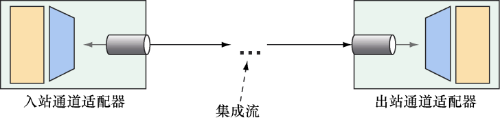
8.1 使用JMS发送消息 JMS是一个Java标准,定义了使用消息代理(message broker)的通用API,最早于2001年提出。长期以来,JMS一直是实现异步消息的首选方案。在JMS出现之前,每个消息代理都有私有的API,这就使得不同代理之间的消息代码很难通用。但是借助JMS,所有遵从规范的实现都使用通用的接口,这就好像JDBC为数据库操作提供了通用的接口一样。
Spring通过基于模板的抽象为JMS功能提供了支持,这个模板就是JmsTemplate。借助JmsTemplate,我们能够非常容易地在消息生产方发送队列和主题消息,在消费消息的那一方,也能够非常容易地接收这些消息。Spring还提供了消息驱动POJO的理念:这是一个简单的Java对象,它能够以异步的方式响应队列或主题上到达的消息。
我们将会讨论Spring对JMS的支持,包括JmsTemplate和消息驱动POJO。但是在发送和接收消息之前,我们首先需要一个消息代理(broker),它能够在消息的生产者和消费者之间传递消息。对Spring JMS的探索就从在Spring中搭建消息代理开始吧。
8.1.1 搭建JMS环境 在使用JMS之前,我们必须要将JMS客户端添加到项目的构建文件中。借助SpringBoot,这再简单不过了。我们所需要做的就是添加一个starter依赖到构建文件中。但是,首先,我们需要决定该使用Apache ActiveMQ还是更新的ApacheActiveMQ Artemis代理。
如果选择使用Apache ActiveMQ,那么我们需要添加如下的依赖到项目的pom.xml文件中:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-activemq</artifactId > </dependency >
如果选择使用ActiveMQ Artemis,那么starter依赖将会如下所示:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-artemis</artifactId > </dependency >
Artemis是重新实现的下一代ActiveMQ,使ActiveMQ变成了遗留方案。因此,Taco Cloud会选择使用Artemis。但是在编写发送和接收消息的代码方面,选择哪种方案几乎没有什么影响。唯一需要注意的重要差异就是如何配置Spring创建到代理的连接。
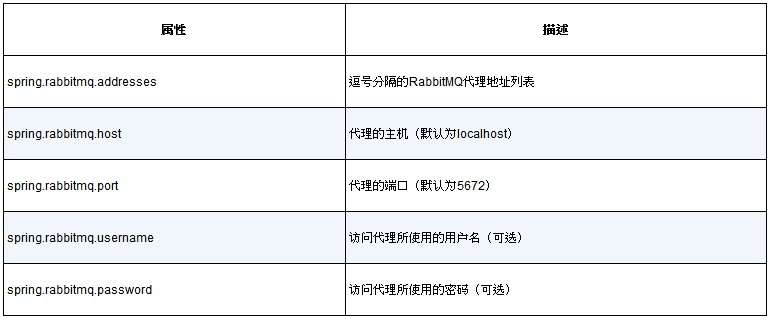
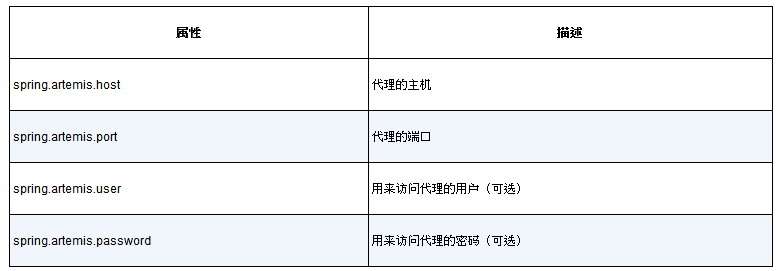
默认情况下,Spring会假定Artemis代理在localhost的61616端口运行。对于开发来说,这样是没有问题的,但是一旦要将应用部署到生产环境,我们就需要设置一些属性来告诉Spring该如何访问代理。最有用的属性如表8.1所示。
表8.1 配置Artemis代理的位置和凭证信息的属性
例如,我们看看如下的application.yml文件条目,它可能会用于一个非开发的环境:
1 2 3 4 5 6 spring: artemis: host: artemis.tacocloud.com port: 61617 user: tacoweb password: l3tm31n
这会让Spring创建到Artemis代理的连接,该Artemis代理监听artemis.tacocloud.com的61617端口。它还为应用设置了与代理交互的凭证信息。凭证信息是可选的,但是对于生产环境来说,我们推荐使用它们。
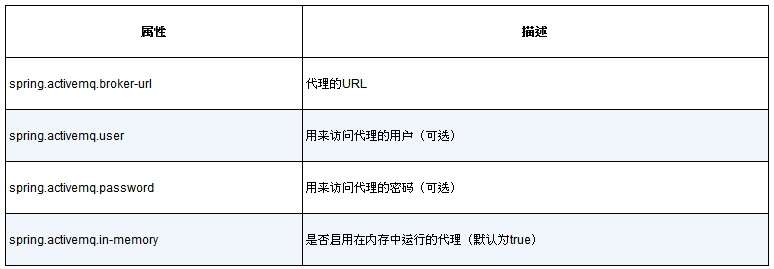
如果你选择使用ActiveMQ而不是Artemis,那么需要使用ActiveMQ特定的属性,如表8.2所示。
表8.2 配置ActiveMQ代理的位置和凭证信息的属性
需要注意,ActiveMQ代理不是分别设置代理的主机和端口,而是使用了一个名为spring.activemq.broker-url的属性来指定代理的地址。URL应该是“tcp://”协议的地址,如下面的YMAL片段所示:
1 2 3 4 5 spring: activemq: broker-url: tcp://activemq.tacocloud.com user: tacoweb password: l3tm31n
不管你是选择Artemis还是ActiveMQ,如果是在本地开发运行,那么你都不需要配置这些属性。
但是,如果你选择使用ActiveMQ,需要将spring.activemq.in-memory属性设置为false,防止Spring启动内存中运行的代理。内存中运行的代理看起来很有用,但是只有同一个应用发布和消费消息时才能使用它(这限制了它的用途)。
在继续下面的内容之前,我们要安装并启动一个Artemis(或ActiveMQ)代理,而不是选择使用嵌入式的代理。我在这里不再重复讲述安装过程,推荐你参考Artemis和ActiveMQ的文档来了解详细内容。
