8.6.2 使用XML Schema配置事务策略
8.6.2 使用XML Schema配置事务策略
Spring同时支持编程式事务策略和声明式事务策略,通常都推荐采用声明式事务策略。使用声明式事务策略的优势十分明显。
- 声明式事务能大大降低开发者的代码书写量,而且声明式事务几乎不影响应用的代码。因此,无论底层事务策略如何变化,应用程序都无须任何改变。
- 应用程序代码无须任何事务处理代码,可以更专注于业务逻辑的实现
Spring则可对任何POJO的方法提供事务管理,而且Spring的声明式事务管理无须容器的支持,可在任何环境下使用。EJB的CMT无法提供声明式回滚规则;而通过配置文件,Spring可指定事务在遇到特定异常时自动回滚。Spring不仅可以在代码中使用setRollbackOnly回滚事务,也可以在配置文件中配置回滚规则。- 由于
Spring采用AOP的方式管理事务,因此,可以在事务回滚动作中插入用户自己的动作,而不仅仅是执行系统默认的回滚。
本节不打算全面介绍Spring的各种事务策略,因此这里不会介绍编程式事务。如果读者需要更全面地了解Spring事务的相关方面,请自行参阅Spring官方参考手册。Spring的XML Schema方式提供了简洁的事务配置策略, Spring提供了tx:命名空间来配置事务管理。**tx:命名空间下提供了<tx:advice>元素来配置事务增强处理,一旦使用该元素配置了事务增强处理,就可直接使用<aop:advisor>元素启用自动代理了**。
配置<tx:advice>元素时除了需要transaction-manager属性指定事务管理器之外,还需要配置一个<attributes>子元素,该子元素里又可包含多个<method>子元素。<tx:advice>元素的属性、子元素的关系如图8.19所示。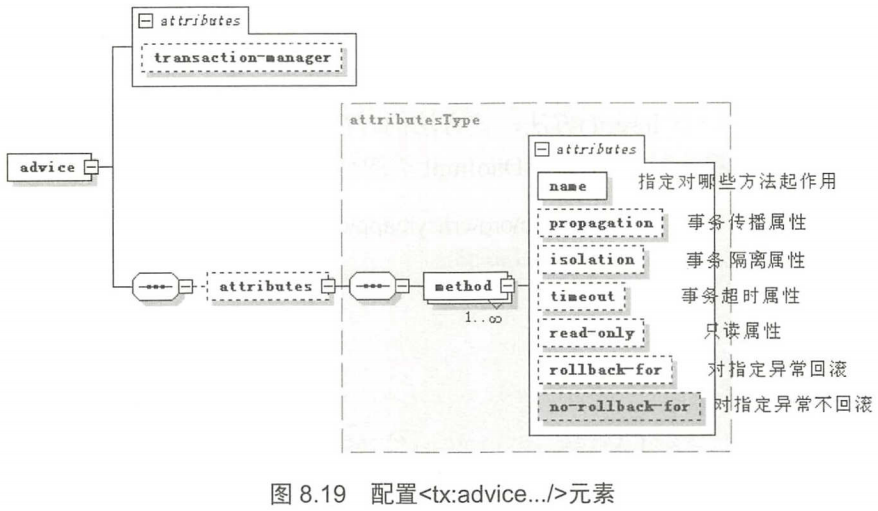
从图8.19可以看出,配置<tx:advice>元素的重点就是配置<method>子元素,实际上每个<method>子元素都为一批方法指定了所需的事务定义,包括事务传播属性、事务隔离属性、事务超时属性、只读事务、对指定异常回滚、对指定异常不回滚等。
method元素
如图8.19所示,配置<method>子元素可以指定如下几个属性:
| 属性 | 描述 |
|---|---|
name |
必选属性,与该事务语义关联的方法名。该属性支持使用通配符,例如get*、"handle*、on*Event等 |
propagation |
指定事务传播行为,该属性值可为Propagation枚举类的任一枚举值,各枚举值的含义下面立即介绍。该属性的默认值为Propagation.REQUIRED。 |
isolation |
指定事务隔离级别,该属性值可为Isolation枚举类的任一枚举值,各枚举值的具体含义可参考API文档。该属性的默认值为Isolation.DEFAULT。 |
timeout |
指定事务超时的时间(以秒为单位),指定-1意味着不超时,该属性的默认值是-1 |
read-only |
指定事务是否只读。该属性的默认值是false |
rollback-for |
指定触发事务回滚的异常类(应使用全限定类名),该属性可指定多个异常类,多个异常类之间以英文逗号隔开。 |
no-rollback-for |
指定不触发事务回滚的异常类(应使用全限定类名),该属性可指定多个异常类,多个异常类之间以英文逗号隔开。 |
method元素的propagation属性值
<method>子元素的propagation属性用于指定事务传播行为, Spring支持的事务传播行为如下。
propagation属性值 |
描述 |
|---|---|
PROPAGATION_MANDATORY |
要求调用该方法的线程必须处于事务环境中,否则抛出异常。 |
PROPAGATION_NESTED |
即使执行该方法的线程已处于事务环境中,也依然启动新的事务,方法在嵌套的事务里执行;即使执行该方法的线程并未处于事务环境中,也启动新的事务,然后执行该方法,此时与PROPAGATION_REQUIRED相同。 |
PROPAGATION_NEVER |
不允许调用该方法的线程处于事务环境中,如果调用该方法的线程处于事务环境中,则抛出异常。 |
PROPAGATION_NOT_SUPPORTED |
如果调用该方法的线程处于事务环境中,则先暂停当前事务,然后执行该方法。 |
PROPAGATION_REQUIRED |
要求在事务环境中执行该方法,如果当前执行线程已处于事务环境中,则直接调用;如果当前执行线程不处于事务环境中,则启动新的事务后执行该方法。 |
PROPAGATION_REQUIRES_NEW |
该方法要求在新的事务环境中执行,如果当前执行线程已处于事务环境中,则先暂停当前事务,启动新事务后执行该方法;如果当前调用线程不处于事务环境中,则启动新的事务后执行方法。 |
PROPAGATION_SUPPORTS |
如果当前执行线程处于事务环境中,则使用当前事务,否则不使用事务。 |
程序示例
本示例使用NewsDaoImpl组件来测试Spring的事务功能,程序将使用<tx:advice>元素来配置事务增强处理,再使用<aop:advisor>为容器中的一批Bean配置自动事务代理。
