7.2 使用Traverson导航REST API
7.2 使用Traverson导航REST API
Traverson来源于Spring Data HATEOAS项目,是Spring应用中开箱即用的消费超媒体API的解决方案。这个基于Java的库灵感来源于同名的JavaScript库。
你可能已经发现Traverson的名字有点类似于“traverse on”,这种叫法其实可以很好地描述它的用法。在本节中,我们将会以遍历API关系名的方式来消费API。
要使用Traverson,首先我们要用API的基础URI来实例化一个Traverson对象:
1 | Traverson traverson = new Traverson( |
在这里,我将Traverson指向了Taco Cloud的基础URL(本地运行)。这是需要给Traverson指定的唯一URL。从这里开始,我们就可以根据链接的关系名来遍历API。我们同时还指定了API将会生成JSON格式的响应,并且具有HAL风格的超链接,这样Traverson就能知道怎样解析传入的资源数据了。与RestTemplate类似,你可以选择在使用Traverson对象之前实例化它,也可以将其声明为一个bean并在需要的地方注入进来。
有了Traverson对象之后,我们就可以通过以下链接使用API。例如,假设我们想检索所有配料的列表。从6.3.1小节可以知道,配料链接有一个href属性,它会链接到配料资源。我们需要跟踪这个链接:
1 | ParameterizedTypeReference<Resources<Ingredient>> ingredientType = |
通过调用Traverson对象的follow()方法,我们就可以导航至链接关系名为ingredients的资源。现在,客户端已经导航至ingredients,我们需要通过调用toObject()来提取资源的内容。
我们需要告诉toObject()方法要将数据读入到哪种对象之中。考虑到我们需要以Resources<Ingredient>对象的形式来读入,而且Java类型擦除使得为泛型提供类型信息变得非常困难,所以这可能会有些棘手。但是,创建ParameterizedTypeReference能够帮助我们解决这个问题。
打个比方,假设这不是REST API,而是Web站点上的主页;这也不是REST客户端代码,而是我们正在浏览器中查看主页。在页面中,我们看到了一个关于Ingredients的链接,点击进入该链接。在进入下一个页面的时候,我们需要读取该页面,类似于Traverson将内容提取为Resources<Ingredient>对象。
现在,我们考虑一个更有趣的场景——假设我们想要获取最新创建的taco。从主资源开始,我们可以按照如下方式导航至最近的taco资源:
1 | ParameterizedTypeReference<Resources<Taco>> tacoType = |
在这里,我们跟踪tacos链接,然后从这里开始,跟踪recents链接。通过这种方式,我们得到了感兴趣的资源,所以基于对应的ParameterizedTypeReference调用toObject()方法,我们就得到了想要的内容。我们可以通过列出关系名称列表的形式来简化“.follow()”方法:
1 | Resources<Taco> tacoRes = |
正如我们所看到的,Traverson能够很容易地导航HATEOAS的API并消费其资源。但是,它并没有提供通过这些API写入或删除资源的方法。相反,RestTemplate能够写入和删除资源,但是在导航API方面支持得并不太好。
当你既要导航API又要更新或删除资源时,你需要组合使用RestTemplate和Traverson。Traverson仍然可以导航至创建新资源的链接。然后,可以将这个链接传递给RestTemplate来执行POST、PUT、DELETE或任何其他需要的HTTP请求。
例如,我们想要为Taco Cloud菜单添加一个新的Ingredient,如下的addIngredient ()方法将Traverson和RestTemplate组合起来,向API提交了一个新的Ingredient:
1 | private Ingredient addIngredient(Ingredient ingredient) { |
在跟踪完Ingredients之后,我们通过调用asLink()方法得到链接本身。基于该链接,我们调用getHref()得到链接的URL。有了URL之后,我们就具备了使用RestTemplate调用postForObject()并创建新配料所需的一切。
7.1 使用RestTemplate消费REST端点
7.1 使用RestTemplate消费REST端点
从客户端的角度来看,与REST资源进行交互涉及很多工作,而且大多数都是很单调乏味的样板式代码。如果使用较低层级HTTP库,客户端就需要创建一个客户端实例和请求对象、执行请求、解析响应、将响应映射为领域对象,并且还要处理这个过程中可能会抛出的所有异常。不管发送什么样的HTTP请求,这种样板代码都要不断重复。
为了避免这种样板代码,Spring提供了RestTemplate。就像JDBCTemplate能够处理JDBC中丑陋的那部分代码一样,RestTemplate也能够将你从消费REST资源所面临的单调工作中解放出来。
RestTemplat提供了41个与REST资源交互的方法。我们不会详细介绍它所提供的所有方法,而是只考虑12个独立的操作(见表7.1),每种方法都有重载形式,它们组成了完整的41个方法。
表7.1 RestTemplate中12个独立的操作
- 使用String作为URL格式,并使用可变参数列表指明URL参数。
- 使用String作为URL格式,并使用
Map<String,String>指明URL参数。 - 使用java.net.URI作为URL格式,不支持参数化URL。
明确了RestTemplate所提供的12个操作以及各个变种如何工作之后,你就能以自己的方式编写消费REST资源的客户端了。
要使用RestTemplate,你可以在需要的地方创建一个实例:
1 | RestTemplate rest = new RestTemplate(); |
也可以将其声明为一个bean并注入到需要的地方:
1 |
|
我们通过对4个主要HTTP方法(GET、PUT、DELETE和POST)的支持来研究RestTemplate的操作。下面我们从GET方法的getForObject()和getForEntity()开始。
7.1.1 GET资源
假设我们现在想要通过Taco Cloud API获取某个配料,并且API没有实现HATEOAS,那么我们可以使用getForObject()获取配料。例如,如下的代码将使用RestTemplate根据ID来获取Ingredient对象:
1 | public Ingredient getIngredientById(String ingredientId) { |
在这里,我们使用了getForObject()的变种形式,接收一个String类型的URL并使用可变列表来指定URL变量。传递给getForObject()的ingredientId参数会用来填充给定URL的{id}占位符。尽管在本例中只有一个URL变量,但是很重要的一点需要我们注意,变量参数会按照它们出现的顺序设置到占位符中。getForObject()方法的第二个参数是响应应该绑定的类型。在本例中,响应数据(很可能是JSON格式)应该被反序列化为要返回的Ingredient对象。
另外一种替代方案是使用Map来指定URL变量:
1 | public Ingredient getIngredientById(String ingredientId) { |
在本例中,ingredientId的值会被映射到名为id的key上。当发起请求的时候,{id}占位符将会被替换为key为id的Map条目上。
使用URL参数要稍微复杂一些,这种方式需要我们在调用getForObject()之前构建一个URI对象。在其他方面,它与另外两个变种非常类似:
1 | public Ingredient getIngredientById(String ingredientId) { |
在这里,URI对象是通过String规范定义的,它的占位符会被Map中的条目所替换,与之前看到的getForObject()变种非常相似。getForObject()是获取资源的有效方式,但是如果客户端需要的不仅仅是载荷体,那么可以考虑使用getForEntity()。
getForEntity()的工作方式和getForObject()类似,但是它所返回的并不是代表响应载荷的领域对象,而是一个包裹领域对象的ResponseEntity对象。借助ResponseEntity对象能够访问很多的响应细节,比如响应头信息。
例如,我们除了想要获取配料数据之外,还想要从响应中探查Date头信息。借助getForEntity(),这个需求很容易实现:
1 | public Ingredient getIngredientById(String ingredientId) { |
getForEntity()有与getForObject()方法相同参数的重载形式,所以我们既可以以可变列表参数的形式提供URL变量,也可以以URI对象的形式调用getForEntity()。
7.1.2 PUT资源
为了发送HTTP PUT请求,RestTemplate提供了put()方法。put()方法的3个变种形式都会接收一个Object,它会被序列化并发送至给定的URL。就URL本身来讲,它可以以URI对象或String的形式来指定。与getForObject()和getForEntity()类似,URL变量能够以可变参数列表或Map的形式来提供。
假设我们想要使用一个新Ingredient对象的数据来替换某个配料资源,那么如下的代码片段就能做到这一点:
1 | public void updateIngredient(Ingredient ingredient) { |
在这里,URL是以String的形式指定的。该URL包含一个占位符,它会被给定Ingredient的id属性所替换。要发送的数据是Ingredient对象本身。put()方法返回的是void,所以没有必要处理返回值。
7.1.3 DELETE资源
1 | public void deleteIngredient(Ingredient ingredient) { |
在本例中,我们只为delete()提供了URL(以String的形式指定)和URL变量值。但是,和其他的RestTemplate方法类似,URL能够以URI对象的方式来指定,并且URL参数也能够以Map的方式来声明。
7.1.4 POST资源
现在,假设要添加新的配料到Taco Cloud菜单中,我们可以向“…/ingredients”端点发送HTTP POST请求并将配料数据放到请求体中。RestTemplate有3种发送POST请求的方法,每种方法都有相同的重载变种来指定URL。如果你希望在POST请求之后得到新创建的Ingredient资源,那么可以按照如下方式使用postForObject():
1 | public Ingredient createIngredient(Ingredient ingredient) { |
postForObject()方法的这个变种形式接收一个String类型的URL规范、要提交给服务器端的对象以及响应体应该绑定的领域类型。尽管我们在这里没有用到,但是第4个参数可以是URL变量值的Map或者是可变参数的列表,它们能够替换到URL之中。
如果客户端还想要知道新创建资源的地址,那么我们可以调用postForLocation()方法:
1 | public URI createIngredient(Ingredient ingredient) { |
注意,postForLocation()的工作方式与postForObject()类似,只不过它所返回的是新创建资源的URI,而不是资源对象本身。这里所返回的URI是从响应的Location头信息中派生出来的。如果你同时需要地址和响应载荷,那么可以使用postForEntity()方法:
1 | public Ingredient createIngredient(Ingredient ingredient) { |
尽管RestTemplate的方法在目的上有所不同,但是它们的用法非常相似。因此,我们很容易就可以精通RestTemplate并将其用到客户端代码中。
另一方面,如果你所消费的API在响应中包含了超链接,那么RestTemplate就力所不及了。当然,我们可以使用RestTemplate获取更详细的资源数据,然后处理里面所包含的内容和链接,但是这个任务并不简单。与其使用RestTemplate来处理超媒体API,还不如选择一个专门关注该领域的库,那就是Traverson。
第2部分 Spring集成
第2部分 Spring集成
第2部分的章节将会涵盖Spring应用与其他应用集成的话题。
第6章将扩展第2章对Spring MVC的讨论,介绍如何在Spring中编写REST API。我们将会看到如何使用Spring MVC定义REST端点、启用超媒体REST资源以及使用Spring Data REST自动生成基于repository的REST端点。第7章转换视角,关注Spring应用如何消费REST API的话题。在第8章中,我们将会学习如何借助异步通信技术让Spring发送和接收Java Message Service (JMS)、RabbitMQ与Kafka的消息。在最后的第9章中,我们将探讨使用Spring Integration项目实现声明式应用集成的话题。我们会涵盖实时处理数据、定义集成流以及与外部系统(如Email和文件系统)集成的功能。
7.0 第7章 消费REST服务
第7章 消费REST服务
本章内容:
- 使用RestTemplate消费REST API
- 使用Traverson导航超媒体API
你有没有过这样的经历——跑去看电影,却发现自己是影院中唯一的一个人。这当然是一种很奇妙的经历,从本质上来讲,这变成了一个私人电影。你可以选择任意想要的座位、和屏幕上的角色交谈,甚至可以打开手机发推特,完全不用担心因为破坏了别人的观影体验而惹人生气。最棒的是,没有人会毁了你观看这部电影的心情。
对我来说,这样的事情并不常见。但是,遇到这种情况的时候,我会想,如果我也不出现的话会发生什么呢?工作人员还会播放这部影片吗?电影中的英雄还会拯救世界吗?电影播放结束后,工作人员还会打扫影院吗?
没有观众的电影就像没有客户端的API。这些API已经准备好接收和提供数据了,但是如果它们从来没有被调用过,它们还是API吗?就像薛定谔的猫一样,在发起请求之前,我们并不知道这个API是否活跃,也不知道它是否返回HTTP 404响应。
在前面的章节中,我们主要关注如何定义REST端点,它们可以被应用外部的客户端所消费。尽管开发这种API的主要驱动力是单页Angular应用,以便于实现TacoCloud Web站点,但实际上客户端可以是任意应用,可以是任何语言,甚至可以是另外一个Java应用。
Spring应用除了提供对外API之外,同时要对另外一个应用的API发起请求的场景并不罕见。实际上,在微服务领域,这正变得越来越普遍。因此,花点时间研究一下如何使用Spring与REST API交互是非常值得的。
Spring应用可以采用多种方式来消费REST API,包括以下几种方式:
- RestTemplate:Spring核心框架提供的简单、同步REST客户端。
- Traverson:Spring HATEOAS提供的支持超链接、同步的REST客户端,其灵感来源于同名的JavaScript库。
- WebClient:Spring 5所引入的反应式、异步REST客户端。
我将WebClient推迟到第11章讨论Spring的反应式Web框架时再进行介绍,现在我们主要关注其他的两个REST客户端。下面先从RestTemplate开始。
6.3 启用数据后端服务
6.3 启用数据后端服务
正如我们在第3章中所看到的,Spring Data有一种特殊的魔法,它能够基于我们定义的接口自动创建repository实现。但是Spring Data还有另外一项技巧,它能帮助我们定义应用的API。
Spring Data REST是Spring Data家族中的另外一个成员,它会为Spring Data创建的repository自动生成REST API。我们只需要将Spring Data REST添加到构建文件中,就能得到一套API,它的操作与我们定义repository接口是一致的。
为了使用Spring Data REST,我们需要将如下的依赖添加到构建文件中:
1 | <dependency> |
不管你是否相信,对于已经使用Spring Data自动生成repository的项目来说,我们只需要完成这一步就能对外暴露REST API了。将Spring Data REST starter添加到构建文件中之后,应用的自动配置功能会为Spring Data(包括Spring DataJPA、Spring Data Mongo等)创建的所有repository自动创建REST API。
Spring Data REST所创建的端点和我们自己创建的端点一样好(甚至能够更好一些)。所以,我们可以做一些移除操作,在进行下一步之前将我们已经创建的带有@RestController注解的类移除。
为了尝试Spring Data REST提供的端点,我们可以启动应用并测试一些URL。基于为Taco Cloud定义的repository,我们可以对taco、配料、订单和用户执行一些GET请求。
举例来说,我们可以向“/ingredients”发送GET请求以获取所有配料。借助curl,我们得到的响应大致如下所示(进行了删减,只显示第一种配料):
1 | $ curl localhost:8080/ingredients |
太棒了!我们只不过将一项依赖添加到了构建文件中,这样不但得到了针对配料的端点,而且返回的资源中还包含超链接。我们可以假装成这个API的客户端,使用curl继续访问self链接以获取玉米面薄饼的详情:
1 | $ curl http://localhost:8080/ingredients/FLTO |
为了避免分散注意力,在本书中,我们不再浪费时间深入探究Spring Data REST所创建的每个端点和可选项。但是,我们需要知道,它还支持端点的POST、PUT和DELETE方法。也就是说,你可以发送POST请求至“/ingredients”来创建新的配料,也可以发送DELETE请求到“/ingredients/FLTO”,以便于从菜单中删除玉米面薄饼。
我们想做的另外一件事可能就是为API设置一个基础路径,这样它们会有不同的端点,避免与我们所编写的控制器产生冲突(实际上,如果我们不删除前面自己创建的IngredientsController,就将会干扰Spring Data REST提供的“/ingredients”端点)。为了调整API的基础路径,我们可以设置spring.data.rest.base-path属性:
1 | spring: |
这项配置会将Spring Data REST端点的基础路径设置为“/api”。现在,配料端点将会变成“/api/ingredients”。我们通过请求taco列表来验证一下这个新的基础路径:
1 | $ curl http://localhost:8080/api/tacos |
哦,天啊!它并没有按照预期那样运行。我们有了Ingredient实体和IngredientRepository接口之后,Spring Data REST就会暴露“/api/ingredients”。我们也有Taco实体和TacoRepository接口,为什么SpringData REST没有为我们生成“/api/tacos”端点呢?
