28.1 内存溢出,司空见惯 下午,我正在开会中,老大推门进来。
“三儿,出来一下。”
我刚出会议室门口,老大就发话了。
“郎当(姓朗,顺口就叫郎当)的那个报考系统又crash了一台机器,两天已经宕了4次 了,你这边还有紧急的事情没有?……没有,那赶快过去顶一下,就运行三天的程序,两天 宕了4次,还怎么玩?!”
我马上收拾东西,冲到马路上拦了出租车,同时打电话给郎当。
“三哥,厂商人员已经定位出了,OutOfMemory内存溢出,没查到有内存泄漏的情况,现 在还在跟踪……是突然暴涨的,都是在繁忙期出现问题的……”
内存溢出对Java应用来说实在是太平常了,有以下两种可能。
无意识的代码缺陷,导致内存泄漏,JVM不能获得连续的内存空间。
代码写得很烂,产生的对象太多,内存被耗尽。现在的情况是没有内存泄漏,那只有一种原因——代码太差把内存耗尽。
到现场后,郎当给我介绍了一下系统情况。该系统是一个报考系统,其中有一个模块负责社会人员报名,该模块对全国的考试人员只开放3天,并且限制报考人员数量。第一天9点开始报考,系统慢得像蜗牛,基本上都不能访问,后来设置了HTTP Server的并发数量,稍有缓解,40分钟后宕了一台机器,10分钟后,又挂了一台,下午3点又挂了一台,看样子晚上要让郎当去寺庙烧烧香了。
该系统一共有8台应用服务器,基本上CPU繁忙程度都在60%以上,HTTP的最大并发是2000,平均分配到每台应用服务器上没有太大的压力,于是怀疑是代码问题,然后详细了解了一下业务和数据流逻辑,基本的业务操作过程清楚了,先登录(没有账号的,则要先注册),登录后,需要填写以下信息:
考试科目,选择框。
考试地点,选择框,根据科目不同,列表不同。
准考证邮寄地址,输入框。
还有其他一堆信息,我们以这三者作为代表来讲解。信息填写完毕后,点击确认,报名就结束了。简单程序的业务逻辑也确实是这样,为什么出现Crash情况呢?那肯定是和压力有关系!
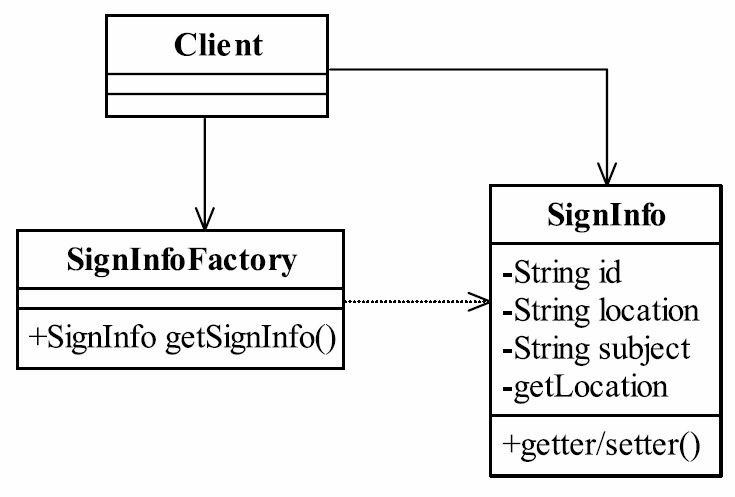
我们先把这个过程的静态类图画出来,如图28-1所示。
图28-1 报考系统类图
很简单的工厂方法模式,表现层通过工厂方法模式创建对象,然后传递给业务层和持久层,最终保存到数据库中,为什么要使用工厂方法模式而不用直接new一个对象呢?因为是在框架下编程,必须有一个对象工厂(ObjectFactory,Spring也有对象工厂)。我们先来看报考信息,如代码清单28-1所示。
代码清单28-1 报考信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class SignInfo { private String id; private String location; private String subject; private String postAddress; public String getId () { return id; } public void setId (String id) { this .id = id; } public String getLocation () { return location; } public void setLocation (String location) { this .location = location; } public String getSubject () { return subject; } public void setSubject (String subject) { this .subject = subject; } public String getPostAddress () { return postAddress; } public void setPostAddress (String postAddress) { this .postAddress = postAddress; } }
它是一个很简单的POJO对象(Plain Ordinary Java Object,简单Java对象)。我们再来看工厂类,如代码清单28-2所示。
