10.3 使用常见的反应式操作 Flux和Mono是Reactor提供的最基础的构建块,而这两种反应式类型所提供的操作符则是组合使用它们以构建数据流动管线的黏合剂。Flux和Mono共有500多个操作,这些操作都可以大致归类为:
虽然对这500多个操作一一探讨会非常有趣,但是本章的篇幅有限,所以我在本节中选择一些有用的操作来进行说明。下面让我们从创建操作开始吧。
注意:Mono的例子呢?因为Mono和Flux的很多操作是相同的,所以没有必要针对Mono和Flux重复进行介绍。此外,虽然Mono的操作也很有用,但是相比而言,Flux上的操作更有趣。我们的大多数示例会使用Flux。读者只需要知道Mono上通常具有相同的名称的操作即可。
10.3.1 创建反应式类型 在Spring中使用反应式类型时,我们通常将会从repository或者service中获取Flux或Mono,并不需要我们自行创建。偶尔,我们可能需要创建一个新的反应式Publisher。
Reactor提供了多种创建Flux和Mono的操作。这里,我们将介绍其中一些有用的创建操作。
根据对象创建 如果你有一个或多个对象,并想据此创建Flux或Mono,那么可以使用Flux或Mono上的静态just()方法来创建一个反应式类型,它们的数据会由这些对象来驱动。例如,下面的测试方法将从5个String对象中创建一个Flux:
1 2 3 4 5 @Test public void createAFlux_just () { Flux<String> fruitFlux = Flux .just("Apple" , "Orange" , "Grape" , "Banana" , "Strawberry" ); }
此时我们已经创建了Flux,但是它还没有订阅者。如果没有任何的订阅者,那么数据将不会流动。回想一下花园软管的比喻,假设我们已经将花园软管连接到了水龙头上,另一侧是水厂的水——但是在你打开水龙头之前,水不会流动。订阅反应式类型就如同你打开数据流的水龙头。
要添加一个订阅者,我们可以在Flux上调用subscribe()方法:
1 2 3 fruitFlux.subscribe( f -> System.out.println("Here's some fruit: " + f) );
这里传递给subscribe()方法的lambda表达式实际上是一个java.util.Consumer,用来创建反应式流的Subscriber。在调用subscribe()之后,数据会开始流动。在这个例子中,没有中间操作,所以数据从Flux直接流向订阅者。
将来自Flux或Mono的数据项打印到控制台是观察反应式类型运行方式的好方法,实际测试Flux或Mono更好的方法是使用Reactor提供的StepVerifier。对于给定的Flux或Mono,StepVerifier将会订阅该反应式类型,在数据流过时对数据应用断言,并在最后验证反应式流是否按预期完成。
例如,要验证预定义的数据是否流经了fruitFlux,我们可以编写如下所示的测试代码:
1 2 3 4 5 6 7 StepVerifier.create(fruitFlux) .expectNext("Apple" ) .expectNext("Orange" ) .expectNext("Grape" ) .expectNext("Banana" ) .expectNext("Strawberry" ) .verifyComplete();
在这个例子中,StepVerifier订阅了fruitFlux,然后断言Flux中的每个数据项是否与预期的水果名称相匹配。最后,它验证Flux在发布完“Strawberry”之后,整个fruitFlux正常完成。
对于本章的其他例子,你可以使用StepVerifier来编写测试,验证Flux或者Mono行为,研究相应的工作原理,从而帮助你学习和了解Reactor中最有用的操作。
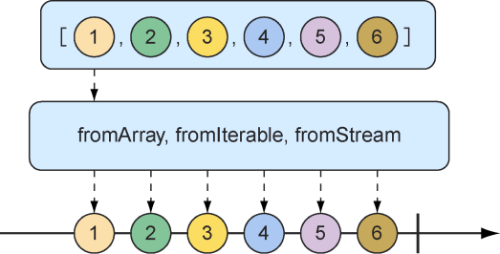
根据集合创建 我们还可以根据数组、Iterable或者Java Stream创建Flux。图10.3使用弹珠图展示如何使用这种方式进行创建。
图10.3 可以根据数组、Iterable或者Java Stream创建Flux
要根据数组创建Flux,可以调用Flux上的静态方法fromArray(),并传入一个源数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void createAFlux_fromArray () { String[] fruits = new String [] { "Apple" , "Orange" , "Grape" , "Banana" , "Strawberry" }; Flux<String> fruitFlux = Flux.fromArray(fruits); StepVerifier.create(fruitFlux) .expectNext("Apple" ) .expectNext("Orange" ) .expectNext("Grape" ) .expectNext("Banana" ) .expectNext("Strawberry" ) .verifyComplete(); }
因为该源数组包含了之前从对象列表创建Flux时所使用的相同的水果名称,所以该Flux发布的数据会有相同的值,可以使用和之前相同的StepVerifier来验证。
如果我们需要根据java.util.List、java.util.Set或者其他任意java.lang.Iterable的实现来创建Flux,那么可以将其传递给静态的fromIterable()方法:
1 2 3 4 5 6 7 8 9 10 11 @Test public void createAFlux_fromIterable () { List<String> fruitList = new ArrayList <>(); fruitList.add("Apple" ); fruitList.add("Orange" ); fruitList.add("Grape" ); fruitList.add("Banana" ); fruitList.add("Strawberry" ); Flux<String> fruitFlux = Flux.fromIterable(fruitList); }
或者,我们有一个Java Stream,并且希望将其用作Flux的源,那么可以调用fromStream()方法:
1 2 3 4 5 6 7 @Test public void createAFlux_fromStream () { Stream<String> fruitStream = Stream.of("Apple" , "Orange" , "Grape" , "Banana" , "Strawberry" ); Flux<String> fruitFlux = Flux.fromStream(fruitStream); }
同样,我们可以使用和之前一样的StepVerifier来验证该Flux发布的数据。
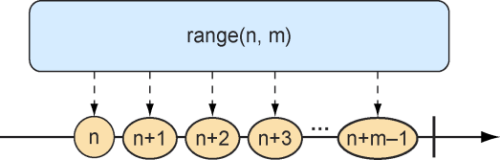
生成Flux的数据 有时候我们根本没有可用的数据,而只是想要一个作为计数器的Flux,它会在每次发送新值时增加1。要创建一个计数器Flux,我们可以使用静态方法range()。图10.4说明了range()方法的工作原理。
图10.4 从区间创建的Flux会以类似计数器的方式发布消息
下面的测试方法展示了如何创建一个区间Flux:
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void createAFlux_range () { Flux<Integer> intervalFlux = Flux.range(1 , 5 ); StepVerifier.create(intervalFlux) .expectNext(1 ) .expectNext(2 ) .expectNext(3 ) .expectNext(4 ) .expectNext(5 ) .verifyComplete(); }
在这个例子中,我们创建了一个区间Flux,起始值为1,结束值为5。StepVerifier证明了它将发布5个条目,即整数1到5。
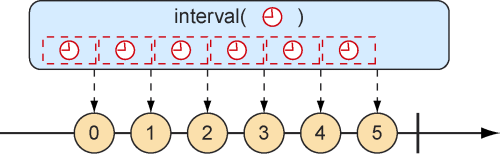
另一个与range()方法类似的Flux创建方法是interval()。与range()方法一样,interval()方法会创建一个发布递增值的Flux。interval()的特殊之处在于,我们不是给它设置一个起始值和结束值,而是指定一个应该每隔多长时间发出值的间隔时间。图10.5展示了interval()方法创建Flux的弹珠图。
图10.5 根据指定间隔创建的Flux会周期性地发布条目
例如,要创建一个每秒发布一个值的Flux,你可以使用Flux上的静态interval() 方法,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void createAFlux_interval () { Flux<Long> intervalFlux = Flux.interval(Duration.ofSeconds(1 )) .take(5 ); StepVerifier.create(intervalFlux) .expectNext(0L ) .expectNext(1L ) .expectNext(2L ) .expectNext(3L ) .expectNext(4L ) .verifyComplete(); }
需要注意的是,通过interval()方法创建的Flux会从0开始发布值,并且后续的条目依次递增。此外,因为interval()方法没有指定最大值,所以它可能会永远运行。我们也可以使用take()方法将结果限制为前5个条目。我们将在下一节中详细讨论take()方法。
10.3.2 组合反应式类型 有时候,我们会需要操作两种反应式类型,并以某种方式将它们合并在一起。或者,在其他情况下,我们可能需要将Flux拆分为多种反应式类型。在本节中,我们将研究组合以及拆分Reactor的Flux和Mono的操作。
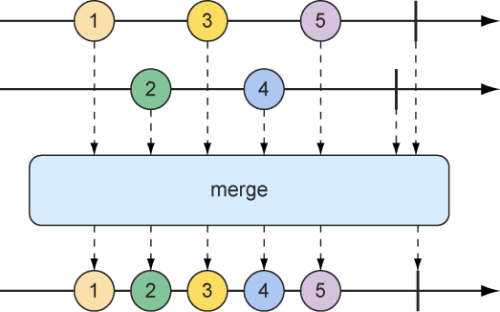
合并反应式类型 假设我们有两个Flux流,并且需要据此创建一个结果Flux,这个形成的Flux会在任意上游Flux流有数据时产生数据。要将一个Flux与另一个Flux合并,可以使用mergeWith()方法,如图10.6中的弹珠图所示。
图10.6 合并两个Flux流(它们的消息将会交错合并为一个新的Flux)