6.3.1 调整资源路径和关系名称
实际上,Spring Data确实为我们提供了处理taco的端点。虽然Spring Data REST非常聪明,但是在暴露taco端点的时候出现了一点问题。
当为Spring Data repository创建端点的时候,Spring Data REST会尝试使用相关实体类的复数形式。对于Ingredient实体来说,端点将会是“/ingredients”,对于Order和User实体,端点将会是“/orders”和“/users”。到目前为止,一切运行良好。但有些场景下,比如遇到“taco”的时候,它获取到这个单词,为其生成的复数形式就不太正确了。实际上,Spring Data REST将“taco”的复数形式计算成了“tacoes”,所以,为了向taco发送请求,我们必须将错就错,请求“/api/tacoes”地址:
1 | % curl localhost:8080/api/tacoes |
你肯定会想,我是怎么知道“taco”的复数形式被错误计算成了“tacoes”。实际上,Spring Data REST还暴露了一个主资源(home resource),这个资源包含了所有端点的链接。我们只需要向API的基础路径发送GET请求就能得到它的结果:
1 | $ curl localhost:8080/api |
可以看到,这个主资源显示了所有实体的链接。除了tacoes链接之外,其他都很好,在这里关系名和URL地址上都是“taco”错误的复数形式。
好消息是,我们并非必须接受Spring Data REST的这个小错误。通过为Taco添加一个简单的注解,我们就能调整关系名和路径:
1 | @Data |
@RestResource注解能够为实体提供任何我们想要的关系名和路径。在本例中,我们将它们都设置成了“tacos”。现在,我们请求主资源的时候,会看到tacos有了正确的复数形式:
1 | "tacos" : { |
这样就将我们的端点路径整理好了,现在可以向“/api/tacos”发送请求来操作taco资源了。
接下来我们看一下使用Spring Data REST端点如何进行排序。
6.3.2 分页和排序
你可能已经发现,主资源上的所有链接都提供了可选的page、size和sort参数。默认情况下,请求集合资源(比如“/api/tacos”)都会返回第一页的20个条目。但是,我们可以通过在请求中指定page和size参数调整具体的页数和每页的数量。
例如,我们想要请求第一页的taco,但是希望包含5个条目,就可以发送如下的GET请求(使用curl):
1 | $ curl "localhost:8080/api/tacos?size=5" |
如果taco的数量超过了5个,我们可以通过使用page参数获取第二页的taco:
1 | $ curl "localhost:8080/api/tacos?size=5&page=1" |
注意,page参数是从0开始计算的,也就是说page值为1的时候会请求第二页的数据(你可能会发现,很多命令行shell遇到请求中的&符号会出错,所以我们在前面的curl命令中为整个URL使用了引号)。
我们可以使用字符串操作来将这些参数拼接到URL上,但是HATEOAS为我们提供了第一页、下一页、上一页和最后一页等链接:
1 | "_links" : { |
有了这些链接,API的客户端就不需要跟踪当前正处于哪一页,也不用将参数自己拼接到URL上了,只需根据名字查找这些页面导航并进行访问就可以了。
sort参数允许我们根据实体的某个属性对结果进行排序。例如,我们想要获取最近创建的12条taco进行UI展示,就可以混合使用分页和排序参数实现:
1 | $ curl "localhost:8080/api/tacos?sort=createdAt,desc&page=0&size=12" |
在这里,sort参数指定我们要按照createdAt属性进行排序,并且要按照降序进行排列(所以最新的taco会放在最前面)。page和size参数指定我们想要获取第一页的12个taco。
这恰好是UI展现最近创建的taco所需要的数据。它与我们在本章前文DesignTacoController定义的“/design/recent”端点大致相同。
这里还有一个小问题。UI代码需要硬编码才能请求带有指定参数的taco列表。当然,这可以正常运行。但是,如果让客户端太多地了解如何构建API请求,就会在一定程度上增加脆弱性。如果客户端能够从链接列表中查找URL就太好了。如果URL能够更简洁,就像前面看到“/design/recent”一样,那就更棒了。
6.3.3 添加自定义的端点
Spring Data REST能够很好地为执行CRUD操作的Spring Data repository创建端点。但有时候,我们需要脱离默认的CRUD API,创建处理核心问题的端点。
我们当然可以在带有@RestController注解的bean中实现任意的端点,以此来补充Spring Data REST端点的不足。实际上,我们可以重新启用本章前面提到的DesignTacoController,它依然可以与Spring Data REST提供的端点一起运行。
但是在编写自己的API控制器时,它们的端点在有些方面会与Spring Data REST的端点脱节:
- 我们自己的控制器端点没有映射到Spring Data REST的基础路径下。虽然我们可以强制要求它们映射到任意前缀作为基础路径,包括使用Spring DataREST的基础路径,但是如果基础路径发生变化的话,我们还需要修改控制器的映射,以便于与其匹配。
- 在自己控制器所定义的端点中,返回资源时并不会自动包含超链接,与Spring Data REST所返回的资源是不同的。这意味着,客户端无法通过关系名发现自定义的端点。
我们首先来解决基础路径的问题。Spring Data REST提供了一个新的注解@RepositoryRestController,这个注解可以用到控制器类上,这样控制器类所有映射的基础路径就会与Spring Data REST端点配置的基础路径相同。简而言之,在使用@RepositoryRestController注解的控制器中,所有映射将会具有和spring.data.rest.base-path属性值一样的前缀(我们之前将这个属性的值配置成了“/api”)。
在这里我们会创建一个只包含recentTacos()方法的新控制器,而不是修改已有的DesignTacoController,因为这个旧的控制器包含了多个我们不再需要的方法。程序清单6.7中的RecentTacosController带有@RepositoryRestController注解,表明它会将Spring Data REST的基础路径用到自己的请求映射上。
程序清单6.7 将Spring Data REST的基础路径用到控制器上
1 | package tacos.web.api; |
虽然@GetMapping映射到了“/tacos/recent”路径,但是类级别的@Repository RestController注解会确保这个路径添加Spring Data REST的基础路径作为前缀。按照我们的配置,recentTacos()方法将会处理针对“/api/tacos/recent”的GET请求。
需要注意的是,尽管@RepositoryRestController的名称和@RestController非常相似,但是它并没有和@RestController相同的语义。具体来讲,它并不能保证处理器方法返回的值会自动写入响应体中。所以,我们要么为方法添加@ResponseBody注解,要么返回包装响应数据的ResponseEntity。这里我们选择的方案是返回ResponseEntity。
RecentTacosController准备就绪之后,对“/api/tacos/recent”发送请求最多会返回15条最近创建的taco,此时就不需要在URL中添加分页和排序参数了。但是在请求“/api/tacos”的时候,这个地址依然没有出现在结果的超链接列表中。
6.3.4 为Spring Data端点添加自定义的超链接
如果最近taco端点没有出现在“/api/tacos”所返回的超链接中,那么客户端如何知道该怎样获取最近的taco呢?它要么猜测,要么使用分页和排序参数。无论采用哪种方式,都需要在客户端代码中硬编码,这都不是理想的做法。