NewsDaoImpl.java
NewsDaoImpl组件包含一个insert()方法,该方法同时插入两条记录,但插入的第二条记录将会违反唯一键约束,从而引发异常。下面是NewsDaoImpl类的代码。
1 | package org.crazyit.app.dao.impl; |
配置文件
下面是本应用示例所使用的配置文件。
1 |
|
配置文件详解
引入命名空间
配置文件中使用XML Schema启用了Spring配置文件的tx:、aop:两个命名空间:
1 | <beans |
配置事务增强处理
程序中的:
1 | <!-- 配置事务增强处理Bean,指定事务管理器 --> |
这段XML代码配置了一个事务增强处理,配置<tx:advice>元素时只需指定一个transaction-manager属性,该属性的默认值是"transactionManager"。
如果事务管理器Bean( PlatformTransactionManager实现类)的名字是transactionManager,则配置<tx:advice>元素时完全可以省略transaction-manager属性。如果为事务管理器Bean指定了其他名字,则需要为<tx:advice.>元素指定transaction-manager属性。
确保事务增强处理在合适的切入点被织入
配置文件中最后一段XML代码:
1 | <!-- AOP配置的元素 --> |
是<aop:config>定义,它确保由txAdvice切面定义的事务增强处理能在合适的切入点被织入。上面这段代码先定义了一个切入点,它匹配org.crazyit.app.dao.impl包下所有以Impl结尾的类所包含的所有方法,该切入点被命名为myPointcut然后用一个<aop:advisor>把这个切入点与txAdvice绑定在一起,表示当myPointcut执行时, txAdvice定义的增强处理将被织入。
提示<aop:advisor>元素是一个很奇怪的东西,标准的AOP机制里并没有所谓的Advisor", Advisor的作用非常简单:将Advice和切入点(既可通过pointcut-ref指定个已有的切入点,也可通过pointcut指定切入点表达式)绑定在一起,保证Advice所包含的增强处理将在对应的切入点被织入。
使用这种配置策略时,无须专门为每个业务Bean配置事务代理, Spring AOP会自动为所有匹配切入点表达式的业务组件生成代理,程序可以直接请求容器中的newsDao Bean,该Bean的方法已经具有了事务性——因为该Bean的实现类位于org.crazyit.app.dao.impl包下,且以Impl结尾,和poIntcut切入点匹配。
主程序
本示例的主程序非常简单,直接获取newsDao这个Bean,并调用它的insert()方法,可以看到该方法已经具有了事务性。
1 | package lee; |
上面的配置文件直接获取容器中的newsDao这个Bean,因为Spring AOP会为该Bean自动织入事务增强处理的方式,所以newsDao这个bean里的所有方法都具有事务性。
运行上面的程序,将出现一个异常,因为有了事务控制,出现异常的insert()方法所执行的两条SQL语句将全部回滚。
事务代理的业务方法
当使用<tx:advisor>为目标Bean生成事务代理之后, Spring AOP将会把负责事务操作的增强处理织入目标Bean的业务方法中。在这种情况下,事务代理的业务方法将如图8.20所示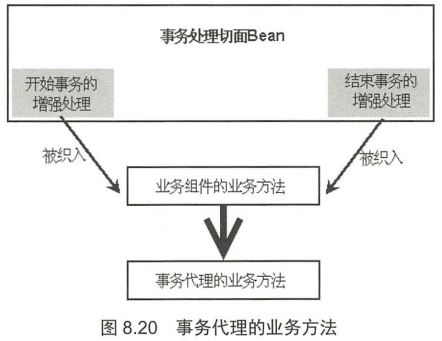
当采用<aop:advisor>元素将Advice和切入点绑定时,实际上是由Spring提供的Bean后处理器完成的。 Spring提供了BeanNameAutoProxyCreator和DefaultAdvisorAutoProxyCreator这两个Bean后处理器,它们都可以对容器中的Bean执行后处理(为它们织入切面中包含的增强处理)。在配置<aop:advisor>元素时传入一个txAdvice事务增强处理后,Bean后处理器将为所有Bean实例里匹配切入点的方法织入事务操作的增强处理。
为不同的业务逻辑方法指定不同的事务策略
在声明式事务策略下, Spring也允许为不同的业务逻辑方法指定不同的事务策略,如下面的配置文件所示。
在遇到特定checked异常时自动回滚
如果想让事务在遇到特定的checked异常时自动回滚,则可借助于rollback-for属性。
在默认情况下,只有当方法引发运行时异常和unchecked异常时, Spring事务机制才会自动回滚事务。也就是说,只有当抛出一个RuntimeException或其子类实例,或Error对象时, Spring才会自动回滚事务。如果事务方法拋出checked异常,则事务不会自动回滚
通过使用rollback-for属性可强制Spring遇到特定checked异常时自动回滚事务,下面的XML配置片段示范了这种用法。
遇到特定runtime异常时强制不回滚
如果想让Spring遇到特定runtime异常时强制不回滚事务,则可通过no-rollback-for属性来指定如下面的配置片段所示。