例如,假设有一个值是电视和电影角色名称的Flux,还有另一个值是这些角色喜欢吃的食物的名称的Flux。下面的测试方法展示了如何使用mergeWith()方法合并两个Flux对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void mergeFluxes () { Flux<String> characterFlux = Flux .just("Garfield" , "Kojak" , "Barbossa" ) .delayElements(Duration.ofMillis(500 )); Flux<String> foodFlux = Flux .just("Lasagna" , "Lollipops" , "Apples" ) .delaySubscription(Duration.ofMillis(250 )) .delayElements(Duration.ofMillis(500 )); Flux<String> mergedFlux = characterFlux.mergeWith(foodFlux); StepVerifier.create(mergedFlux) .expectNext("Garfield" ) .expectNext("Lasagna" ) .expectNext("Kojak" ) .expectNext("Lollipops" ) .expectNext("Barbossa" ) .expectNext("Apples" ) .verifyComplete(); }
通常,Flux会尽可能快地发布数据。因此,我们在创建的两个Flux流上使用delayElements()方法来减慢它们的速度——每500毫秒发布一个条目。此外,为了使食物Flux在角色名称Flux之后再开始流式传输,我们调用了食物Flux上的delaySubscription()方法,以便它在订阅后再经过250毫秒后才开始发布数据。
在合并了两个Flux对象后,将会创建一个新的合并过后的Flux。当StepVerifier订阅这个合并过后的Flux时,它将依次订阅两个源Flux流并启动数据流。
这个合并过后的Flux数据项发布顺序与源Flux的发布时间一致。因为两个Flux对象都设置为以常规速率进行发布,所以这些值在合并后的Flux中会交错在一起,结果是:一个角色、一个食物、另一个角色、另一个食物,以此类推。如果任何一个Flux的计时发生变化,那么你可能会看到接连发布了两个角色或者两个食物。
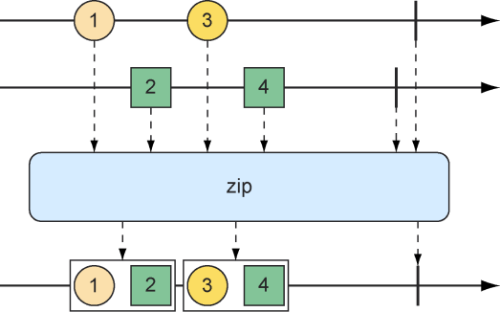
因为mergeWith()方法不能完美地保证源Flux之间的先后顺序,所以我们可以考虑使用zip()方法。当两个Flux对象压缩在一起的时候,它将会产生一个新的发布元组的Flux,其中每个元组中都包含了来自每个源Flux的数据项。图10.7说明了如何将两个Flux对象压缩在一起。
图10.7 通过zip()方法合并两个Flux流
要查看zip()操作实际如何运行,可以考虑如下所示的测试方法,它将角色Flux和食物Flux合并在一起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void zipFluxes () { Flux<String> characterFlux = Flux .just("Garfield" , "Kojak" , "Barbossa" ); Flux<String> foodFlux = Flux .just("Lasagna" , "Lollipops" , "Apples" ); Flux<Tuple2<String, String>> zippedFlux = Flux.zip(characterFlux, foodFlux); StepVerifier.create(zippedFlux) .expectNextMatches(p -> p.getT1().equals("Garfield" ) && p.getT2().equals("Lasagna" )) .expectNextMatches(p -> p.getT1().equals("Kojak" ) && p.getT2().equals("Lollipops" )) .expectNextMatches(p -> p.getT1().equals("Barbossa" ) && p.getT2().equals("Apples" )) .verifyComplete(); }
需要注意的是,与mergeWith()方法不同,zip()方法是一个静态的创建操作。创建出来的Flux在角色和他们喜欢的食物之间会完美对齐。从这个合并后的Flux发出的每个条目都是一个Tuple2(一个容纳两个其他对象的容器对象)的实例,其中包含了来自每个源Flux的数据项,并保持着它们发布的顺序。
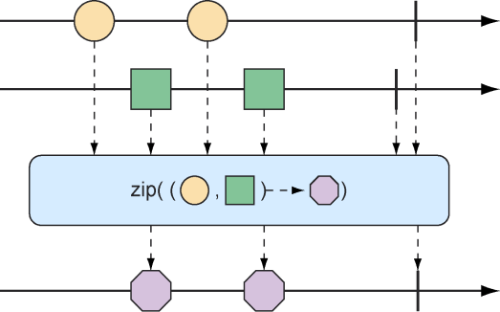
如果你不想使用Tuple2,而想要使用其他类型,就可以为zip()方法提供一个合并函数来生成你想要的任何对象,合并函数会传入这两个数据项(如图10.8中的弹珠图所示)。
图10.8 zip操作的另一种形式(从每个传入Flux中各取一个元素,然后创建消息对象,并产生这些消息组成的Flux)
例如,下面的测试方法会将角色Flux与食物Flux合并在一起,以便生成一个包含String对象的Flux:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test public void zipFluxesToObject () { Flux<String> characterFlux = Flux .just("Garfield" , "Kojak" , "Barbossa" ); Flux<String> foodFlux = Flux .just("Lasagna" , "Lollipops" , "Apples" ); Flux<String> zippedFlux = Flux.zip(characterFlux, foodFlux, (c, f) -> c + " eats " + f); StepVerifier.create(zippedFlux) .expectNext("Garfield eats Lasagna" ) .expectNext("Kojak eats Lollipops" ) .expectNext("Barbossa eats Apples" ) .verifyComplete(); }
