}" method="execute">
<result name="success">/index2.jsp</result>
<result name="fail">/index.jsp</result>
</action>
|
使用DOM4J查找到该节点是一个Node对象,如果要取得属性,就需要转换为一个元素 (Element)对象,这不是每个开发成员都能理解的,于是给架构师提出的问题就是:如何把一个DOM4J对象转换成自己设计的对象。答案是适配器模式,我们首先定义一个Action节点类,如代码清单37-27所示。
代码清单37-27 Action节点类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public abstract class ActionNode {
private String actionName;
private String actionClass;
private String methodName = "excuete";
private String view;
public String getActionName() {
return actionName;
}
public String getActionClass() {
return actionClass;
}
public String getMethodName() {
return methodName;
}
public abstract String getView(String Result);
}
|
它是一个抽象类,其中的getView是一个抽象方法,是根据执行结果查找到视图路径。 只要编写一个适配器就可以把Elemet对象转为Action节点,如代码清单37-28所示。
代码清单37-28 Action节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public class XmlActionNode extends ActionNode {
private Element el;
public XmlActionNode(Element _el){
this.el = _el;
}
@Override
public String getActionName(){
return getAttValue("name");
}
@Override
public String getActionClass(){
return getAttValue("class");
}
@Override
public String getMethodName(){
return getAttValue("method");
}
public String getView(String result){
ViewPathVisitor visitor = new ViewPathVisitor("success");
el.accept(visitor);
return visitor.getViewPath();
}
private String getAttValue(String attName){
Attribute att = el.attribute(attName);
return att.getText();
}
}
|
这是一个对象适配器,传递进来一个Element对象,把它转换为ActionNode对象,这样设计以后,系统开发人员就不用考虑开源工具对系统的影响,屏蔽了工具系统的影响,这是一个典型的适配器模式应用。
不知道读者是否注意到getView方法,它使用了一个访问者模式,这是DOM4J提供的一个非常优秀的API接口,传递进去一个访问者就可以遍历出我们需要的对象。我们来看自己定义的访问者,如代码清单37-29所示。
代码清单37-29 访问者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class ViewPathVisitor extends VisitorSupport {
private String viewPath;
private String result;
public ViewPathVisitor(String _result){
result = _result;
}
@Override
public void visit(Element el){
Attribute att = el.attribute("name");
if(att != null){
if(att.getName().equals("name") && att.getText().equals(result)){
viewPath = el.getText();
}
}
}
public String getViewPath(){
return viewPath;
}
}
|
DOM4J提供了VisitorSupport抽象接口,可以接受元素、节点、属性等访问者。我们这里 接受了一个元素访问者,对所有的元素过滤一遍,然后找到自己需要的元素,非常强大!
我们继续分析,在IoC容器中都会区分对象是单例模式还是多例模式。想想我们的框架,每个HTTP请求都会产生一个线程,如果我们的Action初始化的时候是单例模式会出现什么情况?当并发足够多的时候就会产生阻塞,性能会严重下降,在特殊情况下还会产生线程不安全,这时就需要考虑多例情况。那多例是如何处理呢?使用Clone技术,首先在系统启动时初始化所有的Action,然后每过来一个请求就拷贝一个Action,减少了初始化对象的性能消耗。典型的原型模式,但问题也同时产生了,并发较多时,就可能会产生内存溢出的情况,内存不够用了!于是享元模式就可以上场了,建立一个对象池以容纳足够多的对象。