现在,我们已经在构建文件中添加了对JMS starter的依赖,代理也已经准备好将消息从一个应用传递到另一个应用。接下来,我们就可以开始发送消息了。
8.1.2 使用JmsTemplate发送消息 将JMS starter依赖(不管是Artemis还是ActiveMQ)添加到构建文件之后,Spring Boot会自动配置一个JmsTemplate(以及其他内容),我们可以将它注入到其他bean中,并使用它来发送和接收消息。
JmsTemplate是Spring对JMS集成支持功能的核心。与Spring其他面向模板的组件类似,JmsTemplate消除了大量传统使用JMS时所需的样板代码。如果没有JmsTemplate的话,那么我们需要编写代码来创建到消息代理的连接和会话,还要编写更多的代码来处理发送消息过程中可能出现的异常。JmsTemplate能够让我们关注真正要做的事情:发送消息。
JmsTemplate有多个用来发送消息的方法,包括:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void send (MessageCreator messageCreator) throws JmsException;void send (Destination destination, MessageCreator messageCreator) throws JmsException; void send (String destinationName, MessageCreator messageCreator) throws JmsException; void convertAndSend (Object message) throws JmsException;void convertAndSend (Destination destination, Object message) throws JmsException; void convertAndSend (String destinationName, Object message) throws JmsException; void convertAndSend (Object message, MessagePostProcessor postProcessor) throws JmsException;void convertAndSend (Destination destination, Object message, MessagePostProcessor postProcessor) throws JmsException;void convertAndSend (String destinationName, Object message, MessagePostProcessor postProcessor) throws JmsException;
我们可以看到,实际上只有两个方法,也就是send()和convertAndSend(),每个方法都有重载形式以支持不同的参数。如果我们仔细观察一下,就会发现convertAndSend()的各种形式又可以分成两个子类型。在考虑这些方法作用的时候,我们对它们进行以下细分。
3个send()方法都需要MessageCreator来生成Message对象。
3个convertAndSend()方法会接受Object对象,并且会在幕后自动将Object转换为Message。
3个convertAndSend()会自动将Object转换为Message,但同时还能接受一个MessagePostProcessor对象,用来在发送之前对Message进行自定义。
这3种方法分类都分别包含3个重载方法,它们的区别在于如何指定JMS的目的地(队列或主题)。
有1个方法不接受目的地参数,它会将消息发送至默认的目的地。
有1个方法接受Destination对象,该对象指定了消息的目的地。
有1个方法接受String,它通过名字的形式指定了消息的目的地。
要让这些方法真正发挥作用,我们看一下程序清单8.1中的JmsOrderMessagingService,它使用了形式最简单的send()方法。
程序清单8.1 使用.send()方法将订单发送至默认的目的地
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package tacos.messaging;import javax.jms.JMSException;import javax.jms.Message;import javax.jms.Session;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jms.core.JmsTemplate;import org.springframework.jms.core.MessageCreator;import org.springframework.stereotype.Service;@Service public class JmsOrderMessagingService implements