8.4.2 使用AspectJ实现AOP AspectJ是一个基于Java语言的AOP框架,提供了强大的AOP功能,其他很多AOP框架都借鉴或采纳其中的一些思想。由于Spring的AOP与AspectJ进行了很好的集成,因此掌握AspectJ是学习Spring AOP的基础。AspectJ是Java语言的一个AOP实现,其主要包括两个部分:
一个部分定义了如何表达、定义AOP编程中的语法规范,通过这套语法规范,可以方便地用AOP来解决Java语言中存在的交叉关注点的问题;
另一个部分是工具部分,包括编译器、调试工具等。
AspectJ是最早的、功能比较强大的AOP实现之一,对整套AOP机制都有较好的实现,很多其他语言的AOP实现,也借鉴或采纳了AspectJ中的很多设计。在Java领域, AspectJ中的很多语法结构基本上已成为AOP领域的标准。Spring2.0开始, Spring AOP已经引入了对AspectJ的支持,并允许直接使用AspectJ进行AOP编程,而Spring自身的AOP API也努力与Aspect保持一致。因此,学习Spring AOP就必然需要从AspectJ开始,因为它是Jawa领域最流行的AOP解决方案。即使不用Spring框架,也可以直接使用AspectJ进行AOP编程。AspectJ是Eclipse下面的一个开源子项目,其最新的1.9.0RC2版本(1.9系列才支持Java9)于2017年11月9日发布,这也是本书所使用的Aspect版本。
1. 下载和安装AspectJ 下载和安装AspectJ请按如下步骤进行。
如何下载AspectJ
登录AspectJ站点 ,下载Aspect的最新版本1.9.x,本书下载AspectJ1.9.0.RC2版本。
下载完成后得到一个aspectj-1.9.0.RC2.jar文件,该文件名中的1.9.0表示AspectJ的版本号。
如何安装AspectJ
启动命令行窗口,进入aspectj-19.0.RC2.jar文件所在的路径,输入命令: java -jar aspectj-19.0.RC2.jar,将看到如图8.5所示的对话框。
单击"Next"按钮,系统将出现如图8.6所示的对话框,该对话框用于选择JDK安装路径.、
如果JDK安装路径正确,则直接单击"Next"按钮;否则应该通过右边的"Browse"按钮来选择JDK安装路径。正确选择了JDK安装路径后单击"Next"按钮,系统将出现如图8.7所示的对话框,该对话框用于选择AspectJ的安装路径。
选择了合适的安装路径后,单击"Install"按钮,程序开始安装AspectJ,安装结束后出现一个对话框,单击该对话框中的"Next"按钮,将弹出安装完成对话框,如图8.8所示。
正如图8.8中所提示的,安装了AspectJ之后,系统还应该将AspectJ安装目录下的bin路径添加到PATH环境变量中,将AspectJ安装目录下的lib目录下的aspectjrt.jar添加到CLASSPATH环境变量中。
Aspect提供了编译、运行Aspect的一些工具命令,这些工具命令放在AspectJ的bin路径下,而lib路径下的aspectjrt.jar则是Aspect.的运行时环境,所以需要分别添加这两个环境变量——就像安装了JDK也需要添加环境变量一样.
AspectJ是纯绿色软件 本书没有将Aspect安装在C盘,这是因为AspectJ是”纯绿色”软件,安装Aspect的实质是解压缩了一个压缩包,并不需要向Windows注册表、系统路径里添加任何”垃圾”信息,因此保留Aspect安装后的文件夹,即使以后重装Windows系统, AspectJ也不会受到任何影响。
2. AspectJ使用入门 成功安装了AspectJ之后,将会在AspectJ的安装路径中看到如下文件结构。
bin:该路径下存放了aj、aj5、ajc、 ajdoc、 ajbrowser等命令,其中ajc命令最常用,它的作用类似于Javac,用于对普通的Java类进行编译时增强docs:该路径下存放了AspectJ的使用说明、参考手册、API文档等文档。lib:该路径下的4个JAR文件是AspectJ的核心类库。相关授权文件。
虽然AspectJ是Eclipse基金组织的开源项目,而且提供了Eclipse的ADT插件( Aspect Development Tools)来开发AspectJ应用,但AspectJ并不依赖于Eclipse工具。AspectJ的用法非常简单,就像使用JDK编译、运行Java程序一样。
程序示例 1 2 3 4 5 6 7 G:\Desktop \随书源码\轻量级Java EE 企业应用实战(第5版)\codes \08\8.4\AspectJQs ├─AspectJTest.java ├─AuthAspect.java ├─Hello.java ├─LogAspect.java ├─TxAspect.java └─World.java
下面通过一个简单的程序来示范AspectJ的用法。
Hello.java 首先编写两个简单的Java类,这两个Java类用于模拟系统中的业务组件,实际上无论多少个类,AspectJ的处理方式都是一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package org.crazyit.app.service;public class Hello { public void deleteUser (Integer id) { System.out.println("执行Hello组件的deleteUser删除用户:" + id); } public int addUser (String name , String pass) { System.out.println("执行Hello组件的addUser添加用户:" + name); return 20 ; } }
World.java 另一个World组件类如下。
1 2 3 4 5 6 7 8 9 10 package org.crazyit.app.service;public class World { public void bar () { System.out.println("执行World组件的bar()方法" ); } }
上面两个业务组件类总共定义了三个方法,用于模拟系统所包含的三个业务逻辑方法,实际上无论多少个方法, AspectJ的处理方式都是一样的。
