10.3 排序二叉树
10.3 排序二叉树
HashMap和HashSet的共同实现机制是哈希表,一个共同的限制是没有顺序,我们提到,它们都有一个能保持顺序的对应类TreeMap和TreeSet,这两个类的共同实现基础是排序二叉树。为了更好地理解TreeMap和TreeSet,本节先介绍排序二叉树的一些基本概念和算法。
10.3.1 基本概念
先来说树的概念。现实中,树是从下往上长的,树会分叉,在计算机程序中,一般而言,与现实相反,树是从上往下长的,也会分叉,有个根节点,每个节点可以有一个或多个孩子节点,没有孩子节点的节点一般称为叶子节点。
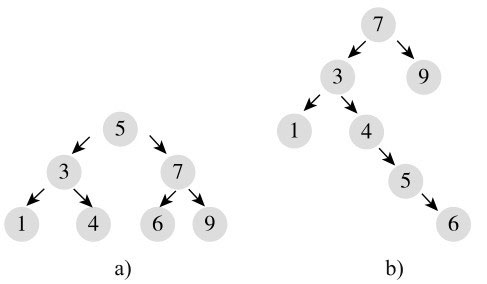
二叉树是一棵树,每个节点最多有两个孩子节点,一左一右,左边的称为左孩子,右边的称为右孩子,示例如图10-5所示。
图10-5中,两棵树都是二叉树,图10-5(a)所示二叉树的根节点为5,除了叶子节点外,每个节点都有两个孩子节点;图10-5(b)所示二叉树的根节点为7,有的节点有两个孩子节点,有的只有一个。树有一个高度或深度的概念,是从根到叶子节点经过的节点个数的最大值,左边树的高度为3,右边树的高度为5。
排序二叉树也是二叉树,但它没有重复元素,而且是有序的二叉树。什么顺序呢?对每个节点而言:
- 如果左子树不为空,则左子树上的所有节点都小于该节点;
- 如果右子树不为空,则右子树上的所有节点都大于该节点。
图10-5中的两棵二叉树都是排序二叉树。比如左边的树,根节点为5,左边的都小于5,右边的都大于5。再看右边的树,根节点为7,左边的都小于7,右边的都大于7,在以3为根的左子树中,其右子树的值都大于3。
10.3.2 基本算法
排序二叉树有什么优点?如何在树中进行基本操作(如查找、遍历、插入和删除)呢?我们来看一下基本的算法。
1.查找
排序二叉树有一个很好的优点,在其中查找一个元素时很方便、也很高效,基本步骤为:
1)首先与根节点比较,如果相同,就找到了;
2)如果小于根节点,则到左子树中递归查找;
3)如果大于根节点,则到右子树中递归查找。
这个步骤与在数组中进行二分查找的思路是类似的,如果二叉树是比较平衡的,类似图10-5(a)所示二叉树,则每次比较都能将比较范围缩小一半,效率很高。
此外,在排序二叉树中,可以方便地查找最小值和最大值。最小值即为最左边的节点,从根节点一路查找左孩子即可;最大值即为最右边的节点,从根节点一路查找右孩子即可。
2.遍历
排序二叉树也可以方便地按序遍历。用递归的方式,用如下算法即可按序遍历:
1)访问左子树;
2)访问当前节点;
3)访问右子树。
比如,遍历访问图10-6所示的二叉树。
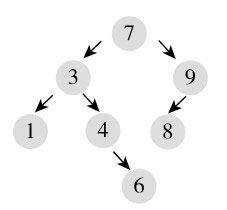
从根节点开始,但先访问根节点的左子树,一直到最左边的节点,所以第一个访问的是1,1没有右子树,返回上一层,访问3,然后访问3的右子树,4没有左子树,所以访问4,然后是4的右子树6,以此类推,访问顺序就是有序的:1、3、4、6、7、8、9。