传递给zip()方法(在这里是一个lambda)的函数只是简单地将两个数据项组装成一个句子,然后通过该合并后的Flux发布出去。
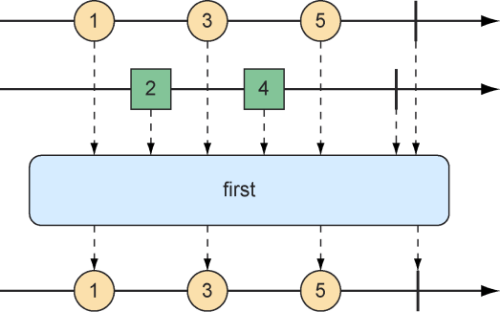
选择第一个反应式类型进行发布 假设我们有两个Flux对象,此时我们不想将它们合并在一起,而是想要创建一个新的Flux,让这个新的Flux从第一个产生值的Flux中发布值。如图10.9所示,first()操作会在两个Flux对象中选择第一个发布值的Flux,并再次发布它的值。
图10.9 first操作将会选择第一个发布消息的Flux并只发布该Flux的值
下面的测试方法创建了一个快速的Flux和一个“缓慢”的Flux(其中“慢”意味着它在被订阅后100毫秒才会发布数据项)。使用first()方法,它将会创建一个新的Flux,这个Flux只会获取第一个源Flux发布的值,并再次发布:
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void firstFlux () { Flux<String> slowFlux = Flux.just("tortoise" , "snail" , "sloth" ) .delaySubscription(Duration.ofMillis(100 )); Flux<String> fastFlux = Flux.just("hare" , "cheetah" , "squirrel" ); Flux<String> firstFlux = Flux.first(slowFlux, fastFlux); StepVerifier.create(firstFlux) .expectNext("hare" ) .expectNext("cheetah" ) .expectNext("squirrel" ) .verifyComplete(); }
在这种情况下,因为慢速Flux会在快速Flux开始发布之后的100毫秒才发布值,所以新创建的Flux将会简单地忽略慢的Flux,并仅发布来自快速Flux的值。
10.3.3 转换和过滤反应式流 在数据流经一个流时,我们通常需要过滤掉某些值并对其他的值进行处理。在这一节,我们将介绍转换和过滤流经反应式流的数据的操作。
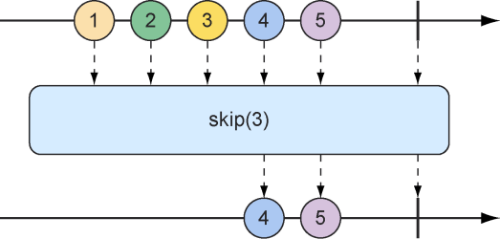
从反应式类型中过滤数据 数据在从Flux流出时,进行过滤的最基本方法之一是简单地忽略第一批指定数目的数据项。skip操作(如图10.10所示)就能完成这样的工作。
图10.10 skip操作跳过指定数目的消息并将剩下的消息继续在结果Flux上进行传递
针对具有多个数据项的Flux,skip操作将创建一个新的Flux,它会首先跳过指定数量的数据项,然后从源Flux中发布剩余的数据项。下面的测试方法展示如何使用skip()方法:
1 2 3 4 5 6 7 8 9 @Test public void skipAFew () { Flux<String> skipFlux = Flux.just( "one" , "two" , "skip a few" , "ninety nine" , "one hundred" ) .skip(3 ); StepVerifier.create(skipFlux) .expectNext("ninety nine" , "one hundred" ) .verifyComplete(); }
在这个场景下,我们有一个具有5个String数据项的Flux。在这个Flux上调用skip(3)方法后会产生一个新的Flux,它会跳过前3个数据项,只发布最后2个数据项。
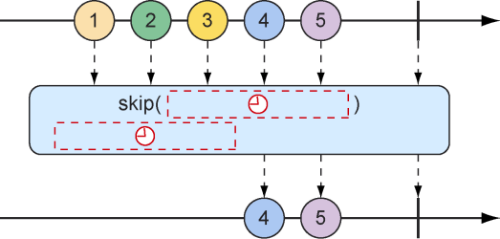
但是,你可能并不想跳过特定数量的条目,而是想要在一段时间之内跳过所有的第一批数据。这是skip()操作的另一种形式,将会产生一个新Flux,在发布来自源Flux的数据项之前等待指定的一段时间,如图10.11所示。
图10.11 skip操作的另一种形式
下面的测试方法使用skip操作创建了一个在发布值之前会等待4秒的Flux。因为Flux是基于一个在发布数据项之间有1秒延迟的Flux创建的(使用了delayElements()操作),所以它只会发布出最后两个数据项:
1 2 3 4 5 6 7 8 9 10 @Test public void skipAFewSeconds () { Flux<String> skipFlux = Flux.just( "one" , "two" , "skip a few" , "ninety nine" , "one hundred" ) .delayElements(Duration.ofSeconds(1 )) .skip(Duration.ofSeconds(4 )); StepVerifier.create(skipFlux) .expectNext("ninety nine" , "one hundred" ) .verifyComplete(); }
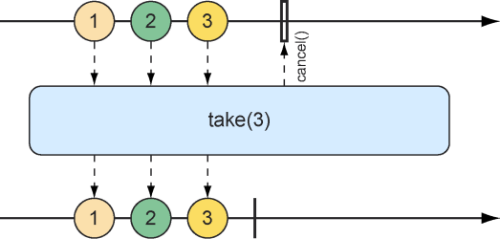
我们已经看过skip操作的示例,根据对skip操作的描述来看,take可以认为是与skip相反的操作。skip操作会跳过前面几个数据项,而take操作只发布第一批指定数量的数据项,然后将取消订阅(如图10.12中的弹珠图所示)。
1 2 3 4 5 6 7 8 9 10 @Test public void take () { Flux<String> nationalParkFlux = Flux.just( "Yellowstone" , "Yosemite" , "Grand Canyon" , "Zion" , "Grand Teton" ) .take(3 ); StepVerifier.create(nationalParkFlux) .expectNext("Yellowstone" , "Yosemite" , "Grand Canyon" ) .verifyComplete(); }
