4.3.2 JConsole:Java监视与管理控制台
4.3.2 JConsole:Java监视与管理控制台
JConsole(Java Monitoring and Management Console)是一款基于JMX(Java Manage-ment Extensions)的可视化监视、管理工具。它的主要功能是通过JMX的MBean(Managed Bean)对系统进行信息收集和参数动态调整。JMX是一种开放性的技术,不仅可以用在虚拟机本身的管理上,还可以运行于虚拟机之上的软件中,典型的如中间件大多也基于JMX来实现管理与监控。虚拟机对JMX MBean的访问也是完全开放的,可以使用代码调用API、支持JMX协议的管理控制台,或者其他符合JMX规范的软件进行访问。
图4-10 JConsole连接页面
1.启动JConsole
通过JDK/bin目录下的jconsole.exe启动JCon-sole后,会自动搜索出本机运行的所有虚拟机进程,而不需要用户自己使用jps来查询,如图4-10所示。双击选择其中一个进程便可进入主界面开始监控。 JMX支持跨服务器的管理,也可以使用下面的“远程进程”功能来连接远程服务器,对远程虚拟机进行监控。
图4-10中可以看到笔者的机器现在运行了Eclipse、JConsole、MonitoringTest三个本地虚拟机进程,这里MonitoringTest是笔者准备的“反面教材”代码之一。双击它进入JConsole主界面,可以看到主界面里共包括“概述”“内存”“线程”“类”“VM摘要”“MBean”六个页签,如图4-11所示。
图4-11 JConsole主界面
“概述”页签里显示的是整个虚拟机主要运行数据的概览信息,包括“堆内存使用情况”“线程”“类”“CPU使用情况”四项信息的曲线图,这些曲线图是后面“内存”“线程”“类”页签的信息汇总,具体内容将在稍后介绍。
2.内存监控
“内存”页签的作用相当于可视化的jstat命令,用于监视被收集器管理的虚拟机内存(被收集器直接管理的Java堆和被间接管理的方法区)的变化趋势。我们通过运行代码清单4-7中的代码来体验一下它的监视功能。运行时设置的虚拟机参数为:
1 | -Xms100m -Xmx100m -XX:+UseSerialGC |
代码清单4-7 JConsole监视代码
1 | /** |
这段代码的作用是以64KB/50ms的速度向Java堆中填充数据,一共填充1000次,使用JConsole 的“内存”页签进行监视,观察曲线和柱状指示图的变化。
程序运行后,在“内存”页签中可以看到内存池Eden区的运行趋势呈现折线状,如图4-12所示。监视范围扩大至整个堆后,会发现曲线是一直平滑向上增长的。从柱状图可以看到,在1000次循环执行结束,运行了System.gc()后,虽然整个新生代Eden和Survivor区都基本被清空了,但是代表老年代的柱状图仍然保持峰值状态,说明被填充进堆中的数据在System.gc()方法执行之后仍然存活。笔者的分析就到此为止,提两个小问题供读者思考一下,答案稍后公布。
1)虚拟机启动参数只限制了Java堆为100MB,但没有明确使用-Xmn参数指定新生代大小,读者能否从监控图中估算出新生代的容量?
2)为何执行了System.gc()之后,图4-12中代表老年代的柱状图仍然显示峰值状态,代码需要如何调整才能让System.gc()回收掉填充到堆中的对象?
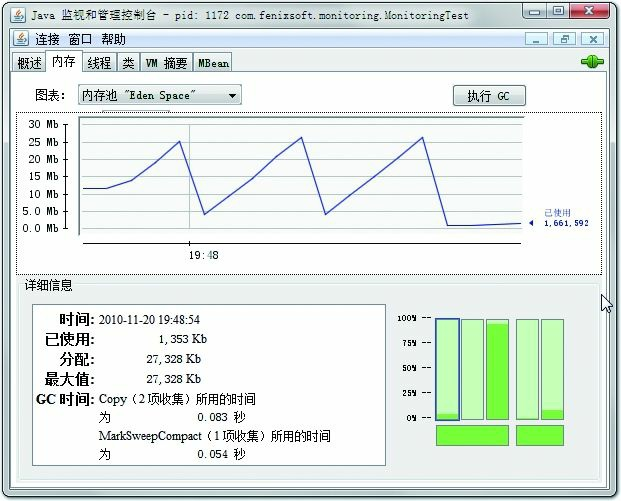
图4-12 Eden区内存变化状况
问题1答案:图4-12显示Eden空间为27328KB,因为没有设置-XX:SurvivorRadio参数,所以Eden 与Survivor空间比例的默认值为8∶1,因此整个新生代空间大约为27328KB×125%=34160KB。
