7.0 第7章 常用基础类 7.1 包装类
第7章 常用基础类
本章介绍Java编程中一些常用的基础类,探讨它们的用法、应用和实现原理,这些类有:
- 各种包装类;
- 文本处理的类String和StringBuilder;
- 数组操作的类Arrays;
- 日期和时间处理;
- 随机。
7.1 包装类
Java有8种基本类型,每种基本类型都有一个对应的包装类。包装类是什么呢?它是一个类,内部有一个实例变量,保存对应的基本类型的值,这个类一般还有一些静态方法、静态变量和实例方法,以方便对数据进行操作。Java中,基本类型和对应的包装类如表7-1所示。
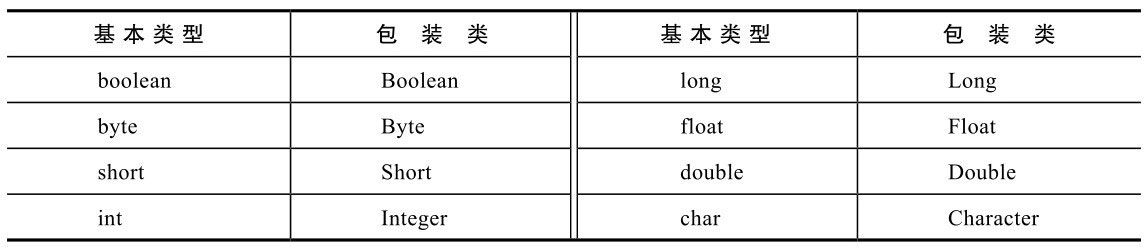
包装类也都很好记,除了Integer和Character外,其他类名称与基本类型基本一样,只是首字母大写。包装类有什么用呢?Java中很多代码(比如后续章节介绍的容器类)只能操作对象,为了能操作基本类型,需要使用其对应的包装类。另外,包装类提供了很多有用的方法,可以方便对数据的操作。下面先介绍各个包装类的基本用法及其共同点,然后重点介绍Integer和Character。
7.1.1 基本用法
各个包装类都可以与其对应的基本类型相互转换,方法也是类似的,部分类型如表7-2所示。
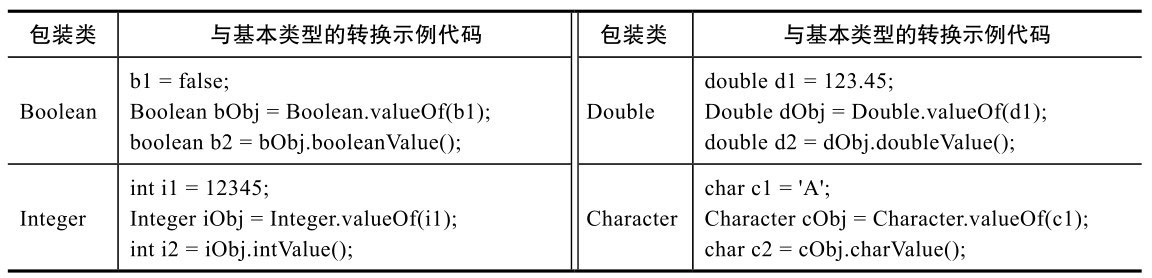
包装类与基本类型的转换代码结构是类似的,每种包装类都有一个静态方法valueOf(),接受基本类型,返回引用类型,也都有一个实例方法xxxValue()返回对应的基本类型。
将基本类型转换为包装类的过程,一般称为“装箱”,而将包装类型转换为基本类型的过程,则称为“拆箱”。装箱/拆箱写起来比较烦琐,Java 5以后引入了自动装箱和拆箱技术,可以直接将基本类型赋值给引用类型,反之亦可,比如:
1 | Integer a = 100; |
自动装箱/拆箱是Java编译器提供的能力,背后,它会替换为调用对应的valueOf/xxx-Value方法,比如,上面的代码会被Java编译器替换为:
1 | Integer a = Integer.valueOf(100); |
每种包装类也都有构造方法,可以通过new创建,比如:
1 | Integer a = new Integer(100); |
那到底应该用静态的valueOf方法,还是使用new呢?一般建议使用valueOf方法。new每次都会创建一个新对象,而除了Float和Double外的其他包装类,都会缓存包装类对象,减少需要创建对象的次数,节省空间,提升性能。实际上,从Java 9开始,这些构造方法已经被标记为过时了,推荐使用静态的valueOf方法。
7.1.2 共同点
各个包装类有很多共同点,比如,都重写了Object中的一些方法,都实现了Comparable接口,都有一些与String有关的方法,大部分都定义了一些静态常量,都是不可变的。下面具体介绍。
1.重写Object方法
所有包装类都重写了Object类的如下方法:
1 | boolean equals(Object obj) |
我们分别介绍。
(1)equals
equals用于判断当前对象和参数传入的对象是否相同,Object类的默认实现是比较地址,对于两个变量,只有这两个变量指向同一个对象时,equals才返回true,它和比较运算符(==)的结果是一样的。
equals应该反映的是对象间的逻辑相等关系,所以这个默认实现一般是不合适的,子类需要重写该实现。所有包装类都重写了该实现,实际比较用的是其包装的基本类型值,比如,对于Long类,其equals方法代码如下:
1 | public boolean equals(Object obj) { |
对于Float,其实现代码如下:
1 | public boolean equals(Object obj) { |