通过声明资源处理器(resource processor)bean,我们可以为Spring DataREST自动包含的链接列表继续添加链接。Spring Data HATEOAS提供了一个ResourceProcessor接口,能够在资源通过API返回之前对其进行操作。对于我们的场景来说,需要一个ResourceProcessor实现,为PagedResources<Resource<Taco>>类型的资源(也就是“/api/tacos”端点所返回的类型)添加recents链接。程序清单6.8展现了定义这种ResourceProcessor的bean声明方法。
程序清单6.8 为Spring Data REST端点添加自定义的链接
1 |
|
程序清单6.8中的ResourceProcessor定义了一个匿名内部类,并将其声明为Spring应用上下文中所创建的bean。Spring HATEOAS会自动发现这个bean(以及其他ResourceProcessor类型的bean)并将其应用到对应的资源上。在本例中,如果控制器返回PagedResources<Resource<Taco>>,就会包含一个最近创建的taco链接。这就包括了对“/api/tacos”请求的响应。
6.2 启用超媒体
6.2 启用超媒体
到目前为止,我们所创建的API非常简单,但是只要消费它的客户端知道API的URL模式,它们就可以正常运行。例如,客户端可能会以硬编码的形式对“/design/recent”发送GET请求,以便于获取最近创建的taco。类似的,客户端会以硬编码的形式将taco列表中的ID拼接到“/design”上形成获取特定taco资源的URL。
在API客户端编码中,使用硬编码模式和字符串操作是很常见的。但是,我们设想一下,如果API的URL模式发生了变化又会怎么样呢?硬编码的客户端代码掌握的依然是旧的API信息,因此客户端代码将无法正常运行。对API URL进行硬编码和字符串操作会让客户端代码变得很脆弱。
超媒体作为应用状态引擎(Hypermedia as the Engine of Application State,HATEOAS)是一种创建自描述API的方式。API所返回的资源中会包含相关资源的链接,客户端只需要了解最少的API URL信息就能导航整个API。这种方式能够掌握API所提供的资源之间的关系,客户端能够基于API的URL中所发现的关系对它们进行遍历。
举例来说,假设某个客户端想要请求最近设计的taco的列表,按照原始的形式,在没有超链接的情况下,客户端以JSON格式接收到的taco列表会如下所示(为了简洁,这里只保留了第一个taco,剩余的省略了):
1 | [ |
如果客户端想要获取某个taco或者对其进行其他HTTP操作,就需要将它的id属性以硬编码的方式拼接到一个路径为“/design”的URL上。与之类似,如果客户端想要对某个配料执行HTTP请求,就需要将该配料id属性的值拼接到路径为“/ingredients”的URL上。在这两种情况下,都需要在路径上添加“http://”或“https://”前缀以及API的主机名。
如果API启用了超媒体功能,那么API将会描述自己的URL,从而减轻客户端对其进行硬编码的痛苦。如果嵌入超链接,那么最近创建的taco列表将会如程序清单6.3所示。
程序清单6.3 包含超链接的taco资源列表
1 | { |
这种特殊风格的HATEOAS被称为HAL(超文本应用语言,Hypertext ApplicationLanguage)。这是一种在JSON响应中嵌入超链接的简单通用格式。
虽然这个列表看上去不像前面那样简洁,但是它确实提供了一些有用的信息。这个新taco列表中的每个元素都包含了一个名为“_links”的属性,为客户端提供导航API的超链接。在本例中,taco和配料都有一个“self”链接,用来引用该资源;整个列表有一个“recents”链接,用来引用该API自身。
如果客户端应用需要对列表中的taco执行HTTP请求,那么在开发的时候不需要关心taco资源的URL是什么样子。相反,它只需要请求“self”链接就可以了,该属性将会映射至http://localhost:8080/design/4。如果客户端想要处理特定的配料,只需要查找该配料的“self”链接即可。
Spring HATEOAS项目为Spring提供了超链接的支持。它提供了一些类和资源装配器(assembler),在Spring MVC控制器返回资源之前能够为其添加链接。
为了在Taco Cloud API中启用超媒体功能,我们需要在构建文件中添加如下的Spring HATEOAS starter依赖:
1 | <dependency> |
这个starter不仅会将Spring HATEOAS添加到项目的类路径中,还会提供自动配置功能以启用Spring HATEOAS。我们所需要做的就是重新实现控制器,让它们返回资源类型,而不是领域类型。
我们首先为最近taco列表添加超链接,也就是针对“/design/recent”的GET请求。
6.2.1 添加超链接
Spring HATEOAS提供了两个主要的类型来表示超链接资源:Resource和Resources。Resource代表一个资源,而Resources代表资源的集合。这两种类型都能携带到其他资源的链接。当从Spring MVC REST控制器返回时,它们所携带的链接将会包含到客户端所接收到的JSON(或XML)中。
为了给最近创建的taco添加超链接,我们需要重新实现程序清单6.2中的recentTacos()方法。原始的实现返回的是List
程序清单6.4 为资源添加超链接
1 |
|
在这个新版本的recentTacos()中,我们不再直接返回taco的列表,而是使用Resources.wrap()将taco列表包装为Resources<Resource
1 | "_links": { |
这是一个很好的起点,但是我们还有一些事情需要完成。现在,我们只是为整体的列表添加了链接,还没有为taco资源本身以及每个taco中的配料添加链接。我们很快就会实现该功能,但是在此之前,我们要先解决recents链接中的硬编码问题。
像这样对URL进行硬编码是一种很糟糕的办法。除非Taco Cloud的目标仅限于在本地开发机器上运行应用,否则,我们需要找一种方式避免在URL中使用硬编码的localhost:8080。幸运的是,Spring HATEOAS以链接构建者(link builder)的方式为我们提供了帮助。
在Spring HATEOAS中,最有用的链接构建者是ControllerLinkBuilder。这个链接构建者非常智能,它能自动探知主机名是什么,这样就能避免对其进行硬编码。同时,它还提供了流畅的API,允许我们相对于控制器的基础URL构建链接。
借助ControllerLinkBuilder,我们可以将recentTacos()中硬编码的Link创建改造成如下的形式:
1 | Resources<Resource<Taco>> recentResources = Resources.wrap(tacos); |
我们不仅不需要硬编码主机名,而且不再需要指定“/design”。在这里,我们向DesignTacoController请求获取一个链接,它的基础路径为“/design”。ControllerLinkBuilder使用控制器的基础路径作为我们创建的Link对象的基础。
接下来,调用了在Spring项目中我最喜欢的一个方法:slash()。我喜欢这个方法的原因是这个方法非常简洁地描述了它要做的事情。这个方法会为URL添加斜线(/)和给定的值,所形成的URL路径是“/design/recent”。
最后,我们为Link指定了一个关系名。在本例中,关系名为recents。
尽管我是slash()的忠实粉丝,但是ControllerLinkBuilder还有另外一个方法,能够消除链接URL上的所有硬编码。此时,我们不再需要调用slash(),而是调用linkTo(),并将控制器中的一个方法传递给它,这样ControllerLinkBuilder就能推断出控制器的基础路径和该方法的映射路径。如下的代码就以这种方式使用了linkTo()方法:
1 | Resources<Resource<Taco>> recentResources = Resources.wrap(tacos); |
在这里,我静态导入了linkTo()和methodOn()方法(它们都来自ControllerLinkBuilder),从而让代码更易于阅读。methodOn()方法传入控制器类,从而允许我们调用recentTacos()方法,这个调用会被ControllerLinkBuilder拦截,用来确定控制器的基础路径和recentTacos()的映射路径。现在,整个URL都从控制器的映射中判断出来了,而且完全没有硬编码。非常棒!
