21.4 组合模式的扩展
21.4.1 真实的组合模式
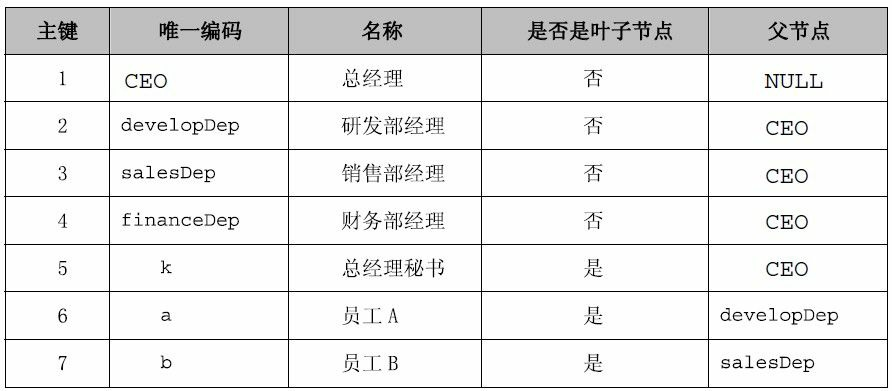
什么是真实的组合模式?就是你在实际项目中使用的组合模式,而不是仅仅依照书本上学习到的模式,它是“实践出真知”。在我们的例子中,经过精简后,确实是类、接口减少了很多,而且程序也简单很多,但是大家可能还是很迷茫,这个Client程序并没有改变多少呀,非常正确,树的组装是跑不了的,你要知道在项目中使用关系型数据库来存储这些信息,你可以从数据库中直接提取出哪些人要分配到树枝,哪些人要分配到树叶,树枝与树枝、树叶的关系等,这些都是由相关的业务人员维护到数据库中的,通常这里是把数据存放到一张单独的表中,表结构如图21-7所示。
![image-20210929172935715]()
图21-7 关系数据库中存储的树形结构
这张数据表定义了一个树形结构,我们要做的就是从数据库中把它读取出来,然后展现到前台上,用for循环加上递归就可以完成这个读取。用了数据库后,数据和逻辑已经在表中定义好了,我们直接读取放到树上就可以了,这个还是比较容易做的,大家不妨自己考虑一下。
这才是组合模式的真实引用,它依靠了关系数据库的非对象存储性能,非常方便地保存了一个树形结构。大家可以在项目中考虑采用,想想看现在还有哪个项目不使用关系型数据库呢?
21.4.2 透明的组合模式
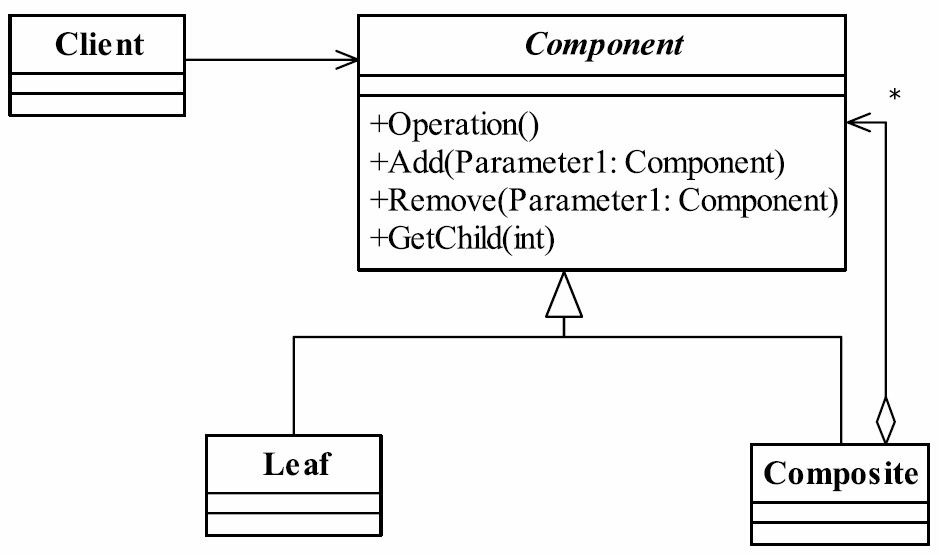
组合模式有两种不同的实现:透明模式和安全模式,我们上面讲的就是安全模式,那透明模式是什么样子呢?透明模式的通用类图,如图21-8所示。
![image-20210929173044473]()
图21-8 透明模式的通用类图
我们与图21-6所示的安全模式类图对比一下就非常清楚了,透明模式是把用来组合使用的方法放到抽象类中,比如add()、remove()以及getChildren等方法(顺便说一下,getChildren 一般返回的结果为Iterable的实现类,很多,大家可以看JDK的帮助),不管叶子对象还是树枝对象都有相同的结构,通过判断是getChildren的返回值确认是叶子节点还是树枝节点,如果处理不当,这个会在运行期出现问题,不是很建议的方式;安全模式就不同了,它是把树枝节点和树叶节点彻底分开,树枝节点单独拥有用来组合的方法,这种方法比较安全,我们的例子使用了安全模式。
由于透明模式的使用者还是比较多,我们也把它的通用源代码共享出来,首先看抽象构件,如代码清单21-22所示。
代码清单21-22 抽象构件
1
2
3
4
5
6
7
8
9
10
11
12
| public abstract class Component {
public void doSomething(){
}
public abstract void add(Component component);
public abstract void remove(Component component);
public abstract ArrayList<Component> getChildren();
}
|
抽象构件定义了树枝节点和树叶节点都必须具有的方法和属性,这样树枝节点的实现就不需要任何变化,如代码清单21-19所示。