不用递归的方式,也可以实现按序遍历,第一个节点为最左边的节点,从第一个节点开始,依次找后继节点。给定一个节点,找其后继节点的算法为:
1)如果该节点有右孩子,则后继节点为右子树中最小的节点。
2)如果该节点没有右孩子,则后继节点为父节点或某个祖先节点,从当前节点往上找,如果它是父节点的右孩子,则继续找父节点,直到它不是右孩子或父节点为空,第一个非右孩子节点的父节点就是后继节点,如果找不到这样的祖先节点,则后继为空,遍历结束。
文字描述比较抽象,我们来看个图,以图10-6为例,每个节点的后继节点如图10-7浅色箭头所示。
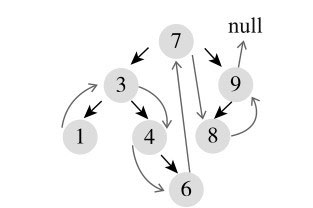
对每个节点,对照算法,我们再详细解释下:
1)第一个节点1没有右孩子,它不是父节点的右孩子,所以它的后继节点就是其父节点3;
2)3有右孩子,右子树中最小的就是4,所以3的后继节点为4;
3)4有右孩子,右子树中只有一个节点6,所以4的后继节点为6;
4)6没有右孩子,往上找父节点,它是父节点4的右孩子,4又是父节点3的右孩子, 3不是父节点7的右孩子,所以6的后继节点为3的父节点7;
5)7有右孩子,右子树中最小的是8,所以7的后继节点为8;
6)8没有右孩子,往上找父节点,它不是父节点9的右孩子,所以它的后继节点就是其父节点9;
7)9没有右孩子,往上找父节点,它是父节点7的右孩子,接着往上找,但7已经是根节点,父节点为空,所以后继为空。
怎么构建排序二叉树呢?可以在插入、删除元素的过程中形成和保持。
3.插入
在排序二叉树中,插入元素首先要找插入位置,即新节点的父节点,怎么找呢?与查找元素类似,从根节点开始往下找,其步骤为:
1)与当前节点比较,如果相同,表示已经存在了,不能再插入;
2)如果小于当前节点,则到左子树中寻找,如果左子树为空,则当前节点即为要找的父节点;
3)如果大于当前节点,则到右子树中寻找,如果右子树为空,则当前节点即为要找的父节点。
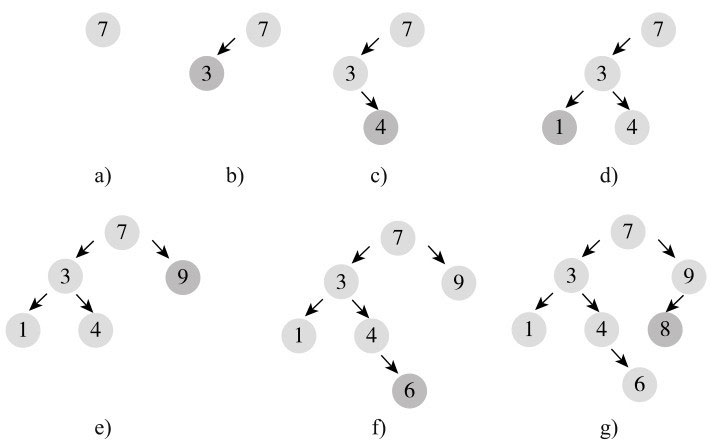
找到父节点后,即可插入,如果插入元素小于父节点,则作为左孩子插入,否则作为右孩子插入。我们来看个例子,依次插入7、3、4、1、9、6、8的过程,这个过程如图10-8所示。
4.删除
从排序二叉树中删除一个节点要复杂一些,有三种情况:
- 节点为叶子节点;
- 节点只有一个孩子节点;
- 节点有两个孩子节点。
我们分别介绍。
如果节点为叶子节点,则很简单,可以直接删掉,修改父节点的对应孩子节点为空即可。
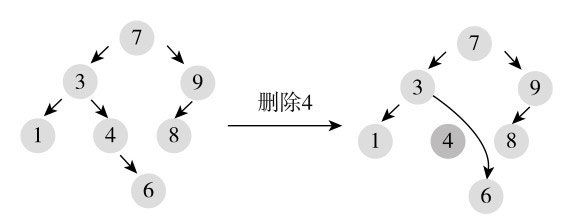
如果节点只有一个孩子节点,则替换待删节点为孩子节点,或者说,在孩子节点和父节点之间直接建立链接。比如,在图10-9中,左边二叉树中删除节点4,就是让4的父节点3与4的孩子节点6直接建立链接。
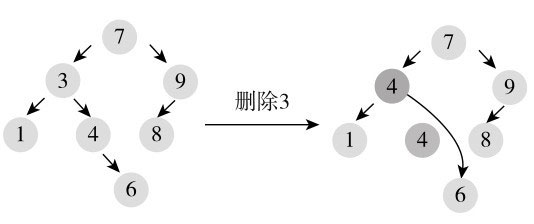
