11.3 堆和PriorityQueue的应用
11.3 堆和PriorityQueue的应用
PriorityQueue除了用作优先级队列,还可以用来解决一些别的问题,本章开头提到了如下两个应用。
1)求前K个最大的元素,元素个数不确定,数据量可能很大,甚至源源不断到来,但需要知道到目前为止的最大的前K个元素。这个问题的变体有:求前K个最小的元素,求第K个最大的元素,求第K个最小的元素。
2)求中值元素,中值不是平均值,而是排序后中间那个元素的值,同样,数据量可能很大,甚至源源不断到来。
本节,我们就来探讨如何解决这两个问题。
11.3.1 求前K个最大的元素
一个简单的思路是排序,排序后取最大的K个就可以了,排序可以使用Arrays.sort()方法,效率为O(N×log2(N))。不过,如果K很小,比如是1,就是取最大值,对所有元素完全排序是毫无必要的。另一个简单的思路是选择,循环选择K次,每次从剩下的元素中选择最大值,这个效率为O(N×K),如果K的值大于log2(N),这个就不如完全排序了。
不过,这两个思路都假定所有元素都是已知的,而不是动态添加的。如果元素个数不确定,且源源不断到来呢?
一个基本的思路是维护一个长度为K的数组,最前面的K个元素就是目前最大的K个元素,以后每来一个新元素的时候,都先找数组中的最小值,将新元素与最小值相比,如果小于最小值,则什么都不用变,如果大于最小值,则将最小值替换为新元素。
这有点类似于生活中的末位淘汰,新元素与原来最末尾的比即可,要么不如最末尾,上不去,要么替掉原来的末尾。
这样,数组中维护的永远是最大的K个元素,而且不管源数据有多少,需要的内存开销是固定的,就是长度为K的数组。不过,每来一个元素,都需要找最小值,都需要进行K次比较,能不能减少比较次数呢?
解决方法是使用最小堆维护这K个元素,最小堆中,根即第一个元素永远都是最小的,新来的元素与根比就可以了,如果小于根,则堆不需要变化,否则用新元素替换根,然后向下调整堆即可,调整的效率为O(log2(K)),这样,总体的效率就是O(N×log2(K)),这个效率非常高,而且存储成本也很低。
使用最小堆之后,第K个最大的元素也很容易获得,它就是堆的根。
理解了思路,下面我们来看代码。我们实现一个简单的TopK类,如代码清单11-1所示。
1 | public class TopK <E> { |
我们稍微解释一下。TopK内部使用一个优先级队列和k,构造方法接受一个参数k,使用PriorityQueue的默认构造方法,假定元素实现了Comparable接口。
add方法实现向其中动态添加元素,如果元素个数小于k直接添加,否则与最小值比较,只在大于最小值的情况下添加,添加前,先删掉原来的最小值。addAll方法循环调用add方法。
toArray方法返回当前的最大的K个元素,getKth方法返回第K个最大的元素。
我们来看一下使用的例子:
1 | TopK<Integer> top5 = new TopK<>(5); |
保留5个最大的元素,输出为:
1 | [21, 23, 34, 100, 90] |
代码比较简单,就不解释了。
11.3.2 求中值
中值就是排序后中间那个元素的值,如果元素个数为奇数,中值是没有歧义的,但如果是偶数,中值可能有不同的定义,可以为偏小的那个,也可以是偏大的那个,或者两者的平均值,或者任意一个,这里,我们假定任意一个都可以。
一个简单的思路是排序,排序后取中间那个值就可以了,排序可以使用Arrays.sort()方法,效率为O(N× log2(N))。
不过,这要求所有元素都是已知的,而不是动态添加的。如果元素源源不断到来,如何实时得到当前已经输入的元素序列的中位数?