OrderMessagingService { private JmsTemplate jms; @Autowired public JmsOrderMessagingService (JmsTemplate jms) { this .jms = jms; } @Override public void sendOrder (Order order) { jms.send(new MessageCreator () { @Override public Message createMessage (Session session) throws JMSException { return session.createObjectMessage(order); } } ); } }
sendOrder()方法调用了jms.send(),并传递了MessageCreator接口的一个匿名内部实现。这个实现类重写了createMessage()方法,从而能够通过给定的Order对象创建新的对象消息。
我不知道你的感觉如何,但是我认为程序清单8.1虽然比较直接,但还是有点啰唆。声明匿名内部类的过程使得原本很简单的方法调用变得很复杂。我们发现MessageCreator是一个函数式接口,所以我们可以通过lambda表达式简化一下sendOrder()方法:
1 2 3 4 @Override public void sendOrder (Order order) { jms.send(session -> session.createObjectMessage(order)); }
但是,需要注意对jms.send()的调用并没有指定目的地。为了让它能够运行,我们需要通过名为spring.jms.template.default-destination的属性声明一个默认的目的地名称。例如,我们可以在application.yml文件中这样设置该属性:
1 2 3 4 spring: jms: template: default-destination: tacocloud.order.queue
在很多场景下,使用默认的目的地是最简单的可选方案。借助它,我们只声明一次目的地名称就可以了,代码只关心发送消息,而无须关心消息会发到哪里。但是,如果我们要将消息发送至默认目的地之外的其他地方,那么我们需要通过为send()设置参数来进行指定。
其中一种方式就是传递Destination对象作为send()方法的第一个参数。最简单的方式就是声明一个Destination bean并将其注入处理消息的bean中。例如,如下的bean声明Taco Cloud订单队列的Destination:
1 2 3 4 @Bean public Destination orderQueue () { return new ActiveMQQueue ("tacocloud.order.queue" ); }
很重要的一点需要注意,这里的ActiveMQQueue来源于Artemis(来自org.apache. activemq.artemis.jms.client包)。如果选择使用ActiveMQ(而不是Artemis),那么同样有一个名为ActiveMQQueue的类(来自org.apache.activemq.command包)。
在Destination bean注入到JmsOrderMessagingService之后,调用send()的时候,我们就可以使用它来指定目的地了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private Destination orderQueue;@Autowired public JmsOrderMessagingService (JmsTemplate jms, Destination orderQueue) { this .jms = jms; this .orderQueue = orderQueue; } ... @Override public void sendOrder (Order order) { jms.send( orderQueue, session -> session.createObjectMessage(order)); }
通过Destination指定目的地的时候,我们其实可以设置Destination的更多属性,而不仅仅是目的地的名称。但是,在实践中,除了目的地名称我们几乎不会设置其他的属性。因此,使用名称作为send()的第一个参数会更加简单:
1 2 3 4 5 6 @Override public void sendOrder (Order order) { jms.send( "tacocloud.order.queue" , session -> session.createObjectMessage(order)); }
尽管send()方法使用起来并不是特别困难(尤其是通过lambda表达式来实现MessageCreator的时候更是如此),但是它要求我们提供MessageCreator还是增加了一点复杂性。如果我们能够只指定要发送的对象(以及可能要用到的目的地),那岂不是更简单?这其实就是convertAndSend()的工作原理。接下来,我们看一下这种方式。