如果节点有两个孩子节点,则首先找该节点的后继节^1,找到后继节点后,替换待删节点为后继节点的内容,然后再删除后继节点。后继节点没有左孩子,这就将两个孩子节点的情况转换为了叶子节点或只有一个孩子节点的情况。比如,在图10-10中,从左边二叉树中删除节点3,3有两个孩子节点,后继节点为4,首先替换3的内容为4,然后再删除节点4。
10.3.3 平衡的排序二叉树
从前面的描述中可以看出,排序二叉树的形状与插入和删除的顺序密切相关,极端情况下,排序二叉树可能退化为一个链表。比如,如果插入顺序为1、3、4、6、7、8、9,则排序二叉树如图10-11所示。
退化为链表后,排序二叉树的优点就都没有了,即使没有退化为链表,如果排序二叉树高度不平衡,效率也会变得很低。

平衡具体定义是什么呢?有一种高度平衡的定义,即任何节点的左右子树的高度差最多为一。满足这个平衡定义的排序二叉树又被称为AVL树,这个名字源于它的发明者G.M. Adelson-Velsky和E.M. Landis。在他们的算法中,在插入和删除节点时,通过一次或多次旋转操作来重新平衡树。
在TreeMap的实现中,用的并不是AVL树,而是红黑树,与AVL树类似,红黑树也是一种平衡的排序二叉树,也是在插入和删除节点时通过旋转操作来平衡的,但它并不是高度平衡的,而是大致平衡的。所谓大致是指,它确保任意一条从根到叶子节点的路径,没有任何一条路径的长度会比其他路径长过两倍。红黑树减弱了对平衡的要求,但降低了保持平衡需要的开销,在实际应用中,统计性能高于AVL树。
为什么叫红黑树呢?因为它对每个节点进行着色,颜色或黑或红,并对节点的着色有一些约束,满足这个约束即可以确保树是大致平衡的。
对AVL树和红黑树,它们保持平衡的细节都是比较复杂的,我们就不介绍了,需要知道的是,它们都是排序二叉树,都通过在插入和删除时执行开销不大的旋转操作保持了树的高度平衡或大致平衡,从而保证了树的查找效率。
10.3.4 小结
本小节介绍了排序二叉树的基本概念和算法。
排序二叉树保持了元素的顺序,而且是一种综合效率很高的数据结构,基本的保存、删除、查找的效率都为O(h), h为树的高度。在树平衡的情况下,h为log2(N),N为节点数。比如,如果N为1024,则log2(N)为10。
基本的排序二叉树不能保证树的平衡,可能退化为一个链表。有很多保持树平衡的算法,AVL树能保证树的高度平衡,但红黑树是实际中使用更为广泛的,虽然红黑树只能保证大致平衡,但降低了维持树平衡需要的开销,整体统计效果更好。
与哈希表一样,树也是计算机程序中一种重要的数据结构和思维方式。为了能够快速操作数据,哈希和树是两种基本的思维方式,不需要顺序,优先考虑哈希,需要顺序,考虑树。除了容器类TreeMap/TreeSet,数据库中的索引结构也是基于树的(不过基于B树,而不是二叉树),而索引是能够在大量数据中快速访问数据的关键。
理解了排序二叉树的基本概念和算法,理解TreeMap和TreeSet就比较容易了,让我们在接下来的小节中探讨这两个类。