13.8.2 使用系统表分析数据库信息
13.8.2 使用系统表分析数据库信息
除了可以使用DatabaseMetaData来分析底层数据库信息之外,如果已经确定应用程序所使用的数据库系统,则可以通过数据库的系统表来分析数据库信息。前面已经提到**,系统表又称为数据字典,数据字典的数据通常由数据库系统负责维护,用户通常只能查询数据字典,而不能修改数据字典的内容。
提示
几乎所有的数据库都会提供系统表供用户查询,用户可以通过查询系统表来获得数据库的相关信息。对于像MySQL和SQL Server这样的数据库,它们还提供一个系统数据库来存储这些系统表。系统表相当于视图**,用户只能查看系统表的数据,不能直接修改系统表中的数据.MySQL数据库使用information_schema数据库来保存系统表,在该数据库里包含了大量系统表,常用系统表的简单介绍如下。
| 系统表 | 介绍 |
|---|---|
tables |
存放数据库里所有数据表的信息 |
schemata |
存放数据库里所有数据库(与MySQL的 Schema对应)的信息。 |
views |
存放数据库里所有视图的信息 |
columns |
存放数据库里所有列的信息 |
triggers |
存放数据库里所有触发器的信息 |
routines |
存放数据库里所有存储过程和函数的信息 |
key_column_usage |
存放数据库里所有具有约束的键信息。 |
table_constraints |
存放数据库里全部约束的表信息。 |
statistics |
存放数据库里全部索引的信息。 |
从这些系统表中取得的数据库信息会更加准确,例如,
- 若要查询当前
MySQL数据库中包含多少数据库及其详细信息,则可以查询schemata系统表; - 如果需要查询指定数据库中的全部数据表,则可以查询
tables系统表; - 如果需要查询指定数据表的全部数据列,就可以查询
columns系统表。
下面显示了通过系统表査询所有的数据库、 select_test数据库的全部数据表、 student_table表的所有数据列的SQL语句及执行效果.
1 | mysql> select * from schemata; |
13.8 分析数据库信息
13.8 分析数据库信息
大部分时候,只需要对指定数据表进行插入(C)、查询(R)、修改(U)、删除(D)等CRUD操作;但在某些时候,程序需要动态地获取数据库的相关信息,例如数据库里的数据表信息、列信息。除此之外,如果希望在程序中动态地利用底层数据库所提供的特殊功能,则都需要动态分析数据库相关信息
13.8.1 使用DatabaseMetaData分析数据库信息
JDBC提供了DatabaseMetaData来封装数据库连接对应数据库的信息,通过Connection提供的getMetaData()方法就可以获取数据库对应的DatabaseMetaData对象。DatabaseMetaData接口通常由驱动程序供应商提供实现,其目的是让用户了解底层数据库的相关信息。使用该接口的目的是发现如何处理底层数据库,尤其是对于试图与多个数据库一起使用的应用程序因为应用程序需要在多个数据库之间切换,所以必须利用该接口来找出底层数据库的功能,例如,
- 调用
supportsCorrelatedSubqueries()方法查看是否可以使用关联子查询, - 或者调用
supports BatchUpdates()方法查看是否可以使用批量更新。
许多DatabaseMetaData方法以ResultSet对象的形式返回查询信息,然后使用ResultSet的常规方法(如getString()和getInt())即可从这些ResultSet对象中获取数据。如果查询的信息不可用,则将回一个空ResultSet对象。DatabaseMetaData的很多方法都需要传入一个xxxPattern模式字符串,这里的xxxPattern不是正则表达式,而是SQL里的模式字符串,即:
使用百分号(%)代表任意多个字符,
使用下画线(_)代表一个字符。
在通常情况下,如果把该模式字符串的参数值设置为nul,即表明该参数不作为过滤条件。
实例
下面程序通过DatabaseMetaData分析了当前Connection连接对应数据库的一些基本信息,包括当前数据库包含多少数据表,存储过程, student_table表的数据列、主键、外键等信息.
1 | import java.sql.*; |
上面程序中的粗体字代码就是使用DatabaseMetaData分析数据库信息的示例代码。运行上面程序将可以看到通过DatabaseMetaData分析数据库信息的结果.