6.2.2 创建资源装配器
现在,我们需要为列表中的taco资源添加链接。有种方案就是遍历Resources对象中所携带的每个Resource<Taco>元素,为它们依次添加Link。但是,这种方式有点过于枯燥,在需要返回taco列表的所有地方都需要在API中重复循环相关的代码。
我们需要有一种不同的策略。
对于列表中的每个taco,我们不再使用Resources.wrap()来创建Resource,而是定义一个将Taco对象转换为TacoResource对象的工具类。TacoResource对象与Taco类似,但是它本身能携带链接。程序清单6.5展示了TacoResource。
程序清单6.5 能够携带领域数据和超链接列表taco资源
1 | package tacos.web.api; |
从很多方面来看,TacoResource都与Taco领域类型没有区别。它们都有name、createdAt和ingredients属性。但是,TacoResource扩展了ResourceSupport,从而继承了一个Link对象的列表和管理链接列表的方法。
除此之外,TacoResource并没有包含Taco的id属性。这是因为没有必要在API中暴露数据库相关的ID。从API客户端的角度来看,资源的self链接将会作为该资源的标识符。
注意:“领域”和“资源”应该各自独立还是应该是同一个类呢?有些Spring开发人员可能会让领域类型扩展ResourceSupport,从而将领域和资源对象合二为一。至于哪种方式才是正确的,这里并没有确切答案。我选择的做法是创建一个单独的资源类型,这样Taco就没有必要添加资源链接了,因为在有些场景下,这些链接是根本用不到的。另外,通过创建一个单独的资源类型,能够很容易地将id属性排除出去,这样它就不会暴露在API中了。
TacoResource有一个很简单的构造器,会接收一个Taco对象并且会将Taco中的相关属性复制到自己的属性中。这样的话,我们可以很容易地将一个Taco对象转换为TacoResource。但是,如果我们就此止步,就依然需要遍历Taco列表才能将其转换成Resources<TacoResource>。
为了将Taco对象转换成TacoResource对象,我们需要创建一个资源装配器(resource assembler)。我们所需要的装配器如程序清单6.6所示。
程序清单6.6 装配taco资源的资源装配器
1 | package tacos.web.api; |
TacoResourceAssembler有一个默认的构造器,会告诉超类(ResourceAssemblerSupport)在创建TacoResource中的链接时将会使用DesignTacoController来确定所有URL的基础路径。
instantiateResource()方法进行了重写,以便基于给定的Taco实例化TacoResource。如果TacoResource有默认构造器,那么这个方法是可选的。但是,在本例中,TacoResource的构造过程需要Taco,所以我们要重写它。
最后是toResource()方法,这是在扩展ResourceAssemblerSupport时唯一强制实现的方法。在这里,我们告诉它要通过Taco创建TacoResource,并且要设置一个self链接,这个链接的URL是根据Taco对象的id属性衍生出来的。
在表面上,toResource()和instantiateResource()的用途很相似,但是它们的目的略有不同。instantiateResource()只是为了实例化一个Resource对象,而toResource()的意图不仅是创建Resource对象,还要为其填充链接。在内部,toResource()将会调用instantiateResource()。
现在,我们调整一下recentTacos(),让它使用TacoResourceAssembler:
1 |
|
在这里,recentTacos()的返回值不再是Resources<Resource<Taco>>类型,而是利用我们新定义的TacoResource类型返回了一个Resources<TacoResource>。在从repository获取taco之后,我们将Taco对象的列表传递给TacoResourceAssembler的toResources()方法。这个便利的方法会循环所有的Taco对象,调用我们在TacoResourceAssembler中重写的toResource()方法来创建TacoResource对象的列表。
在有了TacoResource列表之后,我们接下来创建了Resources<TacoResource>对象,然后像前面版本的recentTacos()一样,为其填充了recents链接。
此时,对“/design/recent”发起GET请求将会生成taco的一个列表,其中的每个taco都有一个self链接,而列表整体有一个recents链接。但是,配料目前还没有链接。为了解决这个问题,我们需要为配料创建一个新的资源装配器:
1 | package tacos.web.api; |
我们可以看到,IngredientResourceAssembler与TacoResourceAssembler非常相似,但是它使用的是Ingredient和IngredientResource对象而不是Taco和TacoResource对象。
谈到IngredientResource对象,它的源码如下所示:
1 | package tacos.web.api; |
与TacoResource类似,IngredientResource扩展了ResourceSupport,并且会将领域类型相关的属性复制到自己的属性中(id属性除外)。
接下来,我们需要修改一下TacoResource,让它能够携带IngredientResource对象,而不是Ingredient对象:
1 | package tacos.web.api; |
这个新版本的TacoResource会创建一个static final的IngredientResourceAssembler实例,并且会使用它的toResource()方法将给定Taco对象的Ingredient列表转换成IngredientResource列表。
我们现在的taco列表已经完全具备了超链接,不仅是它本身(recents链接),而且所有的taco条目和每个taco中的配料都有了超链接。响应的内容应该与程序清单6.3非常相似了。
你可以就此止步并跳到下一节,但是在此之前,我想解决程序清单6.3中一些不太理想的问题。
6.2.3 命名嵌套式的关联关系
如果你仔细看一下程序清单6.3,就会发现顶层的元素如下所示:
1 | { |
最值得注意的是在embedded之下有一个名为tacoResourceList的属性。之所以有这个名称,是因为Resources对象是通过List<TacoResource>创建出来的。尽管可能性不太大,但是假设我们将TacoResource类重构成了其他的名称,那么结果JSON中的字段名将会随之发生变化。这样,所有依赖该名称的客户端代码都会产生问题。
@Relation注解能够帮助我们消除JSON字段名和Java代码中定义的资源类名之间的耦合。通过为TacoResource添加@Relation注解,我们就能指定SpringHATEOAS该如何命名结果JSON中的字段名:
1 |
|
在这里,我们指定当在Resources对象中引用TacoResource对象列表时它应该被命名为tacos。虽然在我们的API中没有用到,但是如果在JSON中引用单个TacoResource对象,那么它的名字将会是taco。这样的话,“/design/recent”所返回的JSON将会如下所示(不管我们是否要对TacoResource进行重构,这个结构都不会发生变化):
1 | { |
借助Spring HATEOAS,向API中添加链接变得非常简单直接。尽管如此,它也会添加一些额外的代码。所以,很多开发人员会选择在API中不使用HATEOAS,但是如果API的URL模式发生变化,那么客户端代码就不可用了。所以,我建议你认真考虑一下HATEOAS,不要因为偷懒而忽略在资源中添加超链接。
如果你真的想要偷懒,那么只要你使用Spring Data来实现repository,我们就还有一个双赢的方案。接下来,我们看一下基于在第3章中使用Spring Data所创建的数据repository,如何借助Spring Data REST自动创建API。
6.1 编写RESTful控制器
6.1 编写RESTful控制器
当你翻看本章并阅读简介时,就会发现我重新设想了Taco Cloud的用户界面,希望你不要介意。你之前的工作成果可能比较适合起步,但是在美学方面也许会有所欠缺。
图6.1是新的Taco Cloud外观的示例,看上去很时尚吧?
