28.4 享元模式的扩展 28.4.1 线程安全的问题 线程安全是一个老生常谈的话题,只要使用Java开发都会遇到这个问题,我们之所以要在今天的享元模式中提到该问题,是因为该模式有太大的几率发生线程不安全,为什么呢?
我们还以报考系统为例来说明这个问题。大家有没有想过,为什么要以考试科目+考试地点作为外部状态呢?为什么不能以考试科目或者考试地点作为外部状态呢?这样池中的对象会更少!可以!完全可以!我们把程序以考试科目为外部状态,把享元工厂稍作修改,如代码清单28-10所示。
代码清单28-10 报考信息工厂
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class SignInfoFactory { private static HashMap<String,SignInfo> pool = new HashMap <String,SignInfo>(); public static SignInfo getSignInfo (String key) { SignInfo result = null ; if (!pool.containsKey(key)){ result = new SignInfo (); pool.put(key, result); } else { result = pool.get(key); } return result; } }
下面做很小的改动,只修改了黑色字体部分。为了展示多线程的情况,我们写一个多线程的类,如代码清单28-11所示。
代码清单28-11 多线程场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class MultiThread extends Thread { private SignInfo signInfo; public MultiThread (SignInfo _signInfo) { this .signInfo = _signInfo; } public void run () { if (!signInfo.getId().equals(signInfo.getLocation())){ System.out.println("编号:" +signInfo.getId()); System.out.println("考试地址:" +signInfo.getLocation()); System.out.println("线程不安全了!" ); } } }
在run方法中判断特殊值,检查是否是线程安全,我们来看看场景类,如代码清单28-12 所示。
代码清单28-12 场景类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Client { public static void main (String[] args) { SignInfoFactory.getSignInfo("科目1" ); SignInfoFactory.getSignInfo("科目2" ); SignInfoFactory.getSignInfo("科目3" ); SignInfoFactory.getSignInfo("科目4" ); SignInfo signInfo = SignInfoFactory.getSignInfo("科目2" ); while (true ){ signInfo.setId("ZhangSan" ); signInfo.setLocation("ZhangSan" ); (new MultiThread (signInfo)).start(); signInfo.setId("LiSi" ); signInfo.setLocation("LiSi" ); (new MultiThread (signInfo)).start(); } } }
模拟实际的多线程情况,在对象池中我们保留4个对象,然后启动N多个线程来模拟, 我们马上就看到如下的提示:
1 2 3 编号:LiSi 考试地址:ZhangSan 线程不安全了!
看看,线程不安全了吧,这是正常的,设置的享元对象数量太少,导致每个线程都到对象池中获得对象,然后都去修改其属性,于是就出现一些不和谐数据。只要使用Java开发,线程问题是不可避免的,那我们怎么去避免这个问题呢?享元模式是让我们使用共享技术, 而Java的多线程又有如此问题,该如何设计呢?没什么可以参考的标准,只有依靠经验,在需要的地方考虑一下线程安全,在大部分的场景下都不用考虑。我们在使用享元模式时,对象池中的享元对象尽量多,多到足够满足业务为止。
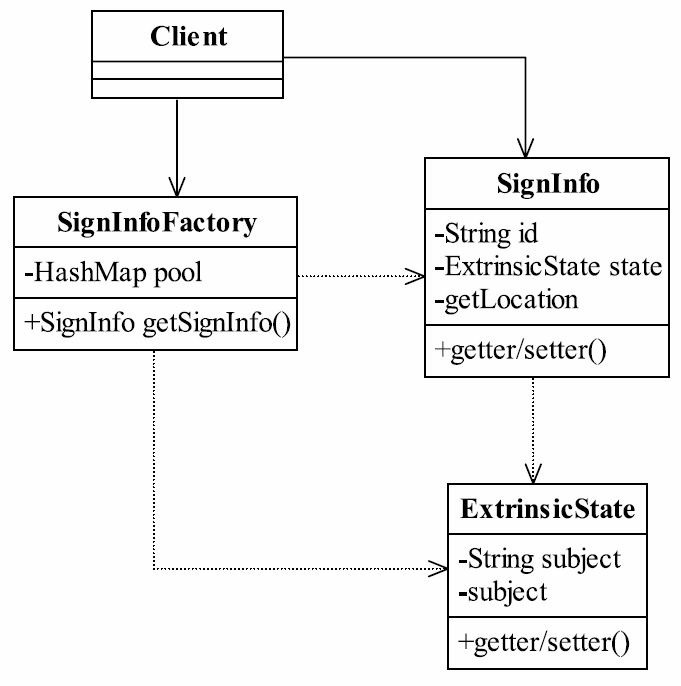
28.4.2 性能平衡 尽量使用Java基本类型作为外部状态。在报考系统中,我们不考虑系统的修改风险,完全可以重新建立一个类作为外部状态,因为这才完全符合面向对象编程的理念。好,我们实现处理,先看类图,如图28-4所示。
图28-4 类作为外部状态
我们首先来看ExtrinsicState外部状态类,如代码清单28-13所示。