Float有一个静态方法floatToIntBits(),将float的二进制表示看作int。需要注意的是,只有两个float的二进制表示完全一样的时候,equals才会返回true。在2.2节的时候,我们提到小数计算是不精确的,数学概念上运算结果一样,但计算机运算结果可能不同,比如下面的代码:
1 | Float f1 = 0.01f; |
输出为:
1 | false |
也就是,两个浮点数不一样,将二进制看作整数也不一样,相差为1。
Double的equals方法与Float类似,它有一个静态方法doubleToLongBits,将double的二进制表示看作long,然后再按long比较。
(2)hashCode
hashCode返回一个对象的哈希值。哈希值是一个int类型的数,由对象中一般不变的属性映射得来,用于快速对对象进行区分、分组等。一个对象的哈希值不能改变,相同对象的哈希值必须一样。不同对象的哈希值一般应不同,但这不是必需的,可以有对象不同但哈希值相同的情况。
比如,对于一个班的学生对象,hashCode可以是学生的出生日期,出生日期是不变的,不同学生生日一般不同,分布比较均匀,个别生日相同的也没关系。
hashCode和equals方法联系密切,对两个对象,如果equals方法返回true,则hashCode也必须一样。反之不要求,equal方法返回false时,hashCode可以一样,也可以不一样,但应该尽量不一样。hashCode的默认实现一般是将对象的内存地址转换为整数,子类如果重写了equals方法,也必须重写hashCode。之所以有这个规定,是因为Java API中很多类依赖于这个行为,尤其是容器中的一些类。
包装类都重写了hashCode,根据包装的基本类型值计算hashCode,对于Byte、Short、Integer、Character, hashCode就是其内部值,代码为:
1 | public int hashCode() { |
对于Boolean, hashCode代码为:
1 | public int hashCode() { |
根据基类类型值返回了两个不同的数,为什么选这两个值呢?它们是质数(即只能被1和自己整除的数),质数用于哈希时比较好,不容易冲突。
对于Long, hashCode代码为:
1 | public int hashCode() { |
是高32位与低32位进行位异或操作。
对于Double, hashCode代码为:
1 | public int hashCode() { |
与equals方法类似,将double的二进制表示看作long,然后再按long计算hashCode。
每个包装类也都重写了toString方法,返回对象的字符串表示,这个一般比较自然,不再赘述。
2. Comparable
每个包装类都实现了Java API中的Comparable接口。Comparable接口代码如下:
1 | public int hashCode() { |
<T>是泛型语法,我们在第8章介绍,T表示比较的类型,由实现接口的类传入。接口只有一个方法compareTo,当前对象与参数对象进行比较,在小于、等于、大于参数时,应分别返回-1、0、1。
各个包装类的实现基本都是根据基本类型值进行比较,不再赘述。对于Boolean,false小于true。对于Float和Double,存在和equals方法一样的问题,0.01和0.1*0.1相比的结果并不为0。
3.包装类和String
除了toString方法外,包装类还有一些其他与String相关的方法。除了Character外,每个包装类都有一个静态的valueOf(String)方法,根据字符串表示返回包装类对象,如:
1 | public interface Comparable<T> { |