13.7.3 Java 8增强的批量更新
13.7.3 Java 8增强的批量更新
JDBC还提供了一个批量更新的功能,使用批量更新时,多条SQL语句将被作为一批操作被同时收集,并同时提交。
提示
批量更新必须得到底层数据库的支持,可以通过调用DatabaseMetaData的supportsBatchUpdates()方法来查看底层数据库是否支持批量更新.
使用批量更新也需要先创建一个Statement对象,然后利用该对象的add Batcho方法将多条SQL语句同时收集起来,最后调用Java 8为Statement对象新增的executeLargeBatch()(或原有的executeBatch())方法同时执行这些SQL语句。只要批量操作中任何一条SQL语句影响的记录条数可能超过Integer.MAX_VALUE,就应该使用executeLargeBatch()方法,而不是executeBatch()方法。
如下代码片段示范了如何执行批量更新。
1 | Statement stmt=conn.createStatement(); |
执行executeLargeBatch()方法将返回一个long数组,因为使用Statement执行DDL、DML语句都将返回一个long值,而执行多条DDL、DML语句将会返回多个long值,多个long值就组成了这个long数组。
如果在批量更新的addBatch()方法中添加了select査询语句,程序将直接出现错误。
编程要点
为了让批量操作可以正确地处理错误,必须把批量执行的操作视为单个事务,如果批量更新在执行过程中失败,则让事务回滚到批量操作开始之前的状态。
为了达到这种效果,程序应该在开始批量操作之前先关闭自动提交,然后开始收集更新语句,当批量操作执行结束后,提交事务,并恢复之前的自动提交模式。如下代码片段所示:
1 | //1.保存当前的自动的提交模式 |
注意MySQL的最新驱动程序依然不支持executeLargeBatch()方法,对于数据库驱动不支持executeLargeBatch()的情形,则只能依然使用传统的executeBatch()方法
13.7.2 JDBC的事务支持
13.7.2 JDBC的事务支持
JDBC连接也提供了事务支持,JDBC连接的事务支持由Connection提供, Connection默认打开自动提交,即关闭事务,在这种情况下,每条SQL语句一旦执行,便会立即提交到数据库,永久生效,无法对其进行回滚操作。
可以调用Connection的setAutoCommit()方法来关闭自动提交,开启事务,如下代码所示:connection.setAutoCommit(false);
程序中还可调用Connection提供的getAutoCommit()方法来返回该连接的自动提交模式。
旦事务开始之后,程序可以像平常一样创建Statement对象,创建了Statement对象之后,可以执行任意多条DML语句,如下代码所示:
1 | statement.executeUpdate(...); |
上面这些SQL语句虽然被执行了,但这些SQL语句所做的修改不会生效,因为事务还没有结束。如果所有的SQL语句都执行成功,程序可以调用Connection的commit()方法来提交事务,如下代码所示:connection.commit();
如果任意一条SQL语句执行失败,则应该用Connection的rollback方法来回滚事务,如下代码所示:connection.rollback();
实际上,当Connection遇到一个未处理的SQLException异常时,系统将会非正常退出,事务也会自动回滚。但如果程序捕获了该异常,则需要在异常处理块中显式地回滚事务.