在改善Taco Cloud外观的同时,我还决定使用流行的Angular框架将前端构建为单页应用。最终,这个新的浏览器UI将替换我们在第2章中创建的服务器渲染页面。但是,想要实现这一点,我们需要创建一个REST API,基于Angular1的UI将会与之通信,以保存和获取taco数据。
是否要采用SPA?
在第2章中,我们使用Spring MVC开发了一个传统的多页应用(MultiPageApplication,MPA),现在我们要将其替换为基于Angular的单页应用(Single-Page Application,SPA)。但是,我并不认为SPA始终是比MPA更好的可选方案。
在SPA中,展现和后端处理在很大程度上是解耦的,这样就提供了为相同的后端功能开发多个用户界面(例如原生移动应用)的机会。它还为与其他可以使用API的应用程序集成创造了可能性。但并不是所有的应用程序都需要这种灵活性,如果你只需要在Web页面上显示信息,那么MPA是一种更简单的设计。
这并不一本关于Angular的书,所以本章中的代码将会主要关注后端的Spring代码。我只会给出适当的Angular代码,以便于让你了解客户端是如何运行的。但是,请放心,完整的代码集会包括Angular前端,它们都是本书配套代码的一部分。如果你有兴趣,可以阅读Jeremy Wilken编写的Angular in Action(Manning,2018)以及Yakov Fain和Anton Moiseev编写的AngularDevelopment with TypeScript, Second Edition(Manning,2018)。
本质上来讲,Angular客户端代码将会通过HTTP请求与本章所创建的API进行通信。在第2章中,我们使用@GetMapping注解从服务端获取数据,使用@PostMapping注解往服务器端提交数据。在定义REST API的时候,这些注解依然有用。除此之外,Spring MVC还为各种类型的HTTP请求提供了一些其他的注解,如表6.1所示。
表6.1 Spring MVC的HTTP请求处理注解
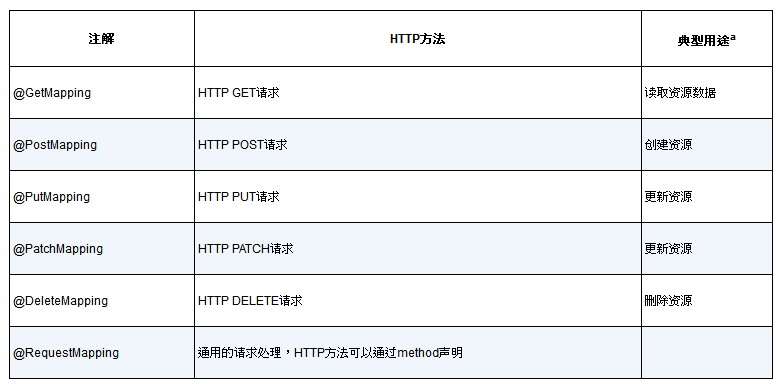
a 将HTTP方法映射为创建、读取、更新和删除(CRUD)操作并不是非常恰当,但是在实践中这是常见的使用方式,在我们的Taco Cloud应用中也是这样使用它们的。
要实际看到这些注解的效果,我们需要创建一个简单的REST端点,该端点会检索一些最新创建的taco。
6.1.1 从服务器中检索数据
Taco Cloud应用最酷的一件事就是它允许taco迷设计自己的taco作品,并与taco爱好者分享他们的作品。为此,Taco Cloud需要能够在单击“Latest Designs”链接时显示最近创建的taco列表。
在Angular代码中,我定义了RecentTacosComponent组件,它会展现最新创建的taco。RecentTacosComponent完整的TypeScript代码如程序清单6.1所示。
程序清单6.1 展现最近taco的Angular组件
1 | import { Component, OnInit, Injectable } from '@angular/core'; |
我们需要关注ngOnInit()方法。在这个方法中,RecentTacosComponent使用注入的Http模块来针对http://localhost:8080/design/recent地址发送HTTP GET请求,并期望得到一个包含taco设计的列表,它们会被放到名为recentTacos的模型属性中。视图(在recents.component.html中)会将模型数据展现为HTML的形式,以便于在浏览器中渲染。在创建完3个taco之后,最终的结果如图6.2所示。
在我们的拼图中,缺失的一部分就是端点,它会处理针对“/design/recent”的HTTP GET请求并将最近设计的taco列表作为响应。我们需要创建一个新的控制器来处理这种请求。程序清单6.2展现了完成该任务的控制器。
程序清单6.2 处理taco设计API请求的RESTful控制器
1 | package tacos.web.api; |
你可能会觉得这个控制器的名字看起来非常熟悉。在第2章中,我们创建了名为DesignTacoController的控制器,它会处理类似的请求类型。但是,当时是用来处理多页Taco Cloud应用的,这个新的DesignTacoController是一个REST控制器,是由@RestController注解声明的。
@RestController注解有两个目的。首先,它是一个类似于@Controller和@Service的构造型注解,能够让类被组件扫描功能发现。但是,与REST最密切相关之处在于,@RestController注解会告诉Spring,控制器中的所有处理器方法的返回值都要直接写入响应体中,而不是将值放到模型中并传递给一个视图以便于进行渲染。
作为替代方案,我们也可以像其他Spring MVC控制器那样为DesignTacoController添加@Controller注解。但是,这样的话,我们就需要为每个处理器方法再添加@ResponseBody注解,这样才能达到相同的效果。另外一种方案就是返回ResponseEntity对象,我们稍后将会对其进行讨论。
类级别的@RequestMapping注解,再加上recentTacos()方法上的@GetMapping注解,两者结合起来指定recentTacos()方法将会负责处理针对“/design/recent”的GET请求(这也正是Angular代码所需要的)。
你还会发现,@RequestMapping注解还设置了一个produces属性。这指明DesignTacoController中的所有处理器方法只会处理Accept头信息包含“application/json”的请求。它不仅会限制API只会生成JSON结果,同时还允许其他的控制器(比如第2章中的DesignTacoController)处理具有相同路径的请求,只要这些请求不要求JSON格式的输出就可以。尽管这样会限制API是基于JSON的,但是我们还可以将produces设置为一个String类型的数组,这样的话就允许我们设置多个内容类型。比如,为了允许生成XML格式的输出,我们可以为produces属性添加“text/xml”:
1 |
在程序清单6.2中,你可能还发现这个类添加了@CrossOrigin注解。因为应用程序的Angular部分将会运行在与API相独立的主机和/或端口上(至少目前是这样的),Web浏览器会阻止Angular客户端消费该API。我们可以在服务端响应中添加CORS(Cross-Origin Resource Sharing,跨域资源共享)头信息来突破这一限制。Spring借助@CrossOrigin注解让CORS的使用更加简单。正如我们所看到的,@CrossOrigin允许来自任何域的客户端消费该API。