消息发送之前进行转换 JmsTemplates的convertAndSend()方法简化了消息的发布,因为它不再需要MessageCreator。我们将要发送的对象直接传递给convertAndSend(),这个对象在发送之前会被转换成Message。
例如,在如下重新实现的sendOrder()方法中,使用convertAndSend()将Order对象发送到给定名称的目的地:
1 2 3 4 @Override public void sendOrder (Order order) { jms.convertAndSend("tacocloud.order.queue" , order); }
与send()方法类似,convertAndSend()将会接受一个Destination对象或String值来确定目的地,我们也可以完全忽略目的地,将消息发送到默认目的地上。
不管使用哪种形式的convertAndSend(),传递给convertAndSend()的Order都会在发送之前转换成Message。在底层,这是通过MessageConverter的实现类来完成的,它替我们做了将对象转换成Message的脏活累活。
配置消息转换器 MessageConverter是Spring定义的接口,只有两个需要实现的方法:
1 2 3 4 5 public interface MessageConverter { Message toMessage (Object object, Session session) throws JMSException, MessageConversionException; Object fromMessage (Message message) }
尽管这个接口实现起来很简单,但我们通常并没有必要创建自定义的实现。Spring已经提供了多个实现,如表8.3所示。
表8.3 Spring为通用的转换任务提供了多个消息转换器(所有的消息转换器都位于org.springframework.jms.support.converter包中)
默认情况下,将会使用SimpleMessageConverter,但是它需要被发送的对象实现Serializable。这种办法可能也不错,但有时候我们可能想要使用其他的消息转换器来消除这种限制,比如MappingJackson2MessageConverter。
为了使用不同的消息转换器,我们必须要做的事情就是将选中的消息转换器实例声明为一个bean。例如,如下的bean声明将会使用MappingJackson2MessageConverter替代SimpleMessageConverter:
1 2 3 4 5 6 7 @Bean public MappingJackson2MessageConverter messageConverter () { MappingJackson2MessageConverter messageConverter = new MappingJackson2MessageConverter (); messageConverter.setTypeIdPropertyName("_typeId" ); return messageConverter; }
需要注意,在返回之前,我们调用了MappingJackson2MessageConverter的setTypeId PropertyName()方法。这非常重要,因为这样能够让接收者知道传入的消息要转换成什么类型。默认情况下,它将会包含要转换的类型的全限定类名。但是,这样的话会不太灵活,要求接收端也包含相同的类型,并且具有相同的全限定类名。
为了实现更大的灵活性,我们可以通过调用消息转换器的setTypeIdMappings()方法将一个合成类型名映射到实际类型上。举例来说,消息转换器bean方法的如下代码变更会将一个合成的order类型ID映射为Order类:
1 2 3 4 5 6 7 8 9 10 @Bean public MappingJackson2MessageConverter messageConverter () { MappingJackson2MessageConverter messageConverter = new MappingJackson2MessageConverter (); messageConverter.setTypeIdPropertyName("_typeId" ); Map<String, Class<?>> typeIdMappings = new HashMap <String, Class<?>>(); typeIdMappings.put("order" , Order.class); messageConverter.setTypeIdMappings(typeIdMappings); return messageConverter; }