实例 出现SQLException时,如果不捕获则系统自动回滚
下面程序示范了当程序出现未处理的SQLException异常时,系统将自动回滚事务。
1 | import java.sql.*; |
上面程序中的有开启事务、提交事务的代码,并没有回滚事务的代码。但当程序执行到第4条SQL语句(①处代码)时,这条语句将会引起外键约束异常,由于我们没有捕获处理该异常,所以事务会自动回滚。
Connection对象中间的方法
Connection提供了两个方法来设置中间点。
Savepoint setSavepoint():在当前事务中创建一个未命名的中间点,并返回代表该中间点的Savepoint对象。Savepoint setSavepoint(String name):在当前事务中创建一个具有指定名称的中间点,并返回代表该中间点的Savepoint对象。
通常来说,设置中间点时没有太大的必要指定名称,因为Connection回滚到指定中间点时,并不是根据名字回滚的,而是根据中间点对象回滚的, Connection提供了rollback(Savepoint savepoint)方法回滚到指定中间点。
13.7 事务处理 13.7.1 事务的概念和MySQL事务支持
13.7 事务处理
对于任何数据库应用而言,事务都是非常重要的,事务是保证底层数据完整的重要手段,没有事务支持的数据库应用,那将非常脆弱
13.7.1 事务的概念和MySQL事务支持
事务是由一步或几步数据库操作序列组成的逻辑执行单元,这系列操作要么全部执行,要么全部放弃执行。
程序和事务是两个不同的概念。一般而言,一段程序中可能包含多个事务。
事务的4个特性
事务具备4个特性:
- 原子性(
Atomicity), - 一致性(
Consistency), - 隔离性(
Isolation), - 持续性(
Durability)。
这4个特性也简称为ACID性
原子性
原子性( Atomicity):事务是应用中最小的执行单位,事务是应用中不可再分的最小逻辑执行体。
一致性
一致性( Consistency):事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态。当数据库只包含事务成功提交的结果时,数据库处于一致性状态。如果系统运行发生中断,某个事务尚未完成而被迫中断,而该未完成的事务对数据库所做的修改已被写入数据库此时,数据库就处于一种不正确的状态。比如银行在两个账户之间转账:从A账户向B账户转入1000元,系统先减少A账户的1000元,然后再为B账户增加1000元。如果全部执行成功,数据库处于一致性状态;如果仅减少A账户金额,而没有增加B账户的金额,则数据库就处于不一致性状态;因此,一致性是通过原子性来保证的。
隔离性
隔离性( Isolation):各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务都是隔离的。也就是说,并发执行的事务之间不能看到对方的中间状态,并发执行的事务之间不能互相影响。
持续性
持续性( Durability):持续性也称为持久性( Persistence),指事务一旦提交,对数据所做的任何改变都要记录到永久存储器中,通常就是保存进物理数据库。
事务语句组成
数据库的事务由下列语句组成。
- 一组
DML语句,经过这组DML语句修改后的数据将保持较好的一致性。(DML指的是:insert,update,delete这三条SQL语句) - 一条
DDL语句。(DDL指的是create,alter,drop,truncate等语句) - 一条
DCL语句。(DCL指的是:grant等语句)
注意
事务中的DDL和DCL语句最多只能有一条,因为DDL和DCL语句都会导致事务立即提交。
提交
当事务所包含的全部数据库操作都成功执行后,应该提交( commit)事务,使这些修改永久生效。
事务提交有两种方式:显式提交和自动提交。
- 显式提交:使用
commit时. - 自动提交:执行
DDL或DCL语句,或者程序正常退出时。
回滚
当事务所包含的任意一个数据库操作执行失败后,应该回滚(rollback)事务,使该事务中所做的修改全部失效。事务回滚有两种方式:显式回滚和自动回滚。
- 显式回滚:使用
rollback。 - 自动回滚:系统错误或者强行退出。
如何开启 关闭事务
MySQL默认关闭事务(即打开自动提交),在默认情况下,用户在MySQL控制台输入一条DML语句,这条DML语句将会立即保存到数据库里。为了开启MySQL的事务支持,可以显式调用如下命令:
1 | SET AUTOCOMMIT={0|1} #0为关闭自动提交,即开启事务 |
注意:自动提交和开启事务恰好相反,如果开启自动提交就是关闭事务;关闭自动提交就是开启事务。
临时开启事务
除此之外,如果不想关闭整个命令行窗口的自动提交,而只是想临时性地开始事务,则可以使用MySQL提供的start transaction或begin两个命令,它们都表示临时性地开始一次事务,处于starttransaction或begin后的DML语句不会立即生效,除非使用commit显式提交事务,或者执行DDL、DCL语者来隐式提交事务。如下SQL代码将不会对数据库有任何影响。
1 | begin; |
执行上面SQL语句中的第①条查询语句将会看到刚刚插入的3条记录,如果打开MySQL的其他命令行窗口将看不到这3条记录—这正体现了事务的隔离性。
接着程序rollback了事务中的全部修改,执行第②条查询语句时将看到数据库又恢复到事务开始前的状态。
对于提交,不管是显式提交还是隐式提交,都会结束当前事务;
对于回滚,不管是显式回滚还是隐式回滚,都会结束当前事务。
保存点
除此之外, MySQL还提供了savepoint来设置事务的中间点,通过使用savepoint设置事务的中间点可以让事务回滚到指定中间点,而不是回滚全部事务。如下SQL语句设置了一个中间点:
1 | savepoint a; |
一旦设置了中间点后,就可以使用rollback回滚到指定中间点,回滚到指定中间点的代码如下:
1 | rollback to a; |
注意:
普通的提交、回滚都会结束当前事务,
但回滚到指定中间点因为依然处于事务之中,所以不会结束当前事务.