recentTacos()方法中的逻辑非常简单直接。它构建了一个PageRequest对象,指明我们想要第一页(序号为0)的12条结果,并且要按照taco的创建时间降序排列。简而言之,我们想要得到12个最近创建的taco设计。PageRequest会被传递到TacoRepository的findAll()方法中,分页的结果内容则会返回到客户端(也就是在程序清单6.2中我们所看到的,它们将会以模型数据展现给用户)。
现在,假设我们想要提供一个按照ID抓取单个taco的端点。通过在处理器方法的路径上使用占位符并让方法接收一个路径变量,我们能够捕获到这个ID,然后就可以借助repository查找Taco对象了:
1 |
|
因为控制器的基础路径是“/design”,所以这个控制器方法处理的是针对“/design/{id}”的GET请求,其中路径的“{id}”部分是占位符。请求中的实际值将会传递给id参数,它通过@PathVariable注解与{id}占位符进行匹配。
在tacoById()中,id参数被传递到了repository的findById()方法中,以便于抓取Taco。findById()返回的是一个Optional<Taco>,因为根据给定的ID可能获取不到taco,所以在返回值的时候我们需要确定该ID是否能够匹配一个taco。如果能够匹配,我们可以调用Optional<Taco>对象的get()方法返回实际的Taco。
如果该ID无法匹配任何已知的taco,我们将会返回null。但是,这种做法并不完美。如果我们返回null,客户端将会接收到空的响应体以及值为200(OK)的HTTP状态码。客户端实际上接收到了一个无法使用的响应,但是状态码却提示一切正常。有一种更好的方式是在响应中使用HTTP 404 (NOT FOUND)状态。
按照现在的写法,我们没有简单的途径在tacoById()中返回404状态。但是,如果我们做一些小的调整,就可以将状态码设置成很恰当的值了:
1 |
|
现在,tacoById()返回的不是一个Taco对象,而是ResponseEntity<Taco>。如果找到taco,我们就将Taco包装到ResponseEntity中,并且会带有OK的HTTP状态(这也是之前的行为)。如果找不到taco,我们就将会在ResponseEntity中包装一个null,并且会带有NOT FOUND的HTTP状态,从而表明客户端试图抓取的taco并不存在。
我们已经有了面向Angular客户端的初始Taco Cloud API,当然它也可以用于其他类型的客户端。在开发中,我们可能还想使用像curl或HTTPie这样的命令行工具来探测该API。比如,如下的命令行展示了如何通过curl获取最新创建的taco:
1 | $ curl localhost:8080/design/recent |
如果你更喜欢HTTPie,那如下所示:
1 | $ http :8080/design/recent |
定义能够返回信息的端点仅仅是第一步。如果我们的API需要从客户端接收数据又该怎么办呢?接下来,我们看一下如何编写控制器来处理请求的输入。
6.1.2 发送数据到服务器端
到目前为止,我们的API能够返回多个最近创建的taco。但是,这些taco又是怎样创建的呢?
我们还没有删掉第2章的任何代码,所以原始的DesignTacoController还存在,它会展现taco的设计表单并处理表单的提交。这是获取测试数据来验证我们所创建的API的一个好办法。如果我们想要将Taco Cloud转换成单页应用,那么我们需要创建Angular组件以及对应的端点,以此来替换第2章中的taco设计表单。
在客户端代码方面,我们通过一个名为DesignComponent(在名为design.component.ts的文件中)的新Angular组件来处理taco设计表单。因为要处理表单提交,所以DesignComponent中有一个onSubmit()方法,如下所示:
1 | onSubmit() { |
在onSubmit()方法中,我们调用了HttpClient的post()方法而不是get()方法。这意味着我们不再是从API中抓取数据,而是向API发送数据。具体来讲,我们将一个taco设计(存放到model变量中)借助HTTP POST请求发送至“/design”的API端点上。
因此,我们需要在DesignTacoController中编写一个方法处理该请求并保存该taco设计。通过在DesignTacoController中添加如下的postTaco()方法,我们就能让控制器实现该功能:
1 |
|
因为postTaco()将会处理HTTP POST请求,所以它使用了@PostMapping注解,而不是@GetMapping。在这里,我们没有指定path属性,因此按照DesignTacoController上的类级别@RequestMapping注解,postTaco()方法将会处理对“/design”的请求。
但是,我们设置了consumes属性。consumes属性用于指定请求输入,而produces用于指定请求输出。在这里,我们使用consumes属性,表明该方法只会处理Content-type与application/json相匹配的请求。
方法的Taco参数带有@RequestBody注解,表明请求应该被转换为一个Taco对象并绑定到该参数上。这个注解是非常重要的,如果没有它,Spring MVC将会认为我们希望将请求参数(要么是查询参数,要么是表单参数)绑定到Taco上。但是,@RequestBody注解能够确保请求体中的JSON会被绑定到Taco对象上。
在postTaco()接收到Taco对象之后,就会将该对象传递给TacoRepository的save()方法。
你可能也注意到了,我为postTaco()方法添加了@ResponseStatus(HttpStatus.CREATED)注解。在正常的情况下(没有异常抛出的时候),所有响应的HTTP状态码都是200 (OK),表明请求是成功的。尽管我们始终都希望得到HTTP 200,但是有些时候它的描述性不足。在POST请求的情况下,201 (CREATED)的HTTP状态更具有描述性。它会告诉客户端,请求不仅成功了,还创建了一个资源。在适当的地方使用@ResponseStatus将最具描述性和最精确的HTTP状态码传递给客户端是一种更好的做法。
我们已经使用@PostMapping创建了新的Taco资源,除此之外,POST请求还能用来更新资源。尽管如此,POST请求通常用来创建资源,而PUT和PATCH请求通常用来更新资源。接下来,让我们看一下该如何使用@PutMapping和@PatchMapping来更新数据。
6.1.3 在服务器上更新数据
在编写控制器来处理HTTP PUT或PATCH命令之前,我们应该花点时间直面这个问题:为什么会有两种不同的HTTP方法来更新资源?