代码清单28-2 报考信息工厂
1 2 3 4 5 6 public class SignInfoFactory { public static SignInfo getSignInfo () { return new SignInfo (); } }
工厂类就这么简单?非也,这是我们的教学代码,真实的ObjectFactory要复杂得多,主要是注入了部分Handler的管理。表现层是如何创建对象的,如代码清单28-3所示。
代码清单28-3 场景类
1 2 3 4 5 6 7 public class Client { public static void main (String[] args) { SignInfo signInfo = SignInfoFactory.getSignInfo(); } }
就这么简单,但是简单为什么会出现问题呢?而且这样写也没有问题呀,很标准的工厂方法模式,应该不会有大问题,然后又看了看系统厂商提供的分析报告,报告中指出:内存突然由800MB飙升到1.4GB,新的对象申请不到内存空间,于是出现OutOfMemory,同时报告中还列出宕机时刻内存中的对象,其中SignInfo类的对象就有400MB,疯子,绝对是疯子!报告都没有看嘛!
问题找到了,我拉郎当过来谈话,“厂商不是分析出原因了嘛,人家已经指出SignInfo类的对象占用了400MB多的内存,这是怎么回事?”
“三哥,这是很正常的,这么大的访问量,产生出这么多的SignInfo对象也是应该的,内 存中有这么多对象并不表示这些对象正在被使用呀,估计很大一部分还没有被回收而已,垃 圾回收器什么时候回收内存中的对象这是不确定的。你看,并发200多个,这可是并发数 量……”
我想了想,也确实是这么回事。既然已经定位是内存中对象太多,那就应该想到使用一种共享的技术减少对象数量,那怎么共享呢?
大家知道,对象池(Object Pool)的实现有很多开源工具,比如Apache的commons-pool 就是一个非常不错的池工具,我们暂时还用不到这种重量级的工具,我们自己来设计一个共享对象池,需要实现如下两个功能。
我们要定义一个池容器,在这个容器中容纳哪些对象。
我们要提供一个接口供客户端访问,池中有可用对象时,可以直接从池中获得,否则建立一个新的对象,并放置到池中。
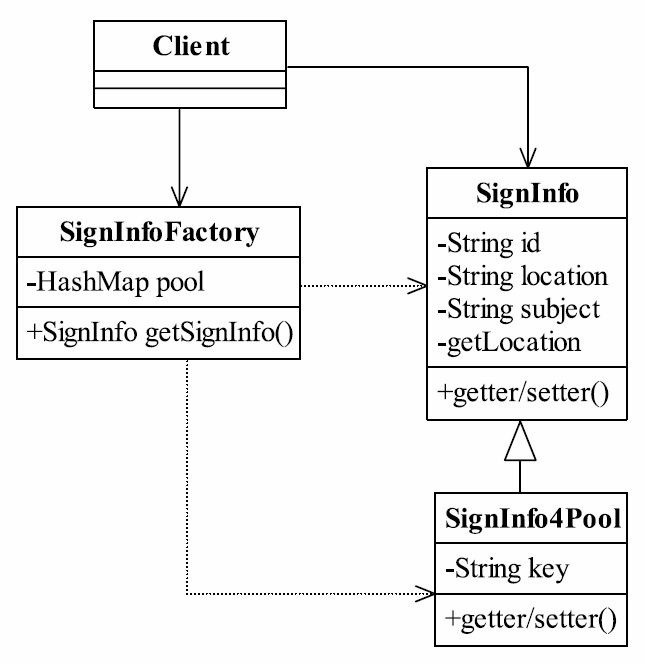
设计思路有了,那我们池中对象的标准是什么呢?你想想看,如果你把所有的对象都放到池中,那还有什么意义?内存早就给你撑爆了!这么多对象,必然有一些相同的属性值,如几十万SignInfo对象中,考试科目就4个,考试地点也就是30多个,其他的属性则是每个对象都不相同的,我们把对象的相同属性提取出来,不同的属性在系统内进行赋值处理,是不是就可以建立一个池了?话无须多说,我们以类图来表示,如图28-2所示。
图28-2 增加对象池的类图
做一个很小的改动,增加了一个子类,实现带缓冲池的对象建立,同时在工厂类上增加了一个容器对象HashMap,保存池中的所有对象。我们先来看产品子类,如代码清单28-4所示。
代码清单28-4 带对象池的报考信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class SignInfo4Pool extends SignInfo { private String key; public SignInfo4Pool (String _key) { this .key = _key; } public String getKey () { return key; } public void setKey (String key) { this .key = key; } }
很简单,就是增加了一个key值,为什么要增加key值?为什么要使用子类,而不在SignInfo类上做修改?好,我来给你解释为什么要这样做,我们刚刚已经分析了所有的SignInfo对象都有一些共同的属性:考试科目和考试地点,我们把这些共性提取出来作为所有对象的外部状态,在这个对象池中一个具体的外部状态只有一个对象。按照这个设计,我们定义key值的标准为:考试科目+考试地点的复合字符串作为唯一的池对象标准,也就是说在对象池中,一个key值唯一对应一个对象。