也都有一个静态的parseXXX(String)方法,根据字符串表示返回基本类型值,如:
1 | Boolean b = Boolean.valueOf("true"); |
都有一个静态的toString方法,根据基本类型值返回字符串表示,如:
1 | boolean b = Boolean.parseBoolean("true"); |
输出:
1 | System.out.println(Boolean.toString(true)); |
对于整数类型,字符串表示除了默认的十进制外,还可以表示为其他进制,如二进制、八进制和十六进制,包装类有静态方法进行相互转换,比如:
1 | true |
输出:
1 | System.out.println(Integer.toBinaryString(12345)); //输出二进制 |
4.常用常量
包装类中除了定义静态方法和实例方法外,还定义了一些静态变量。对于Boolean类型,有:
1 | 11000000111001 |
所有数值类型都定义了MAX_VALUE和MIN_VALUE,表示能表示的最大/最小值,比如,对Integer:
1 | public static final Boolean TRUE = new Boolean(true); |
Float和Double还定义了一些特殊数值,比如正无穷、负无穷、非数值,如Double类:
1 | public static final double POSITIVE_INFINITY = 1.0 / 0.0; //正无穷 |
5. Number
6种数值类型包装类有一个共同的父类Number。Number是一个抽象类,它定义了如下方法:
1 | byte byteValue() |
通过这些方法,包装类实例可以返回任意的基本数值类型。
6.不可变性
包装类都是不可变类。所谓不可变是指实例对象一旦创建,就没有办法修改了。这是通过如下方式强制实现的:
- 所有包装类都声明为了final,不能被继承。
- 内部基本类型值是私有的,且声明为了final。
- 没有定义setter方法。
为什么要定义为不可变类呢?不可变使得程序更为简单安全,因为不用操心数据被意外改写的可能,可以安全地共享数据,尤其是在多线程的环境下。关于线程,我们在第15章介绍。
7.1.3 剖析Integer与二进制算法
本小节主要介绍Integer类, Long与Integer类似,就不再单独介绍了。一个简单的Integer还有什么要介绍的呢?它有一些二进制操作,包括位翻转和循环移位等,另外,我们也分析一下它的valueOf实现。为什么要关心实现代码呢?大部分情况下,确实不用关心,会用它就可以了,我们主要是学习其中的二进制操作。二进制是计算机的基础,但代码往往晦涩难懂,我们希望对其有一个更为清晰深刻的理解。
1.位翻转
Integer有两个静态方法,可以按位进行翻转:
1 | public static int reverse(int i) |
位翻转就是将int当作二进制,左边的位与右边的位进行互换,reverse是按位进行互换, reverseBytes是按byte进行互换,我们来看个例子:
1 | int a = 0x12345678; |
a是整数,用十六进制赋值,首先输出其二进制字符串,接着输出reverse后的二进制,最后输出reverseBytes后的十六进制,输出为:
1 | 10010001101000101011001111000 |
reverseBytes是按字节翻转,78是十六进制表示的一个字节,12也是,所以结果78563412是比较容易理解的。二进制翻转初看是不对的,这是因为输出不是32位,输出时忽略了前面的0,我们补齐32位再看:
1 | 00010010001101000101011001111000 |
这次结果就对了。这两个方法是怎么实现的呢?