代码清单28-13 外部状态类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class ExtrinsicState { private String subject; private String location; public String getSubject () { return subject; } public void setSubject (String subject) { this .subject = subject; } public String getLocation () { return location; } public void setLocation (String location) { this .location = location; } @Override public boolean equals (Object obj) { if (obj instanceof ExtrinsicState){ ExtrinsicState state = (ExtrinsicState)obj; return state.getLocation().equals(location) && state.getSubject().equals(subject); } return false ; } @Override public int hashCode () { return subject.hashCode() + location.hashCode(); } }
注意,一定要覆写equals和hashCode方法,否则它作为HashMap中的key值是根本没有意义的,只有hashCode值相等,并且equals返回结果为true,两个对象才相等,也只有在这种情况下才有可能从对象池中查找获得对象。
1 注意 如果把一个对象作为Map类的键值,一定要确保重写了equals和hashCode方法, 否则会出现通过键值搜索失败的情况,例如map.get(object)、map.contains(object)等会返回失败的结果。
SignInfo的修改较小,仅在SignInfo中引入该ExtrinsicState外部状态对象,在此不再赘述。 我们再来看享元工厂,它是以ExtrinsicState类作为外部状态,如代码清单28-14所示。
代码清单28-14 享元工厂
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class SignInfoFactory { private static HashMap<ExtrinsicState,SignInfo> pool = new HashMap <ExtrinsicState,SignInfo>(); public static SignInfo getSignInfo (ExtrinsicState key) { SignInfo result = null ; if (!pool.containsKey(key)){ result = new SignInfo (); pool.put(key, result); } else { result = pool.get(key); } return result; } }
重点是看看我们的场景类,我们来测试一下性能差异,如代码清单28-15所示。
代码清单28-15 场景类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Client { public static void main (String[] args) { ExtrinsicState state1 = new ExtrinsicState (); state1.setSubject("科目1" ); state1.setLocation("上海" ); SignInfoFactory.getSignInfo(state1); ExtrinsicState state2 = new ExtrinsicState (); state2.setSubject("科目1" ); state2.setLocation("上海" ); long currentTime = System.currentTimeMillis(); for (int i=0 ;i<1000000 ;i++){ SignInfoFactory.getSignInfo(state2); } long tailTime = System.currentTimeMillis(); System.out.println("执行时间:" +(tailTime - currentTime) + " ms" ); } }
运行结果如下所示:
同样,我们看看以String类型作为外部状态的运行情况,如代码清单28-16所示。
代码清单28-16 场景类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Client { public static void main (String[] args) { String key1 = "科目1上海" ; String key2 = "科目1上海" ; SignInfoFactory.getSignInfo(key1); long currentTime = System.currentTimeMillis(); for (int i=0 ;i<10000000 ;i++){ SignInfoFactory.getSignInfo(key2); } long tailTime = System.currentTimeMillis(); System.out.println("执行时间:" +(tailTime - currentTime) + " ms" ); } }
运行结果如下所示:
看到没?一半的效率,这还是非常简单的享元对象,看看我们重写的equals方法和hashCode方法,这段代码是必须实现的,如果比较复杂,这个时间差异会更大。
各位,想想看,使用自己编写的类作为外部状态,必须覆写equals方法和hashCode方法,而且执行效率还比较低,这种吃力不讨好的事情最好别做,外部状态最好以Java的基本类型作为标志,如String、int等,可以大幅地提升效率。