注意 在对象池中,对象一旦产生,必然有一个唯一的、可访问的状态标志该对象,而且池中的对象声明周期是由池容器决定,而不是由使用者决定的。
你可能马上就要提出了,为什么不建立一个新的类,包含subject和location两个属性作为外部状态呢?嗯,这是一个办法,但不是最好的办法,有两个原因:
修改的工作量太大,增加的这个类由谁来创建呢?同时,SignInfo类是否也要修改 呢?你不可能让两段相同的POJO程序同时出现在同一模块中吧!
性能问题,我们会在扩展模块中讲解。
说了这么多,我们还是继续来看程序,工厂类如代码清单28-5所示。
代码清单28-5 带对象池的工厂类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class SignInfoFactory { private static HashMap<String,SignInfo> pool = new HashMap <String,SignInfo>(); @Deprecated public static SignInfo () { return new SignInfo (); } public static SignInfo getSignInfo (String key) { SignInfo result = null ; if (!pool.containsKey(key)){ System.out.println(key + "----建立对象,并放置到池中" ); result = new SignInfo4Pool (key); pool.put(key, result); } else { result = pool.get(key); System.out.println(key +"---直接从池中取得" ); } return result; } }
方法都很简单,不多解释。读者需要注意一点的是@Deprecated注解,不要有删除投产中代码的念头,如果方法或类确实不再使用了,增加该注解,表示该方法或类已经过时,尽量不要再使用了,我们应该保持历史原貌,同时也有助于版本向下兼容,特别是在产品级研发中。
我们再来看看客户端是如何调用的,如代码清单28-6所示。
代码清单28-6 场景类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Client { public static void main (String[] args) { for (int i=0 ;i<4 ;i++){ String subject = "科目" + i; for (int j=0 ;j<30 ;j++){ String key = subject + "考试地点" +j; SignInfoFactory.getSignInfo(key); } } SignInfo signInfo = SignInfoFactory.getSignInfo("科目1考试地点1" ); } }
运行结果如下所示:
1 2 3 4 5 6 科目3考试地点25----建立对象,并放置到池中 科目3考试地点26----建立对象,并放置到池中 科目3考试地点27----建立对象,并放置到池中 科目3考试地点28----建立对象,并放置到池中 科目3考试地点29----建立对象,并放置到池中 科目1考试地点1---直接从池中取得
前面还有很多的对象创建提示语句,不再复制。通过这样的改造后,我们想想内存中有多少个SignInfo对象?是的,最多120个对象,相比之前几万个SignInfo对象优化了非常多。细心的读者可能注意到了SignInfo4Pool类基本上没有跑出我们的视线范围,仅仅在工厂方法中使用到了,尽量缩小变更引起的风险,想想看我们的改动是不是很小,只要在展示层中拼一个字符串,然后传递到工厂方法中就可以了。
通过这样的改造后,第三天系统运行得非常稳定,CPU占用率也下降了,而且以后再也没有出现类似问题,这就是享元模式的功劳。