这样的话,消息的_typeId属性中就不用发送全限定类型了,而是会发送order值。在接收端的应用中,将会配置类似的消息转换器,将order映射为它自己能够理解的订单类型。在接收端的订单可能位于不同的包中、有不同的类名,甚至可以只包含发送者Order属性的一个子集。
对消息进行后期处理 假设除了利润丰厚的Web业务之外,Taco Cloud还决定开几家实体的连锁taco店,鉴于任何一家餐馆都可能成为Web业务的运行中心,在餐馆中他们需要有一种方式告诉厨房订单的来源,这样厨房的工作人员就能为店面里的订单和Web上的订单执行不同的流程。
我们尽可以在Order对象上添加一个新的source属性,让它携带该信息:如果是在线订单,就将其设置为WEB;如果是店面里的订单,就将其设置为STORE。但是,这样我们就需要同时修改Web站点的Order类和厨房应用的Order类,但实际上只有taco的准备人员需要该信息。
有一种更简单的方案,就是为消息添加一个自定义的头部,让它携带订单的来源。如果我们使用send()方法来发送taco订单,那么通过调用Message对象的setStringProperty()方法非常容易实现:
1 2 3 4 5 jms.send("tacocloud.order.queue" , session -> { Message message = session.createObjectMessage(order); message.setStringProperty("X_ORDER_SOURCE" , "WEB" ); });
但是,这里的问题在于我们并没有使用send()。在使用convertAndSend()方法的时候,Message是在底层创建的,我们无法访问到它。
幸好,还有一种方式能够在发送之前修改底层创建的Message对象。我们可以传递一个MessagePostProcessor作为convertAndSend()的最后一个参数,借助它我们可以在Message创建之后做任何想做的事情。如下的代码依然使用了convertAndSend(),但是它能够在消息发送之前使用MessagePostProcessor添加X_ORDER_SOURCE头信息:
1 2 3 4 5 6 7 jms.convertAndSend("tacocloud.order.queue" , order, new MessagePostProcessor () { @Override public Message postProcessMessage (Message message) throws JMSException { message.setStringProperty("X_ORDER_SOURCE" , "WEB" ); return message; } });
你可能已经发现MessagePostProcessor是一个函数式接口。这意味着我们可以将匿名内部类替换为lambda,进一步简化它:
1 2 3 4 5 jms.convertAndSend("tacocloud.order.queue" , order, message -> { message.setStringProperty("X_ORDER_SOURCE" , "WEB" ); return message; });
尽管在这里我们只是将这个特殊的MessagePostProcessor用到了本次convertAndSend()方法调用中,但是你可能会发现在你的代码中会在不同的地方多次调用convertAndSend(),它们均会用到相同的MessagePostProcessor。在这种情况下,方法引用是比lambda更好的方案,它能避免不必要的代码重复:
1 2 3 4 5 6 7 8 9 10 11 @GetMapping("/convertAndSend/order") public String convertAndSendOrder () { Order order = buildOrder(); jms.convertAndSend("tacocloud.order.queue" , order, this ::addOrderSource); return "Convert and sent order" ; } private Message addOrderSource (Message message) throws JMSException { message.setStringProperty("X_ORDER_SOURCE" , "WEB" ); return message; }
我们已经看到了多种发送消息的方式,但是如果消息无人接收,那么只发送消息也没什么价值。接下来,我们看一下如何使用Spring和JMS接收消息。
8.1.3 接收JMS消息 在消费消息的时候,我们可以选择拉取模式(pull model)和推送模式(pushmodel),前者会在我们的代码中请求消息并一直等待直到消息到达为止,而后者则会在消息可用的时候自动在你的代码中执行。
JmsTemplate提供了多种方式来接收消息,但它们使用的都是拉取模式。我们可以调用其中的某个方法来请求消息,而线程会一直阻塞到一个消息抵达为止(这可能马上发生,也可能需要等待一会儿)。