图10.12 take操作只发布传入Flux中前面指定数目的数据项
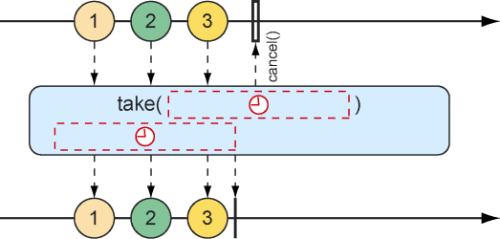
与skip()方法一样,take()方法也有另一种替代形式,基于间隔时间而不是数据项个数。它将接受并发布与源Flux一样多的数据项,直到某段时间结束,之后Flux将会完成,如图10.13所示。
图10.13 take操作的另一种形式(在指定的时间过期之前,一直将消息传递给结果Flux)
下面的测试方法使用take()方法的另一种形式,将会在订阅之后的前3.5秒发布数据条目。
1 2 3 4 5 6 7 8 9 10 11 @Test public void take () { Flux<String> nationalParkFlux = Flux.just( "Yellowstone" , "Yosemite" , "Grand Canyon" , "Zion" , "Grand Teton" ) .delayElements(Duration.ofSeconds(1 )) .take(Duration.ofMillis(3500 )); StepVerifier.create(nationalParkFlux) .expectNext("Yellowstone" , "Yosemite" , "Grand Canyon" ) .verifyComplete(); }
skip操作和take操作都可以被认为是过滤操作,其过滤条件是基于计数或者持续时间的,而Flux值的更通用过滤则是filter操作。
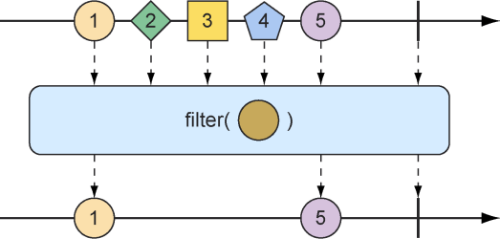
我们需要指定一个Predicate,用于决定数据项是否能通过Flux,filter操作允许我们根据任何条件进行选择性地发布。图10.14中的弹珠图显示了filter操作的工作原理。
图10.14 可以对传入的Flux进行过滤,这样结果Flux将只会发布满足指定Predicate的消息
要查看filter()的实际效果,可以参考下面的测试方法:
1 2 3 4 5 6 7 8 9 10 @Test public void filter () { Flux<String> nationalParkFlux = Flux.just( "Yellowstone" , "Yosemite" , "Grand Canyon" , "Zion" , "Grand Teton" ) .filter(np -> !np.contains(" " )); StepVerifier.create(nationalParkFlux) .expectNext("Yellowstone" , "Yosemite" , "Zion" ) .verifyComplete(); }
这里我们将一个只接受不包含空格的字符串的Predicate作为lambda传给了filter()方法,因此在结果Flux中”Grand Canyon”和”Grand Teton”被过滤掉了。
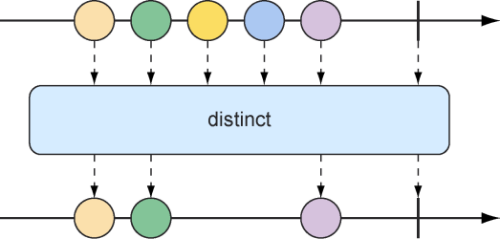
我们还可能想要过滤掉已经接收过的数据条目,可以采用distinct操作(如图10.15所示),形成的Flux将只会发布源Flux中尚未发布过的数据项。
图10.15 distinct操作将会过滤掉重复的消息
在下面的测试中,调用distinct()方法产生的Flux只会发布不同的String值:
1 2 3 4 5 6 7 8 9 @Test public void distinct () { Flux<String> animalFlux = Flux.just( "dog" , "cat" , "bird" , "dog" , "bird" , "anteater" ) .distinct(); StepVerifier.create(animalFlux) .expectNext("dog" , "cat" , "bird" , "anteater" ) .verifyComplete(); }
虽然”dog”和”bird”从源Flux中都发布了两次,但是在调用distinct()方法产生的结果Flux中,它们只被发布了一次。
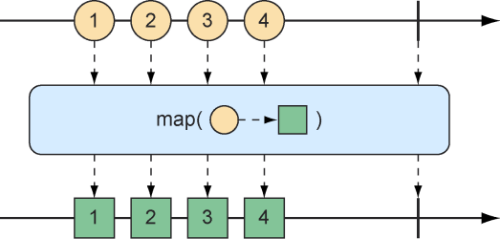
映射反应式数据 在Flux或Mono上最常见的操作之一就是将已发布的数据项转换为其他的形式或类型。Reactor的反应式类型(Flux和Mono)为此提供了map和flatMap操作。
map操作会创建一个新的Flux,只是在重新发布它所接收的每个对象之前会执行给定Function指定的转换。map操作的工作原理如图10.16所示。
图10.16 map操作将传入的消息转换为结果流上的新消息
在下面的test()方法中,包含代表篮球运动员名字的String值的Flux被转换为一个包含Player对象的新Flux。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test public void map () { Flux<Player> playerFlux = Flux .just("Michael Jordan" , "Scottie Pippen" , "Steve Kerr" ) .map(n -> { String[] split = n.split("\\s" ); return new Player (split[0 ], split[1 ]); }); StepVerifier.create(playerFlux) .expectNext(new Player ("Michael" , "Jordan" )) .expectNext(new Player ("Scottie" , "Pippen" )) .expectNext(new Player ("Steve" , "Kerr" )) .verifyComplete(); }