AspectJTest.java 下面使用一个主程序来模拟系统调用两个业务组件的三个业务方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package lee;import org.crazyit.app.service.Hello;import org.crazyit.app.service.World;public class AspectJTest { public static void main (String[] args) { Hello hello = new Hello (); hello.addUser("孙悟空" , "7788" ); hello.deleteUser(1 ); World world = new World (); world.bar(); } }
使用最原始的javac.exe命令来编译这三个源程序:
1 2 3 G:\Desktop \随书源码\轻量级Java EE 企业应用实战(第5版)\codes \08\8.4\AspectJQs >javac -d . Hello.java G :\Desktop \随书源码\轻量级Java EE 企业应用实战(第5版)\codes \08\8.4\AspectJQs >javac -d . World.java G :\Desktop \随书源码\轻量级Java EE 企业应用实战(第5版)\codes \08\8.4\AspectJQs >javac -d . AspectJTest.java
然后使用java.exe命令来执行AspectJTest类,程序输出如下:
1 2 3 4 G:\Desktop \随书源码\轻量级Java EE 企业应用实战(第5版)\codes \08\8.4\AspectJQs >java lee.AspectJTest 执行Hello 组件的addUser 添加用户:孙悟空 执行Hello 组件的deleteUser 删除用户:1 执行World 组件的bar ()方法
假设现在客户要求在执行所有业务方法之前先执行权限检査,如果使用传统的编程方式,开发者必须先定义一个权限检査的方法,然后由此打开每个业务方法,并修改业务方法的源代码,增加调用权限检查的方法—但这种方式需要对所有业务组件中的每个业务方法都进行修改,因此不仅容易引入新的错误,而且维护成本相当大。
AuthAspect.java 如果使用AspectJ的AOP支持,则只要添加如下特殊的"Java类"即可:
1 2 3 4 5 6 7 8 9 10 11 12 package org.crazyit.app.aspect;public aspect AuthAspect{ before(): execution(* org.crazyit.app.service.*.*(..)) { System.out.println("模拟进行权限检查..." ); } }
可能读者已经发现了,上面的类文件中不是使用class、 interface、enum定义Java类,而是使用了aspect难道Java又新增了关键字?没有!上面的AuthAspect根本不是一个Java类,所以aspect也不是Java支持的关键字,它只是AspectJ才能识别的关键字。AspectJ将会自动先调用该代码块中的代码。Java无法识别AuthAspect.java文件的内容,所以要使用ajc.bat命令来编译上面的Java程序.
可以把ajc.bat理解成增强版的javac.exe命令,都用于编译Java程序,区别是ajc.bat命令可识别AspectJ的语法。
由于ajc命令默认兼容JDK1.4源代码,因此它默认不支持自动装箱、自动拆箱等功能。所以上面使用该命令时指定了-1.8选项,表明让ajc命令兼容JDK1.8。AspectJTest类依然无须任何改变,还是使用如下命令运行AspectJTest类:
运行该程序,将看到一个令人惊喜的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 G:\Desktop \Test \AspectJQs >mytree f G :\Desktop \Test \AspectJQs ├─AspectJTest.java ├─AuthAspect.java ├─Hello.java └─World.java G :\Desktop \Test \AspectJQs >ajc -1.8 -d . *.java G :\Desktop \Test \AspectJQs >java lee.AspectJTest 模拟进行权限检查... 执行Hello 组件的addUser 添加用户:孙悟空 模拟进行权限检查... 执行Hello 组件的deleteUser 删除用户:1 模拟进行权限检查... 执行World 组件的bar ()方法
从上面的运行结果来看,完全不需要对Hello.java、 World.java等业务组件进行任何修改,但同时又可以满足客户的需求—上面的程序只是在控制台打印了"模拟进行权限检査"这个字符串来模拟权限检查,实际上也可用实际的权限检查代码来代替这行简单的语句,这就可以满足客户需求了。
LogAspect.java 如果客户再次提出新需求,比如需要在执行所有的业务方法之后增加记录日志的功能,那也很简单,只要再定义一个LogAspect,程序如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 package org.crazyit.app.aspect;public aspect LogAspect{ pointcut logPointcut () :execution(* org.crazyit.app.service.*.*(..)); after():logPointcut() { System.out.println("模拟记录日志..." ); } }
上面程序中的粗体字代码定义了一个pointcut logPointcut(),这种用法就是为后面的切入点表达式起个名字,方便后面复用这个切入点表达式—假如程序中有多个代码块需要使用该切入点表达式,这些代码块都可直接复用此处定义的logPointcut,,而不是重复书写烦琐的切入点表达式。Java程序:
再次运行lee.AspectJTest类,将看到如下运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 G:\Desktop \Test \AspectJQs >ajc -1.8 -d . *.java G :\Desktop \Test \AspectJQs >java lee.AspectJTest 模拟进行权限检查... 执行Hello 组件的addUser 添加用户:孙悟空 模拟记录日志... 模拟进行权限检查... 执行Hello 组件的deleteUser 删除用户:1 模拟记录日志... 模拟进行权限检查... 执行World 组件的bar ()方法 模拟记录日志...