问题2答案:执行System.gc()之后,空间未能回收是因为List<OOMObject>list对象仍然存活, fillHeap()方法仍然没有退出,因此list对象在System.gc()执行时仍然处于作用域之内^1。如果把System.gc()移动到fillHeap()方法外调用就可以回收掉全部内存。
3.线程监控
如果说JConsole的“内存”页签相当于可视化的jstat命令的话,那“线程”页签的功能就相当于可视化的jstack命令了,遇到线程停顿的时候可以使用这个页签的功能进行分析。前面讲解jstack命令时提到线程长时间停顿的主要原因有等待外部资源(数据库连接、网络资源、设备资源等)、死循环、锁等待等,代码清单4-8将分别演示这几种情况。
代码清单4-8 线程等待演示代码
1 | /** |
程序运行后,首先在“线程”页签中选择main线程,如图4-13所示。堆栈追踪显示BufferedReader的readBytes()方法正在等待System.in的键盘输入,这时候线程为Runnable状态,Runnable状态的线程仍会被分配运行时间,但readBytes()方法检查到流没有更新就会立刻归还执行令牌给操作系统,这种等待只消耗很小的处理器资源。
接着监控testBusyThread线程,如图4-14所示。testBusyThread线程一直在执行空循环,从堆栈追踪中看到一直在MonitoringTest.java代码的41行停留,41行的代码为while(true)。这时候线程为Runnable 状态,而且没有归还线程执行令牌的动作,所以会在空循环耗尽操作系统分配给它的执行时间,直到线程切换为止,这种等待会消耗大量的处理器资源。
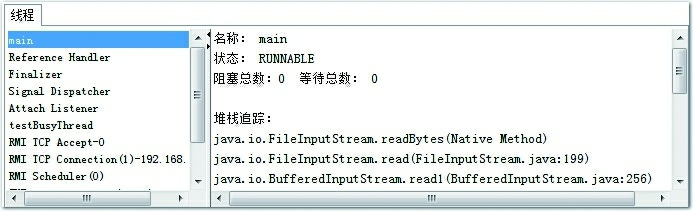
图4-13 main线程
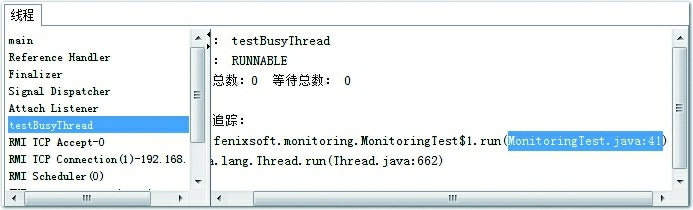
图4-14 testBusyThread线程
图4-15显示testLockThread线程在等待lock对象的notify()或notifyAll()方法的出现,线程这时候处于WAITING状态,在重新唤醒前不会被分配执行时间。
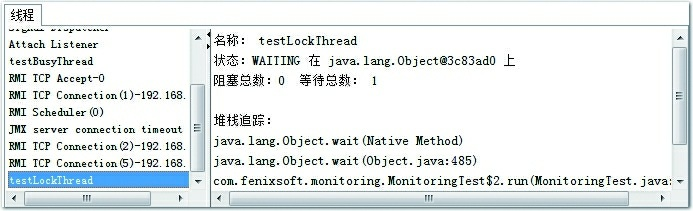
图4-15 testLockThread线程
testLockThread线程正处于正常的活锁等待中,只要lock对象的notify()或notifyAll()方法被调用, 这个线程便能激活继续执行。代码清单4-9演示了一个无法再被激活的死锁等待。
代码清单4-9 死锁代码样例
1 | /** |
这段代码开了200个线程去分别计算1+2以及2+1的值,理论上for循环都是可省略的,两个线程也可能会导致死锁,不过那样概率太小,需要尝试运行很多次才能看到死锁的效果。如果运气不是特别差的话,上面带for循环的版本最多运行两三次就会遇到线程死锁,程序无法结束。造成死锁的根本原因是Integer.valueOf()方法出于减少对象创建次数和节省内存的考虑,会对数值为-128~127之间的Integer对象进行缓存^2,如果valueOf()方法传入的参数在这个范围之内,就直接返回缓存中的对象。 也就是说代码中尽管调用了200次Integer.valueOf()方法,但一共只返回了两个不同的Integer对象。假如某个线程的两个synchronized块之间发生了一次线程切换,那就会出现线程A在等待被线程B持有的Integer.valueOf(1),线程B又在等待被线程A持有的Integer.valueOf(2),结果大家都跑不下去的情况。
出现线程死锁之后,点击JConsole线程面板的“检测到死锁”按钮,将出现一个新的“死锁”页签,如图4-16所示。

图4-16 线程死锁
图4-16中很清晰地显示,线程Thread-43在等待一个被线程Thread-12持有的Integer对象,而点击线程Thread-12则显示它也在等待一个被线程Thread-43持有的Integer对象,这样两个线程就互相卡住,除非牺牲其中一个,否则死锁无法释放。