以lambda形式传递给map()方法的函数会将传入的String值按照空格进行拆分,并使用生成的String数组来创建Player对象。使用just()方法创建的Flux包含了String对象,但是map()方法产生的Flux包含了Player对象。
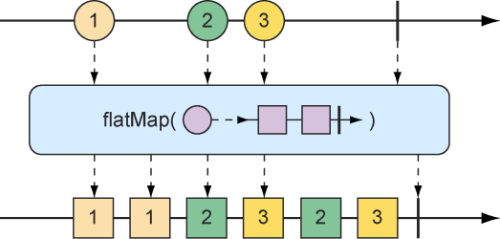
其中重要的一点是:在每个数据项被源Flux发布时,map操作是同步执行的,如果你想要异步地转换过程,那么你应该考虑使用flatMap操作。
对于flatMap操作,我们可能需要一些思考和练习才能完全掌握。如图10.17所示,flatMap并不像map操作那样简单地将一个对象转换到另一个对象,而是将对象转换为新的Mono或Flux。结果形成的Mono或Flux会扁平化为新的Flux。当与subscribeOn()方法结合使用时,flatMap操作可以释放Reactor反应式的异步能力。
图10.17 flatMap操作使用一个中间的Flux来实现异步转换
下面的测试方法展示如何使用flatMap()方法和subscribeOn()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Test public void flatMap () { Flux<Player> playerFlux = Flux .just("Michael Jordan" , "Scottie Pippen" , "Steve Kerr" ) .flatMap(n -> Mono.just(n) .map(p -> { String[] split = p.split("\\s" ); return new Player (split[0 ], split[1 ]); }) .subscribeOn(Schedulers.parallel()) ); List<Player> playerList = Arrays.asList( new Player ("Michael" , "Jordan" ), new Player ("Scottie" , "Pippen" ), new Player ("Steve" , "Kerr" )); StepVerifier.create(playerFlux) .expectNextMatches(p -> playerList.contains(p)) .expectNextMatches(p -> playerList.contains(p)) .expectNextMatches(p -> playerList.contains(p)) .verifyComplete(); }
需要注意的是,我们为flatMap()方法指定了一个lambda形式的函数,传入的String将会转换为一个Mono类型的String,然后在这个Mono上通过map()方法将字符串转换为一个Player。
如果到此为止,那么产生的Flux将同样包含Player对象,与使用map()方法的例子相同,顺序同步地生成。但是我们对Mono做的最后一个动作就是调用subscribeOn()方法,它声明每个订阅都应该在并行线程中进行,因此可以异步并行地执行多个String对象的转换操作。
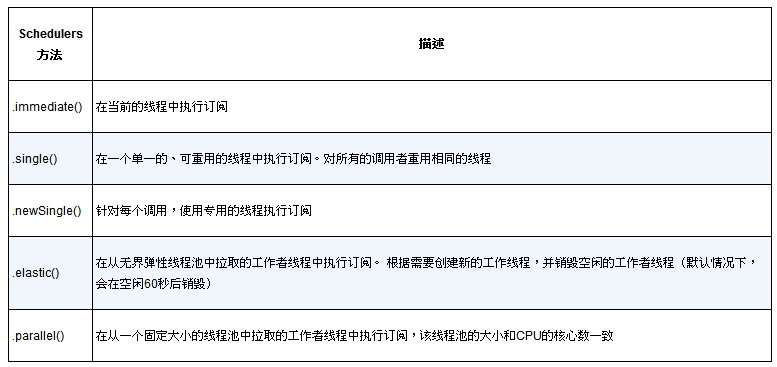
尽管subscribeOn()方法的命名与subscribe()方法类似,但是它们的含义却完全不同。 subscribe()方法是一个动词,订阅并驱动反应式流;而subscribeOn()方法则更具描述性,指定了如何并发地处理订阅。Reactor本身并不强制使用特定的并发模型,通过subscribeOn()方法,我们可以使用Schedulers中的任意一个静态方法来指定并发模型。在这个例子中,我们使用了parallel()方法,使用来自固定线程池(大小与CPU核心数量相同)的工作线程。Schedulers支持多种并发模型,如表10.1所示。
表10.1 Schedulers支持的并发模型
使用flatMap()和subscribeOn()的好处是:我们可以在多个并行线程之间拆分工作,从而增加流的吞吐量。因为工作是并行完成的,无法保证哪项工作首先完成,所以结果Flux中数据项的发布顺序是未知的。因此,StepVerifier只能验证发出的每个数据项是否存在于预期Player对象列表中,并且在Flux完成之前会有3个这样的数据项。
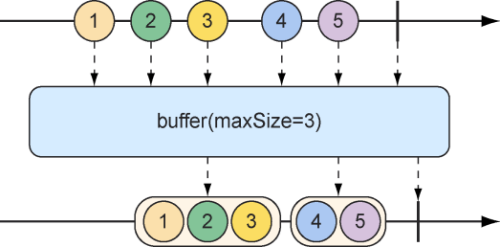
在反应式流上缓存数据 在处理流经Flux的数据时,你可能会发现将数据流拆分为小块会带来一定的收益。如图10.18所示的buffer操作可以帮助你解决这个问题。
图10.18 buffer操作会产生一个新的包含列表Flux(具备最大长度限制的列表,包含从传入的Flux中收集来的数据)
我们给定一个包含多个String值的Flux,其中每个值代表一种水果的名称,我们可以创建一个新的包含List集合的Flux,其中每个List只有不超过指定数量的元素:
1 2 3 4 5 6 7 8 9 10 11 @Test public void buffer () { Flux<String> fruitFlux = Flux.just( "apple" , "orange" , "banana" , "kiwi" , "strawberry" ); Flux<List<String>> bufferedFlux = fruitFlux.buffer(3 ); StepVerifier .create(bufferedFlux) .expectNext(Arrays.asList("apple" , "orange" , "banana" )) .expectNext(Arrays.asList("kiwi" , "strawberry" )) .verifyComplete(); }
在这种情况下,String元素的Flux被缓冲到一个新的包含List集合的Flux中,其中每个集合不超过3个条目。因此,发出5个String值的原始Flux将会被转换为一个新的Flux,它会发出两个List集合,其中一个包含3个水果,而另一个包含2个水果。
这有什么意义呢?将反应式的Flux缓冲到非反应式的Flux中看起来适得其反,但是,当组合使用buffer()方法和flatMap()方法时,我们可以对每个List集合进行并行处理。
1 2 3 4 5 6 7 8 9 Flux.just( "apple" , "orange" , "banana" , "kiwi" , "strawberry" ) .buffer(3 ) .flatMap(x -> Flux.fromIterable(x) .map(y -> y.toUpperCase()) .subscribeOn(Schedulers.parallel()) .log() ).subscribe();
在这个新例子中,我们仍然将5个String值的Flux缓冲到一个新的包含List的Flux中,但是这次将flatMap()应用于包含List集合的Flux。这将获取每个List缓冲区,并为其中的元素创建一个新的Flux,然后对其应用map操作。因此,每个List缓冲区都会在各个线程中执行进一步并行处理。
为了观察实际的效果,在代码中还包括了一个log()操作,它用于每个子Flux。log()操作记录了所有的反应式事件,以便于观察实际发生了什么事情。在日志中将会记录如下的条目(为简洁起见,删除了时间戳的部分):
1 2 3 4 5 6 7 8 9 10 11 12 13 [main] INFO reactor.Flux.SubscribeOn.1 - onSubscribe(FluxSubscribeOn.SubscribeOnSubscriber) [main] INFO reactor.Flux.SubscribeOn.1 - request(32) [main] INFO reactor.Flux.SubscribeOn.2 - onSubscribe(FluxSubscribeOn.SubscribeOnSubscriber) [main] INFO reactor.Flux.SubscribeOn.2 - request(32) [parallel-1] INFO reactor.Flux.SubscribeOn.1 - onNext(APPLE) [parallel-2] INFO reactor.Flux.SubscribeOn.2 - onNext(KIWI) [parallel-1] INFO reactor.Flux.SubscribeOn.1 - onNext(ORANGE) [parallel-2] INFO reactor.Flux.SubscribeOn.2 - onNext(STRAWBERRY) [parallel-1] INFO reactor.Flux.SubscribeOn.1 - onNext(BANANA) [parallel-1] INFO reactor.Flux.SubscribeOn.1 - onComplete() [parallel-2] INFO reactor.Flux.SubscribeOn.2 - onComplete()
如同日志记录所清晰展示的,第一个缓冲区(apple、orange和banana)中的水果在parallel-1线程中处理;与此同时,第二个缓冲区(kiwi和strawberry)中的水果在parallel-2线程中处理。从缓冲区的日志记录交织在一起的事实可以明显地看出,对两个缓冲区的处理是并行执行的。
如果由于某些原因需要将Flux发布的所有数据项都收集到一个List中,那么可以使用不带参数的buffer()方法:
1 Flux<List<String>> bufferedFlux = fruitFlux.buffer();
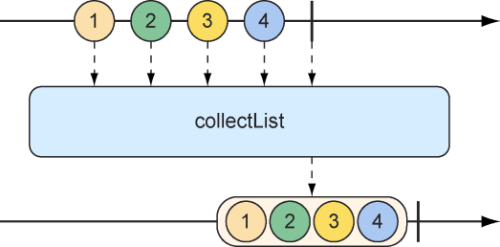
这将会产生一个新的Flux。这个Flux将会发布一个List,其中包含源Flux发布的所有数据项。我们可以使用collectList操作实现相同的功能,如图10.19中的弹珠图所示。
图10.19 collectList操作将产生一个包含传入Flux发布的所有消息的Mono
collectList()方法会产生一个发布List的Mono,而不是发布List的Flux。下面的测试方法展示了它的用法:
1 2 3 4 5 6 7 8 9 10 11 @Test public void collectList () { Flux<String> fruitFlux = Flux.just( "apple" , "orange" , "banana" , "kiwi" , "strawberry" ); Mono<List<String>> fruitListMono = fruitFlux.collectList(); StepVerifier .create(fruitListMono) .expectNext(Arrays.asList( "apple" , "orange" , "banana" , "kiwi" , "strawberry" )) .verifyComplete(); }