树叶节点继承了Component抽象类,不想让它改变有点难,它必须实现三个抽象方法, 怎么办?好办,给个空方法,如代码清单21-23所示。
代码清单21-23 树叶节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class Leaf extends Component {
@Deprecated
public void add(Component component) throws UnsupportedOperationException{
throw new UnsupportedOperationException();
}
@Deprecated
public void remove(Component component)throws UnsupportedOperationException{
throw new UnsupportedOperationException();
}
@Deprecated
public ArrayList<Component> getChildren()throws UnsupportedOperationException{
throw new UnsupportedOperationException();
}
}
|
为什么要加个Deprecated注解呢?就是在编译器期告诉调用者,你可以调我这个方法, 但是可能出现错误哦,我已经告诉你“该方法已经失效”了,你还使用那在运行期也会抛出UnsupportedOperationException异常。
在透明模式下,遍历整个树形结构是比较容易的,不用进行强制类型转换,如代码清单21-24所示。
代码清单21-24 树结构遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class Client {
public static void display(Component root){
for(Component c:root.getChildren()){
if(c instanceof Leaf){
c.doSomething();
}
else{
display(c);
}
}
}
}
|
仅仅在遍历时不再进行牵制的类型转化了,其他的组装则没有任何变化。透明模式的好处就是它基本遵循了依赖倒转原则,方便系统进行扩展。
21.4.3 组合模式的遍历
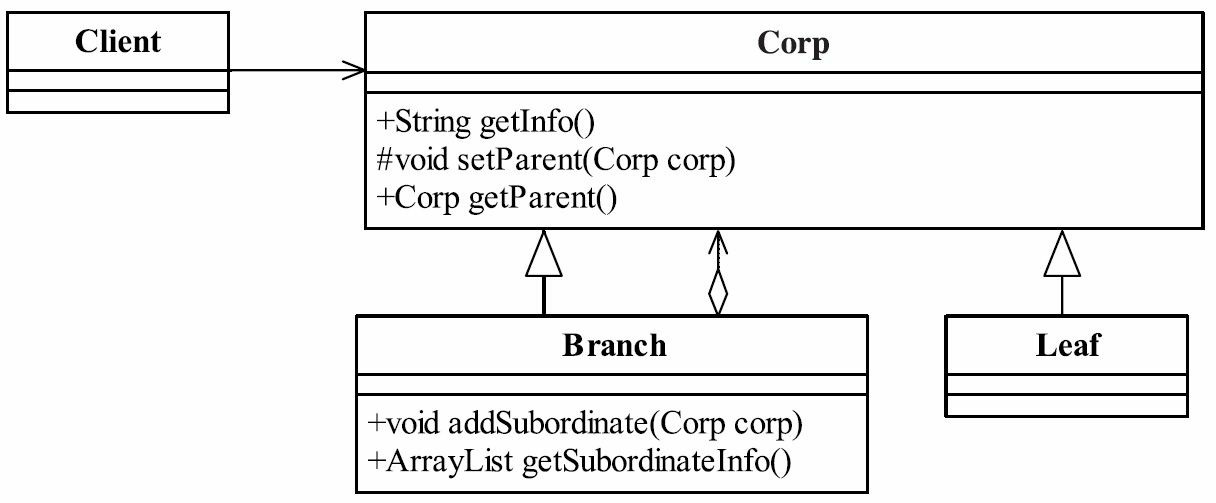
我们在上面也还提到了一个问题,就是树的遍历问题,从上到下遍历没有问题,但是我要是从下往上遍历呢?比如组织机构这棵树,我从中抽取一个用户,要找到它的上级有哪些,下级有哪些,怎么处理?想想,再想想!想出来了吧,我们对下答案,类图如图21-9所示。
![image-20210929173339475]()
图21-9 增加父查询的类图
看类图中,在Corp类中增加了两个方法,setParent是设置父节点是谁,getParent是查找父节点是谁,我们来看一下程序的改变,如代码清单21-25所示。