可以使用两个堆,一个最大堆,一个最小堆,思路如下。
1)假设当前的中位数为m,最大堆维护的是<=m的元素,最小堆维护的是>=m的元素,但两个堆都不包含m。
2)当新的元素到达时,比如为e,将e与m进行比较,若e<=m,则将其加入最大堆中,否则将其加入最小堆中。
3)第2步后,如果此时最小堆和最大堆的元素个数的差值>=2 ,则将m加入元素个数少的堆中,然后从元素个数多的堆将根节点移除并赋值给m。
我们通过一个例子来解释下。比如输入元素依次为:
1 | 34, 90, 67, 45,1 |
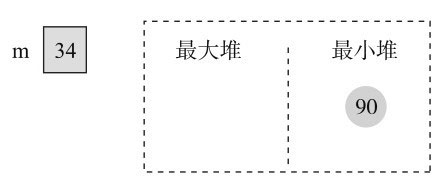
输入第1个元素时,m即为34。
输入第2个元素时,90大于34,加入最小堆,中值不变,如图11-20所示。
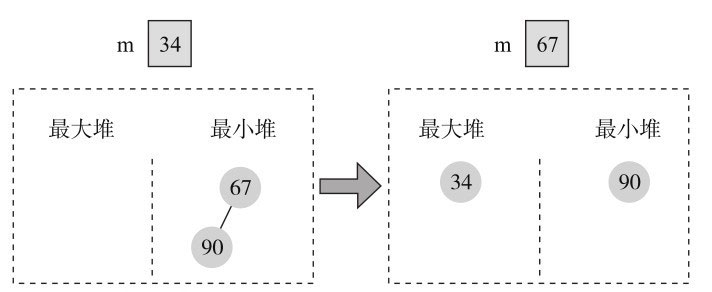
输入第3个元素时,67大于34,加入最小堆,但加入最小堆后,最小堆的元素个数为2,需调整中值和堆,现有中值34加入最大堆中,最小堆的根67从最小堆中删除并赋值给m,如图11-21所示。
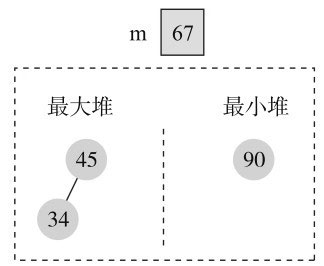
输入第4个元素45时,45小于67,加入最大堆,中值不变,如图11-22所示。
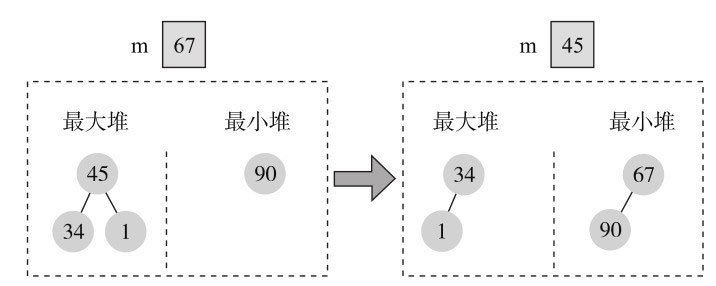
输入第5个元素1时,1小于67,加入最大堆,此时需调整中值和堆,现有中值67加入最小堆中,最大堆的根45从最大堆中删除并赋值给m,如图11-23所示。
理解了基本思路,我们来实现一个简单的中值类Median,如代码清单11-2所示。
1 | public class Median <E> { |
代码和思路基本是对应的,比较简单,就不解释了。我们来看一个使用的例子:
1 | Median<Integer> median = new Median<>(); |
输出为中值9。
11.3.3 小结
本节介绍了堆和PriorityQueue的两个应用,求前K个最大的元素和求中值,介绍了基本思路和实现代码,相比使用排序,使用堆不仅实现效率更高,而且可以应对数据量不确定且源源不断到来的情况,可以给出实时结果。
之前章节我们还介绍过ArrayDeque。PriorityQueue和ArrayDeque都是队列,都是基于数组的,但都不是简单的数组,通过一些特殊的约束、辅助成员和算法,它们都能高效地解决一些特定的问题,这大概是计算机程序中使用数据结构和算法的一种艺术吧。
至此,关于堆的概念与算法、优先级队列PriorityQueue及其应用,就介绍完了。之前的章节中,我们介绍的基本都是具体的容器类,下一章,我们看一些抽象容器类,以及针对容器接口的通用功能,并对整个容器类体系进行总结。