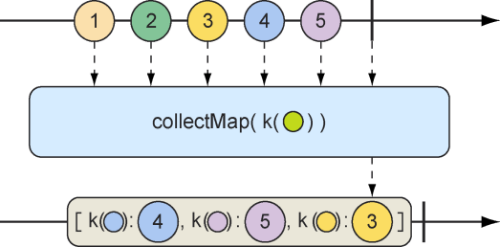
一种更加有趣的收集Flux发出的数据项的方法是将它们收集到Map中。如图10.20所示,collectMap操作将会产生一个发布Map的Mono,这个Map中填充了由给定Function计算key值所生成的条目。
图10.20 collectMap操作将会产生一个Mono(包含了由传入Flux所发出的消息产生的Map,这个Map的key是从传入消息的某些特征衍生而来的)
要查看collectMap()的效果,请参考下面的测试方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Test public void collectMap () { Flux<String> animalFlux = Flux.just( "aardvark" , "elephant" , "koala" , "eagle" , "kangaroo" ); Mono<Map<Character, String>> animalMapMono = animalFlux.collectMap(a -> a.charAt(0 )); StepVerifier .create(animalMapMono) .expectNextMatches(map -> { return map.size() == 3 && map.get('a' ).equals("aardvark" ) && map.get('e' ).equals("eagle" ) && map.get('k' ).equals("kangaroo" ); }) .verifyComplete(); }
源Flux会发布一些动物的名字。基于这个Flux,我们使用collectMap操作创建了一个发布Map的新Mono,其中key由动物名称的首字母确定,而值则为动物名称本身。如果两个动物名称以相同的字母开头(如elephant和eagle,或者koala和kangaroo),那么流经该流的最后一个条目将会覆盖先前的条目。
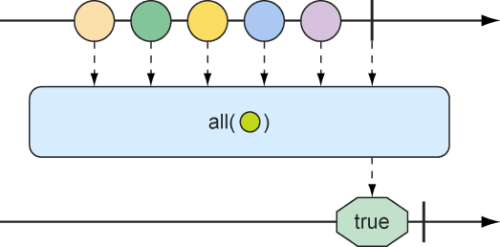
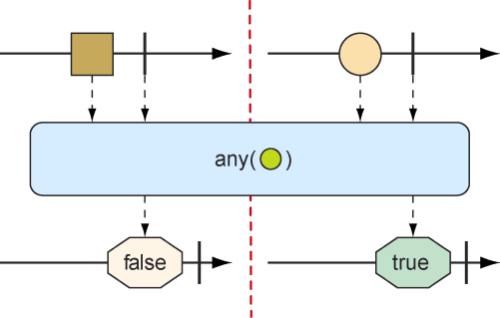
10.3.4 在反应式类型上执行逻辑操作 有时候我们想要知道由Mono或者Flux发布的条目是否满足某些条件,那么all()和any()方法可以实现这样的逻辑。图10.21和图10.22展示了all()和any()的工作方式。
图10.21 可以使用all()方法来确保Flux中的所有消息都满足某些条件
图10.22 可以使用any()方法来确保Flux中至少有一个消息满足某些条件
假设我们想知道Flux发布的每个String中是否都包含了字母a或字母k,那么下面的测试将使用all()方法来检查这个条件:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void all () { Flux<String> animalFlux = Flux.just( "aardvark" , "elephant" , "koala" , "eagle" , "kangaroo" ); Mono<Boolean> hasAMono = animalFlux.all(a -> a.contains("a" )); StepVerifier.create(hasAMono) .expectNext(true ) .verifyComplete(); Mono<Boolean> hasKMono = animalFlux.all(a -> a.contains("k" )); StepVerifier.create(hasKMono) .expectNext(false ) .verifyComplete(); }
在第一个StepVerifier中,我们检查了字母a。all()方法应用于源Flux,会产生布尔类型的Mono。在本例中,所有动物名称都包含了字母a,所以从生成的Mono中会发布true。但是在第二个StepVerifier中,产生的Mono将会发出false,因为并非所有动物名称都包含字母k。
如果至少有一个元素匹配条件即可,而不是要求所有元素均满足条件,那么any()就是我们所需的方法。下面这个新的测试用例使用any()来检查字母t和z:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void any () { Flux<String> animalFlux = Flux.just( "aardvark" , "elephant" , "koala" , "eagle" , "kangaroo" ); Mono<Boolean> hasAMono = animalFlux.any(a -> a.contains("t" )); StepVerifier.create(hasAMono) .expectNext(true ) .verifyComplete(); Mono<Boolean> hasZMono = animalFlux.any(a -> a.contains("z" )); StepVerifier.create(hasZMono) .expectNext(false ) .verifyComplete(); }
在第一个StepVerifier中,我们会看到生成的Mono发布了true,因为至少有一种动物的名称含有字母t(尤其是elephant)。而在第二种情况下,生成的Mono发布了false,因为没有任何一种动物的名称包含字母z。