另外,我们也可以使用推送模式,在这种情况下,我们会定义一个消息监听器,每当有消息可用时,它就会被调用。
这两种方案能够适用于各种用户场景。人们普遍觉得推送模式是更好的方案,因为它不会阻塞线程;但是,在某些场景下,如果消息抵达的速度太快,那么监听器可能会过载。而拉取模式允许消费者声明它们何时才为接收新消息做好准备。
我们将会看一下这两种方案,首先从JmsTemplate提供的拉取模式开始。
使用JmsTemplate来接收消息 JmsTemplate提供了多个对代理的拉取方法,其中包括:
1 2 3 4 5 6 Message receive () throws JmsException; Message receive (Destination destination) throws JmsException; Message receive (String destinationName) throws JmsException; Object receiveAndConvert () throws JmsException; Object receiveAndConvert (Destination destination) throws JmsException; Object receiveAndConvert (String destinationName) throws JmsException;
我们可以看到,这6个方法简直就是JmsTemplate中send()和convertAndSend()方法的镜像。receive()方法接收原始的Message,而receiveAndConvert()则会使用一个配置好的消息转换器将消息转换成领域对象。对于其中的每种方法,我们都可以指定Destination或者包含目的地名称的String值,否则,我们将会从默认目的地拉取消息。
为了实际看一下它是如何运行的,我们编写代码从tacocloud.order.queue目的地拉取一个Order。程序清单8.2展现了OrderReceiver,这个服务组件会使用JmsTemplate.receive()来接收订单数据。
程序清单8.2 从队列拉取订单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package tacos.kitchen.messaging.jms;import javax.jms.Message;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jms.core.JmsTemplate;import org.springframework.jms.support.converter.MessageConverter;import org.springframework.stereotype.Component;@Component public class JmsOrderReceiver implements OrderReceiver { private JmsTemplate jms; private MessageConverter converter; @Autowired public JmsOrderReceiver (JmsTemplate jms, MessageConverter converter) { this .jms = jms; this .converter = converter; } public Order receiveOrder () { Message message = jms.receive("tacocloud.order.queue" ); return (Order) converter.fromMessage(message); } }
这里我们使用String值来指定从哪个目的地拉取订单。receive()返回的是没有经过转换的Message,但是,我们真正需要的是Message中的Order,所以接下来我们要做的事情就是使用被注入的消息转换器对消息进行转换。消息中的type ID属性将会指导转换器将消息转换成Order,但它返回的是Object,所以在最终返回之前要进行类型转换。
如果我们要探查消息的属性和消息头信息,那么接收原始的Message对象可能会非常有用。但是,通常来讲,我们只需要消息的载荷。将载荷转换成领域对象是一个需要两步操作的过程,而且它需要将消息转换器注入组件中。如果你只关心载荷,那么使用receiveAndConvert()会更简单一些。程序清单8.3展现了如何使用receiveAndConvert()替换receive()来重新实现JmsOrderReceiver。