尽管PUT经常被用来更新资源,但它在语义上其实是GET的对立面。GET请求用来从服务端往客户端传输数据,而PUT请求则是从客户端往服务端发送数据。
从这个意义上讲,PUT真正的目的是执行大规模的替换(replacement)操作,而不是更新操作。HTTP PATCH的目的是对资源数据打补丁或局部更新。
例如,假设我们想要更新某个订单的地址信息。借助REST API,其中有一种实现方式就是借助如下所示的PUT请求处理器:
1 |
|
这种方式可以运行,但是它可能需要客户端将完整的订单数据从PUT请求中提交上来。从语义上讲,PUT意味着“将数据放到这个URL上”,其本质上就是替换已有的数据。如果省略了订单上的某个属性,那么该属性的值应该被null所覆盖,甚至订单中的taco也需要和订单数据一起设置,否则,它们将会从订单中移除。
如果PUT请求所做的是对资源数据的大规模替换,那么我们该如何处理局部更新的请求呢?这就是HTTP PATCH请求和Spring的@PatchMapping注解所擅长的事情了。如下展示了如何编写控制器方法来处理订单的PATCH请求:
1 |
|
这里需要关注的第一件事情就是patchOrder()方法使用了@PatchMapping注解,而不是@PutMapping注解,这表示它应该处理HTTP PATCH请求,而不是PUT请求。
有一点你肯定也注意到了,那就是patchOrder()方法比putOrder()方法要更复杂一些。这是因为Spring MVC的映射注解,虽然包括了@PatchMapping和@PutMapping,但是它们只能用来指定某个方法能够处理什么类型的请求,这些注解并没有规定该如何处理请求,尽管PATCH在语义上代表局部更新,但是在处理器方法中实际编写代码执行更新的还是我们自己。
对于putOrder()方法来说,我们得到的是完整的订单数据,然后将它保存起来,这样就完全符合HTTP PUT的语义。但是,对于patchMapping()来说,为了符合HTTP PATCH的语义,方法体需要更多的智慧才行。在这里,我们不是用新发送过来的数据完全替换已有的订单,而是探查传入Order对象的每个字段,并将所有非null的值应用到已有的订单上。这种方式允许客户端只发送要改变的属性就可以,并且对于客户端没有指定的属性,服务器端会保留已有的数据。
还有更多的方式来实现PATCH
patchOrder()方法中的PATCH操作还有一些限制:
- - 如果null意味着没有变化,那么客户端该如何指定一个字段真的要设置为null?
- - 我们没有办法移除或添加集合的子集。如果客户端想要添加或移除集合中的条目,那么它必须将变更的完整集合发送到服务器端。
关于PATCH请求该如何处理以及传入的数据该是什么样子并没有硬性的规定。客户端可以发送一个PATCH请求特定的变更描述,而不是发送真正的领域数据。当然,如果是这样,那么请求处理器方法就会改写为处理patch指令,而不是领域数据。
在@PutMapping和@PatchMapping中,需要注意引用的请求路径都是要进行变更的资源。这与@GetMapping注解标注的方法在处理路径时的方式是相同的。
我们已经看过了如何使用@GetMapping和@PostMapping获取和发送资源。同时,也看到了使用@PutMapping和@PatchMapping更新资源的两种方式。剩下的就是该如何处理删除资源的请求了。
6.1.4 删除服务器上的数据
有时,有些数据可能不再需要了。在这种场景下,客户端应该能够通过HTTPDELETE请求的形式要求移除某个资源。
Spring MVC的@DeleteMapping注解能够非常便利地声明处理DELETE请求的方法。例如,我们想要有一个能够删除订单资源的API。如下的控制器方法就能做到这一点:
1 |
|
现在,再向你解释这个映射注解就有些啰唆了。我们已经见过了@GetMapping、@PostMapping、@PutMapping和@PatchMapping,每个注解都能够指定某个方法可以处理对应类型的HTTP请求。毫无疑问,@DeleteMapping会指定deleteOrder()方法负责处理针对“/orders/{orderId}”的DELETE请求。
这个方法中的代码会负责真正删除订单。在本例中,它会接收订单ID并将其传递给repository的deleteById()方法,其中这个ID是以URL中路径变量的形式提供的。如果方法调用的时候该订单存在,就将会删除这个订单。如果订单不存在,就会抛出EmptyResultDataAccessException。
在这里,我选择捕获该EmptyResultDataAccessException异常,但是什么都没有做。在这里,我的想法是如果你尝试删除一个并不存在的资源,那么它的结果和删除之前存在这个资源是一样的。也就是,最终的效果都是资源不复存在。所以在删除之前资源是否存在并不重要。另外一种办法就是可以让deleteOrder()返回ResponseEntity,在资源不存在的时候将响应体设置为null并将HTTP状态码设置为NOT FOUND。
deleteOrder()方法唯一需要注意的是它使用了@ResponseStatus注解,以确保响应的HTTP状态码为204(NO CONTENT)。对于已经不存在的资源,我们没有必要返回任何的资源数据给客户端,因此DELETE请求通常并没有响应体,我们需要以HTTP状态码的形式让客户端知道不要期望得到任何的内容。
现在,Taco Cloud API已经基本成形了。客户端的代码可以很容易地消费我们的API,以便于显示配料、接收订单和展示最近创建的taco。但是,我们还可以更进一步,让API更易于客户端消费。接下来,我们看一下如何为Taco Cloud API添加超媒体功能。
6.0 第6章 创建REST服务
第6章 创建REST服务
本章内容:
- 在Spring MVC中定义REST端点
- 启用超链接REST资源
- 自动化基于repository的REST端点
“Web浏览器已死,那么现在是谁的天下呢?”
十多年前,我就听到有人说Web浏览器已经行将就木,它会被其他的事物所取代。但是,这怎么可能会实现呢?谁有可能取代几乎无处不在的Web浏览器呢?如果没有Web浏览器,我们该如何消费越来越多的网络站点和在线服务呢?这肯定是某个疯子的胡言乱语!
我们快进到今天,显然,Web浏览器并没有消失,但它已经不再是访问互联网的主要方式了。现在,移动设备、平板电脑、智能手表和基于语音的设备已经非常常见,甚至很多基于浏览器的应用实际上运行的都是JavaScript应用,而不再是让浏览器成为服务器渲染内容的哑终端。
随着客户端的可选方案越来越多,许多应用程序采用了一种通用的设计,那就是将用户界面推到更接近客户端的地方,而让服务器公开API,通过这种API,各种客户端都能与后端功能进行交互。
在本章中,我们将会使用Spring来为Taco Cloud应用提供REST API。在这里我们将会用到第2章中已经学习过的Spring MVC,使用Spring MVC的控制器创建RESTful端点。同时,我们还会将第4章中定义的Spring Data repository暴露为REST端点。最后,我们将会看一下如何测试和保护这些端点。首先,我们需要编写几个新的Spring MVC控制器,它们会使用REST端点来暴露后端功能,这些端点将会被富Web前端所消费。