代码清单21-25 抽象构件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public abstract class Corp {
private String name = "";
private String position = "";
private int salary =0;
private Corp parent = null;
public Corp(String _name,String _position,int _salary){
this.name = _name;
this.position = _position;
this.salary = _salary;
}
public String getInfo(){
String info = "";
info = "姓名:" + this.name;
info = info + "\t职位:"+ this.position;
info = info + "\t薪水:" + this.salary;
return info;
}
protected void setParent(Corp _parent){
this.parent = _parent;
}
public Corp getParent(){
return this.parent;
}
}
|
就增加了粗体部分,然后我们再来看看树枝节点的改变,如代码清单21-26所示。
代码清单21-26 树枝构件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class Branch extends Corp {
ArrayList<Corp> subordinateList = new ArrayList<Corp>();
public Branch(String _name,String _position,int _salary){
super(_name,_position,_salary);
}
public void addSubordinate(Corp corp) {
corp.setParent(this);
this.subordinateList.add(corp);
}
public ArrayList<Corp> getSubordinate() {
return this.subordinateList;
}
}
|
增加了粗体部分。看懂程序了吗?甭管是树枝节点还是树叶节点,在每个节点都增加了一个属性:父节点对象,这样在树枝节点增加子节点或叶子节点是设置父节点,然后你看整棵树除了根节点外每个节点都有一个父节点,剩下的事情还不好处理吗?每个节点上都有父节点了,你要往上找,那就找呗!大家自己考虑一下,写个find方法,然后一步一步往上找,非常简单的方法,这里就不再赘述。
有了这个parent属性,什么后序遍历(从下往上找)、中序遍历(从中间某个环节往上或往下遍历)都解决了,这个就不多说了。
再提一个问题,树叶节点和树枝节点是有顺序的,你不能乱排,怎么办?比如我们上面的例子,研发一组下边有3个成员,这3个成员要进行排序(在机关里这叫做排位,同样是同事也有个先后升迁顺序),你怎么处理?问我呀,问你呢,好好想想,以后用得着的!