13.6.3 离线RowSe的查询分页
13.6.3 离线RowSet的查询分页
由于CachedRowSet会将数据记录直接装载到内存中,因此如果SQL查询返回的记录过大CachedRowSet将会占用大量的内存,在某些极端的情况下,它甚至会直接导致内存溢出。
为了解决该问题, CachedRowSet提供了分页功能。所谓分页功能就是一次只装载Resultset里的某几条记录,这样就可以避免CachedRowSet占用内存过大的问题。CachedSet提供了如下方法来控制分页。
| 方法 | 描述 |
|---|---|
populate(Resultset rs, int startRow) |
使用给定的Resultset装填RowSet,从Resultset的第startRow条记录开始装填。 |
setPageSize(int pageSize) |
设置CachedRowSet每次返回多少条记录。 |
previousPage() |
在底层Resultset可用的情况下,让CachedSet读取上一页记录。 |
nextPage() |
在底层Resultset可用的情况下,让CachedRowSet读取下一页记录。 |
下面程序示范了CachedRowSet的分页支持。
1 | import java.util.*; |
CachedRowSet实现分页的关键代码如下:
1 | // 设置每页显示pageSize条记录 |
程序中①号代码显示要査询第2页的记录,每页显示3条记录。运行上面程序,可以看到程序只会显示从第4行到第6行的记录,这就实现了分页。
13.6.2 离线RowSet
13.6.2 离线RowSet
在使用ResultSet的时代,程序查询得到ResultSet之后必须立即读取或处理它对应的记录,否则旦Connection关闭,再去通过ResultSet读取记录就会引发异常。在这种模式下,JDBC编程十分痛苦.
假设应用程序架构被分为两层:数据访问层和视图显示层,当应用程序在数据访问层查询得到ResultSet之后,对ResultSet的处理有如下两种常见方式。
1.使用迭代访问
ResultSet里的记录,并将这些记录转换成Java Bean,再将多个Java Bean封装成个List集合,也就是完成”ResultSet到Java Bean集合”的转换。转换完成后可以关闭Connection等资源,然后将Java bean集合传到视图显示层,视图显示层可以显示查询得到的数据。2.直接将
ResultSet传到视图显示层——这要求当视图显示层显示数据时,底层Connection必须直处于打开状态,否则ResultSet无法读取记录。第一种方式比较安全,但编程十分烦琐;
第二种方式则需要
Connection一直处于打开状态,这不仅不安全,而且对程序性能也有较大的影响。
通过使用离线RowSet可以十分”优雅”地处理上面的问题,离线RowSet会直接将底层数据读入内存中,封装成RowSet对象,而RowSet对象则完全可以当成Java Bean来使用。因此不仅安全,而且编程十分简单。CachedRowSet是所有离线RowSet的父接口,因此下面以CachedRowSet为例进行介绍。看下面程序。
1 | import java.util.*; |
上面程序中的①号代码调用了RowSet的populate(ResultSet rs)方法来包装给定的ResultSet,接下来的粗体字代码关闭了ResultSet、 Statement、 Connection等数据库资源。如果程序直接返回ResultSet,那么这个ResultSet无法使用:这是因为底层的Connection已经关闭了;但程序返回的是CachedRowSet,它是一个离线RowSet,因此程序依然可以读取、修改RowSet中的记录。
运行该程序,可以看到在Connection关闭的情况下,程序依然可以读取、修改RowSet里的记录.