程序清单8.3 接收已经转换好的Order对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package tacos.kitchen.messaging.jms;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jms.core.JmsTemplate;import org.springframework.stereotype.Component;@Component public class JmsOrderReceiver implements OrderReceiver { private JmsTemplate jms; @Autowired public JmsOrderReceiver (JmsTemplate jms) { this .jms = jms; } public Order receiveOrder () { return (Order) jms.receiveAndConvert("tacocloud.order.queue" ); } }
这个新版本的JmsOrderReceiver的receieveOrder()被简化到了只有一行代码。同时,我们不再需要将MessageConverter注入进来了,因为所有的操作都会在receiveAndConvert()方法的幕后完成。
在继续学习下面的内容之前,我们考虑一下如何在Taco Cloud厨房应用中使用receiveOrder()。Taco Cloud厨房中的厨师可能会按下一个按钮或者采取其他操作,表明他已经准备好开始做taco了。此时,receiveOrder()会被调用,然后对receive()或receiveAndConvert()的调用将会阻塞。在订单消息抵达之前,这里不会发生任何事情。一旦订单抵达,对receiveOrder()的调用将会把该订单信息返回,订单的详细信息会展现给厨师,这样他就可以开始工作了。对于拉取模式来说,这似乎是一种很自然的选择。
接下来,我们看一下如何通过声明JMS监听器来实现推送模式。
声明消息监听器 拉取模式需要显式调用receive()或receiveAndConvert()才能接收消息,与之不同,消息监听器是一个被动的组件,在消息抵达之前,它会一直处于空闲状态。
要创建能够对JMS消息做出反应的消息监听器,我们需要为组件中的某个方法添加@JmsListener注解。程序清单8.4展示了一个新的OrderListener组件,它会被动地监听消息,而不是主动请求消息。
程序清单8.4 监听订单消息的OrderListener组件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package tacos.kitchen.messaging.jms.listener;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jms.annotation.JmsListener;import org.springframework.stereotype.Component;@Component public class OrderListener { private KitchenUI ui; @Autowired public OrderListener (KitchenUI ui) { this .ui = ui; } @JmsListener(destination = "tacocloud.order.queue") public void receiveOrder (Order order) { ui.displayOrder(order); } }
receiveOrder()方法使用了JmsListener注解,这样它就会监听tacocloud.order.queue目的地的消息。该方法不需要使用JmsTemplate,也不会被你的应用显式调用。相反,Spring中的框架代码会等待消息抵达指定的目的地,当消息到达时,receiveOrder()方法会被自动调用,并且会将消息中的Order载荷作为参数。
从很多方面来讲,@JmsListener注解都和Spring MVC中的请求映射注解很相似,比如@GetMapping或@PostMapping。在Spring MVC中,带有请求映射注解的方法会响应指定路径的请求。与之类似,使用@JmsListener注解的方法会对到达指定目的地的消息做出响应。
消息监听器通常被视为最佳选择,因为它不会导致阻塞,并且能够快速处理多个消息。但是在Taco Cloud中,它可能并不是最佳的方案。在系统中,厨师是一个重要的瓶颈,他们可能无法在接收到订单的时候立即准备taco。当新订单出现在屏幕上的时候,可能上一个订单刚刚完成一半。厨房用户界面需要在订单到达时进行缓冲,避免给厨房人员带来过重的负载。
这并不是说消息监听器不好。相反,如果消息能够快速得到处理,那么它们是非常适合的方案。但是,如果消息处理器需要根据自己的时间请求更多消息,那么JmsTemplate提供的拉取模式会更加合适。
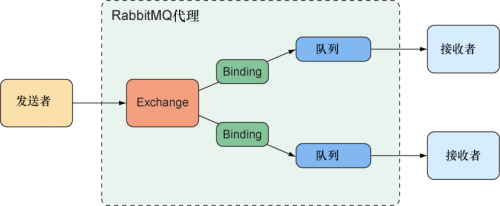
JMS是由标准Java规范定义的,所以它得到了众多代理实现的支持,在Java中实现消息时它是常见的可选方案。但是JMS有一些缺点,尤其是作为Java规范,它只能用在Java应用中。RabbitMQ和Kafka等较新的消息传递方案克服了这些缺点,可以用于JVM之外的其他语言和平台。让我们把JMS放在一边,看看如何使用RabbitMQ实现taco订单的消息传递。