15.9.4 字符集和Charset
15.9.4 字符集和Charset
前面已经提到:计算机里的文件、数据、图片文件只是一种表面现象,所有文件在底层都是二进制文件,即全部都是字节码。
图片、音乐文件暂时先不说,对于文本文件而言,之所以可以看到一个个的字符,是因为系统将底层的二进制序列转换成字符的缘故。
在这个过程中涉及两个概念:编码Encode)和解码(Decode).
编码解码
编码
把明文的字符序列转换成计算机理解的二进制序列称为编码
解码
把二进制序列转换成普通人能看懂的明文字符串序列称为解码
编码解码示意图
如图15.21所示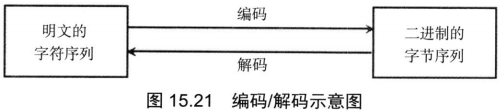
Encode和Decode术语起源
Encode和Decode两个专业术语来自于早期的电报、情报等。
- 把明文的消息转换成普通人看不懂的电码(或密码)的过程就是
Encode, - 将电码(或密码)翻译成明文的消息则被称为
Decode。
后来计算机也采用了这两个概念,其作用已经发生了变化
计算机底层是没有文本文件、图片文件之分的,它只是忠实地记录每个文件的二进制序列而已。
- 当需要保存文本文件时,程序必须先把文件中的每个字符翻译成二进制序列;
- 当需要读取文本文件时,程序必须把二进制序列转换为一个个的字符。
Java默认使用Unicode字符集,但很多操作系统并不使用Unicode字符集,那么当从系统中读取数据到Java程序中时,就可能出现乱码等问题
Charset类方法
JDK1.4提供了Charset来处理字节序列和字符序列(字符串)之间的转换关系,该类包含了用于创建解码器和编码器的方法,还提供了获取Charset所支持字符集的方法,Charset类是不可变的
获取JDK支持的全部字符集
Charset类提供了一个availableCharsets()静态方法来获取当前JDK所支持的所有字符集。
| 方法 | 描述 |
|---|---|
static SortedMap<String,Charset> availableCharsets() |
Constructs a sorted map from canonical charset names to charset objects. |
获取本地系统的文件编码格式
可以使用System类的getProperty()方法来访问本地系统的文件编码格式,文件编码格式的属性名为file.encoding。
程序 获取JDK支持的全部字符集
所以程序可以使用如下程序来获取该JDK所支持的全部字符集。
1 | import java.nio.charset.*; |
上面程序中的获取了当前Java所支持的全部字符集,并使用遍历方式打印了所有字符集的别名(字符集的字符串名称)和Charset对象。
从上面程序可以看出,每个字符集都有一个字符串名称,也被称为字符串别名。
中国常用字符集的字符串别名
对于中国的程序员而言,下面几个字符串别名是常用的。
| 字符集 | 描述 |
|---|---|
GBK |
简体中文字符集。 |
BIG5 |
繁体中文字符集。 |
ISO-8859-1 |
ISO拉丁字母表No.1,也叫做ISO-LATIN-1。 |
UTF-8 |
8位UCS转换格式。 |
UTF-16BE |
16位UCS转换格式,Big-endian(最低地址存放高位字节)字节顺序。 |
UTF-16LE |
16位UCS转换格式,Little-endian(最高地址存放低位字节)字节顺序。 |
UTF-16 |
16位UCS转换格式,字节顺序由可选的字节顺序标记来标识。 |
创建Charset对象 forName方法
一旦知道了字符集的别名之后,程序就可以调用Charset的forName()方法:
| 方法 | 描述 |
|---|---|
static Charset forName(String charsetName) |
Returns a charset object for the named charset. |
来创建对应的Charset对象,forName方法的参数就是相应字符集的别名。
例如如下代码
1 | Charset gbk = Charset.forName("GBK"); |
StandardCharsets类获取Charset对象
Java7新增了一个StandardCharsets类,该类里包含了ISO_8859_1、UTF_8、UTF_16等类变量,这些类变量代表了最常用的字符集对应的Charset对象:
StandardCharsets的类变量 |
描述 |
|---|---|
static Charset ISO_8859_1 |
ISO Latin Alphabet No. 1, a.k.a. |
static Charset US_ASCII |
Seven-bit ASCII, a.k.a. |
static Charset UTF_16 |
Sixteen-bit UCS Transformation Format, byte order identified by an optional byte-order mark |
static Charset UTF_16BE |
Sixteen-bit UCS Transformation Format, big-endian byte order |
static Charset UTF_16LE |
Sixteen-bit UCS Transformation Format, little-endian byte order |
static Charset UTF_8 |
Eight-bit UCS Transformation Format |
获取解码器 编码器
获得了Charset对象之后,就可以通过该对象的newDecoder()、newEncoder()这两个方法分别返回该Charset的解码器CharsetDecoder和编码器CharsetEncoder对象。
| 方法 | 描述 |
|---|---|
abstract CharsetDecoder newDecoder() |
Constructs a new decoder for this charset. |
abstract CharsetEncoder newEncoder() |
Constructs a new encoder for this charset. |
字符序列 转 字节序列(编码)
调用编码器CharsetEncoder的encode()方法就可以将CharBuffer或String(字符序列)转换成ByteBuffer(字节序列)。
字节序列 转 字符序列(解码)
调用解码器CharsetDecoder的decode()方法就可以将ByteBuffer(字节序列)转换成CharBuffer(字符序列),
程序 ByteBuffer转CharBuffer CharBuffer转ByteBuffer
如下程序使用了CharsetEncoder和CharsetDecoder完成了ByteBuffer和CharBuffer之间的转换
1 | import java.nio.*; |
上面程序中的分别实现了将CharBuffer转换成ByteBuffer,将ByteBuffer转换成CharBuffer的功能。
Charset中编码和解码的快捷方法
实际上,Charset类也提供了如下三个方法。
| 方法 | 描述 |
|---|---|
CharBuffer decode(ByteBuffer bb) |
将ByteBuffer中的字节序列转换成字符序列的便捷方法。 |
ByteBuffer encode(String str) |
将CharBuffer中的字符序列转换成字节序列的便捷方法。 |
ByteBuffer encode(CharBuffer cb) |
将String中的字符序列转换成字节序列的便捷方法。 |
也就是说,获取了Charset对象后,如果仅仅需要进行简单的编码、解码操作,其实无须创建CharsetEncoder和CharsetDecoder对象,直接调用Charset的encode()和decode()方法进行编码、解码即可。
String类 字符串 转 字节序列(编码)
在String类里也提供了一个getBytes(String charset)方法,该方法返回**byte数组**,该方法也是使用指定的字符集将字符串转换成字节序列