为了将程序对离线RowSet所做的修改同步到底层数据库,程序在调用RowSet的acceptChanges()方法时必须传入Connection.
13.6 Java7的RowSet1.1 13.6.1 Java 7新增的RowSetFactory与RowSet
13.6 Java7的RowSet1.1
RowSet接口继承了ResultSet接口, RowSet接口下包含JdbcRowSet、 CachedRowSet、 FilteredRowSet、JoinRowset和WebRowSet常用子接口。除了JdbcRowSet需要保持与数据库的连接之外,其余4个子接口都是离线的RowSet,无须保持与数据库的连接。
与ResultSet相比, RowSet默认是可滚动、可更新、可序列化的结果集,而且作为JavaBean使用,因此能方便地在网络上传输,用于同步两端的数据。对于离线RowSet而言,程序在创建RowSet时已把数据从底层数据库读取到了内存,因此可以充分利用计算机的内存,从而降低数据库服务器的负载,提高程序性能。
图13.22显示了RowSet规范的接口类图。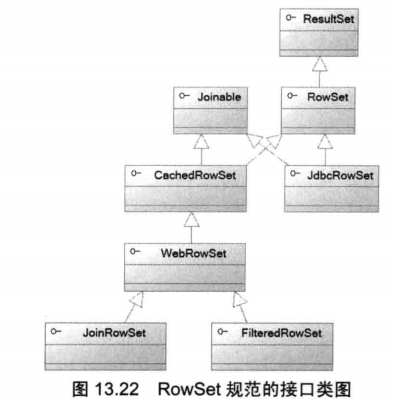
CachedRowSet及其子接口都代表了离线RowSet,它们都不需要底层数据库连接。
13.6.1 Java 7新增的RowSetFactory与RowSet
在Java 6.0以前, RowSet及其5个子接口都已经存在了,但在实际编程中的应用一直并不广泛,这是因为Java公开API并没有为RowSet及其各子接口提供实现类,而且也没有提供公开的方法来创建RowSet及其各子接口的实例。
实际上,Java6.0已经在com.sun.rowset包下提供了JdbcRowSetlmpl、 CachedRowSetlmpl、WebRowSetlmpl、 FilteredRowSetlmpl和JoinRowSetlmpl五个实现类,它们代表了各种RowSet接口的实现类
以JdbcRowSet为例,在Java 6.0及以前的版本中,如果程序需要使用JdbcRowSet,则必须通过调用JdbcRowSetlmpl的构造器来创建JdbcRowSet实例, JdbcRowSetlmpl提供了如下常用构造器.
| 方法 | 描述 |
|---|---|
JdbcRowSetlmpl() |
创建一个默认的JdbcRowSetlmpl对象。 |
JdbcRowSetImpl(Connection conn) |
以给定的Connection对象作为数据库连接来创建JdbcRowSetlmpl对象。 |
JdbcRowSetlmpl(ResultSet rs) |
创建包装ResultSet对象的JdbcRowSetlmpl对象. |
除此之外, RowSet接口中定义了如下常用方法。
| 方法 | 描述 |
|---|---|
setUrl(String ur) |
设置该 RowSet要访问的数据库的URL |
setUsername(String name) |
设置该RowSet要访问的数据库的用户名。 |
setPassword(String password) |
设置该RowSet要访问的数据库的密码。 |
setCommand(String sql) |
设置使用该sql语句的查询结果来装填该RowSet。 |
execute() |
执行查询 |
populate(ResultSet rs) |
让该RowSet直接包装给定的 ResultSet对象. |
通过JdbcRowSet的构造器和上面几个方法不难看出,为JdbcRowSet装填数据有如下两种方式。 |
- 1.创建
JdbcRowSetlmpl时,直接传入ResultSet对象。 - 2.使用
execute()方法来执行SQL査询,用查询返回的数据来装填RowSet.
对于第二种方式来说,如果创建JdbcRowSetlmpl时已经传入了Connection参数,则只要先调用setCommand(String sql)指定SQL查询语句,接下来就可调用execute()方法执行查询了。如果创建JdbcRowSetlmpl时没有传入Connection参数,则先要为JdbcRowSet设置数据库的URL、用户名、密码等连接信息
下面程序通过JdbcRowSetlmpl示范了使用JdbcRowSet的可滚动、可修改特性.