TxAspect.java 假如现在需要在业务组件的所有业务方法之前启动事务,并在方法执行结束时关闭事务,同样只要定义如下TXAspect即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package org.crazyit.app.aspect;public aspect TxAspect{ Object around () :call(* org.crazyit.app.service.*.*(..)) { System.out.println("== 模拟开启事务..." ); Object rvt = proceed(); System.out.println("== 模拟结束事务..." ); return rvt; } }
上面的代码:Object rvt = proceed();指定proceed代表回调原来的目标方法,这样位于proceed代码之前的代码就会被添加在目标方法之前,位于proceed代码之后的代码就会被添加在目标方法之后。
如果再次使用ajc.bat命令来编译上面所有的Java类,并执行lee.AspectJTest,此时将会发现系统中两个业务组件所包含的业务方法已经变得”十分强大”了,但并未修改过Hello.java、 World.java的源代码
AspectJ的作用 这就是**AspectJ的作用:开发者无须修改源代码,但又可以为这些组件的方法添加新的功能。**
AspectJ在编译时增强类的功能 如果读者安装过Java的反编译工具,则可以反编译前面程序生成的Hello.class、 World.class文件,将发现该Hello.class、 World.class文件不是由Hello.java、 World.java文件编译得到的,Hello.class,World.class里新增了很多内容,这表明AspectJ在编译时已增强了Hello.class, World.class类的功能,因此AspectJ通常被称为编译时增强的AOP框架。
AOP达到的效果 AOP要达到的效果是,保证在程序员不修改源代码的前提下,为系统中业务组件的多个业务方法添加某种通用功能 。但AOP的实际上依然要去修改业务组件的多个业务方法的源代码,只不过是这个修改由AOP框架完成的,不需要程序员手动修改。
AOP实现分类 AOP实现按AOP框架修改源代码的时机可分为两类:
静态AOP实现:AOP框架在编译阶段对程序进行修改,即实现对目标类的增强,生成静态的AOP代理类(生成的*.class文件已经被改掉了,需要使用特定的编译器)。这以AspectJ为代表。
动态AOP实现:AOP框架在运行阶段动态生成AOP代理(在内存中以JDK动态代理或cglib动态地生成AOP代理类),以实现对目标对象的增强。这以Spring AOP为代表。
静态AOP性能好需要编译器 一般来说,静态AOP实现具有较好的性能,但需要使用特殊的编译器。动态AOP实现是纯Java实现,因此无须特殊的编译器,但是通常性能略差。
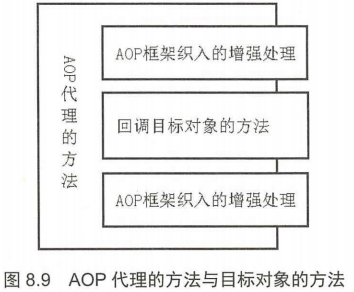
Spring AOP Spring AOP就是动态AOP实现的代表, Spring AOP不需要在编译时对目标类进行增强,而是在运行时生成目标类的代理类,该代理类要么与目标类实现相同的接口,要么作为目标类的子类,总之,代理类都对目标类进行了增强处理
实现相同的接口方式是JDK动态代理的处理策略,作为目标类的子类是cglib代理的处理策略。
一般来说,编译时增强的AOP框架在性能上更有优势,因为运行时动态增强的AOP框架需要每次运行时都进行动态增强。
可能有读者对AspectJ更深入的知识感兴趣,但本书的重点并不是介绍AspectJ,因此如果读者希望掌握如何定义AspectJ中的Aspect、 Pointcut等内容,可参考AspectJ安装路径下的doc目录里的quick5.pdf文件。