1 | import java.util.*; |
上面程序中①号代码创建一个JdbcRowSetlmpl实例,这就是一个JdbcRowSet对象。接下来的代码则示范了JdbcSet的可滚动、可修改的特性。
编译该程序,编译器将会在①号代码处发出警告: JdbcRowSetlmpl是内部专用AP,可能会在未来发行版中删除。这就是直接使用JdbcRowSetImpl的代价.
需要说明的是,使用JdbcRowSetlmpl除了编译器会发出警告之外,还有如下坏处。
- 程序直接与
JdbcRowSetlmpl实现类耦合,不利于后期的升级、扩展。 JdbcRowSetlmpl实现类不是一个公开的API,未来可能被删除。
正是因为上面两个原因,所以在Java 6.0时代, RowSet并未得到广泛应用。Java 7新增了RowSetProvider类和Row SetFactory接口,其中RowSetProvider负责创建RowSetFactory,而RowSetFactory则提供了如下方法来创建RowSet实例。
| 方法 | 描述 |
|---|---|
CachedRowSet createCachedRowSet() |
创建一个默认的CachedRowSet |
FilteredRowSet createFilteredRowSet() |
创建一个默认的FilteredRowSet |
JdbcRowSet createJdbcRowSet() |
创建一个默认的JdbcRowSet |
JoinRowSet createJoinRowSet() |
创建一个默认的JoinRowSet |
WebRowSet createWebRowSet() |
创建一个默认的WebRowSet |
通过使用RowSetFactory,就可以把应用程序与RowSet实现类分离开,避免直接使用JdbcRowSetlmpl等非公开的API,也更有利于后期的升级、扩展。
下面程序使用RowSetFactory来创建JdbcRowSet实例。
1 | import java.util.*; |
上面程序中使用了RowSetFactory来创建JdbcRowSet对象,这就避免了与JabcRowSetlmpl实现类耦合。由于通过这种方式创建的JdbcRowSet还没有传入Connection参数,因此程序还需调用setUrl()、 setUsername()、 setPassword()等方法来设置数据库连接信息编译、运行该程序,编译器不会发出任何警告,程序运行结果也一切正常。
13.5.3 使用ResultsetMetaData分析结果集
13.5.3 使用ResultSetMetaData分析结果集
当执行SQL査询后可以通过移动记录指针来遍历ResultSet的每条记录,但程序可能不清楚该ResultSet里包含哪些数据列,以及每个数据列的数据类型,那么可以通过ResultSetMetaData来获取关于ResultSet的描述信息。MetaData的意思是元数据,即描述其他数据的数据,因此ResultSetMetaData封装了描述ResultSet对象的数据;后面还要介绍的Database Meta Data则封装了描述Database的数据ResultSet里包含一个getMetaData()方法,该方法返回该ResultSet对应的ResultSetMetaData对象旦获得了ResultSetMetaData对象,就可通过ResultSetMetaData提供的大量方法来返回ResultSet的描述信息。常用的方法有如下三个。
int getColumnCount():返回该ResultSet的列数量。String getColumnName(int column):返回指定索引的列名。int getType(int column):返回指定索引的列类型。
下面是一个简单的查询执行器,当用户在文本框内输入合法的查询语句并执行成功后,下面的表格将会显示查询结果。
1 | import java.awt.*; |
在上面的程序中使用ResultSetMetaData查询ResultSet包含多少列,并把所有数据列的列名添加到一个Vector里,然后把ResultSet里的所有数据添加到另一个Vector里,并使用这两个Vector来创建新的TableModel,再利用该TableMode生成一个新的JTable,最后将该JTable显示出来。
运行上面程序,在文本框中输入select * from student_table然后点击查询,会看到如图13.21所示的窗口。
注意:
虽然ResultSetMetaData可以准确地分析出ResultSet里包含多少列,以及每列的列名、数据类型等,但使用ResultSetMetaData需要一定的系统开销,因此如果在编程过程中已经知道ResultSet里包含多少列,以及每列的列名、类型等信息,就没有必要使用ResultSetMetaData来分析该ResultSet对象了。