先来看reverseBytes的代码:
1 | public static int reverseBytes(int i) { |
代码比较晦涩,以参数i等于0x12345678为例,我们来分析执行过程:
1)i>>>24无符号右移,最高字节挪到最低位,结果是0x00000012;
2)(i>>8) & 0xFF00,左边第二个字节挪到右边第二个,i>>8结果是0x00123456,再进行& 0xFF00,保留的是右边第二个字节,结果是0x00003400;
3)(i << 8) & 0xFF0000,右边第二个字节挪到左边第二个,i<<8结果是0x34567800,再进行& 0xFF0000,保留的是右边第三个字节,结果是0x00560000;
4)i<<24,结果是0x78000000,最右字节挪到最左边。
这4个结果再进行或操作|,结果就是0x78563412,这样,通过左移、右移、与和或操作,就达到了字节翻转的目的。
我们再来看reverse的代码:
1 | public static int reverse(int i) { |
这段代码虽然很短,但非常晦涩,到底是什么意思呢?代码第一行是一个注释,HD表示的是一本书,书名为Hacker’s Delight,中文版为《算法心得:高效算法的奥秘》, HD是它的缩写,Figure 7-1是书中的图7-1, reverse的代码就是复制了这本书中图7-1的代码,书中也说明了代码的思路,我们简要说明。
高效实现位翻转的基本思路是:首先交换相邻的单一位,然后以两位为一组,再交换相邻的位,接着是4位一组交换、然后是8位、16位,16位之后就完成了。这个思路不仅适用于二进制,而且适用于十进制,为便于理解,我们看个十进制的例子。比如对数字12345678进行翻转。
第一轮,相邻单一数字进行互换,结果为:
1 | 21 43 65 87 |
第二轮,以两个数字为一组交换相邻的,结果为:
1 | 43 21 87 65 |
第三轮,以4个数字为一组交换相邻的,结果为:
1 | 8765 4321 |
翻转完成。
对十进制而言,这个效率并不高,但对于二进制而言,却是高效的,因为二进制可以在一条指令中交换多个相邻位。下面代码就是对相邻单一位进行互换:
1 | x = (x & 0x55555555) << 1 | (x & 0xAAAAAAAA) >>> 1; |
5的二进制表示是0101,0x55555555的二进制表示是:
1 | 01010101010101010101010101010101 |
x & 0x55555555就是取x的奇数位。
A的二进制表示是1010,0xAAAAAAAA的二进制表示是:
1 | 10101010101010101010101010101010 |
x & 0xAAAAAAAA就是取x的偶数位。
1 | (x & 0x55555555) << 1 | (x & 0xAAAAAAAA) >>> 1; |
表示的就是x的奇数位向左移,偶数位向右移,然后通过|合并,达到相邻位互换的目的。这段代码可以有个小的优化,只使用一个常量0x55555555,后半部分先移位再进行与操作,变为:
1 | (i & 0x55555555) << 1 | (i >>> 1) & 0x55555555; |
同理,如下代码就是以两位为一组,对相邻位进行互换:
1 | i = (i & 0x33333333) << 2 | (i & 0xCCCCCCCC)>>>2; |
3的二进制表示是0011,0x33333333的二进制表示是:
1 | 00110011001100110011001100110011 |
x & 0x33333333就是取x以两位为一组的低半部分。
C的二进制表示是1100,0xCCCCCCCC的二进制表示是:
1 | 11001100110011001100110011001100 |
x & 0xCCCCCCCC就是取x以两位为一组的高半部分。
1 | (i & 0x33333333) << 2 | (i & 0xCCCCCCCC)>>>2; |
表示的就是x以两位为一组,低半部分向高位移,高半部分向低位移,然后通过|合并,达到交换的目的。同样,可以去掉常量0xCCCCCCCC,代码可以优化为:
1 | (i & 0x33333333) << 2 | (i >>> 2) & 0x33333333; |
同理,下面代码就是以4位为一组进行交换。
1 | i = (i & 0x0f0f0f0f) << 4 | (i >>> 4) & 0x0f0f0f0f; |
到以8位为单位交换时,就是字节翻转了,可以写为如下更直接的形式,代码和reverse-Bytes基本完全一样。
1 | i = (i << 24) | ((i & 0xff00) << 8) | |
reverse代码为什么要写得这么晦涩呢?或者说不能用更容易理解的方式写吗?比如,实现翻转,一种常见的思路是:第一个和最后一个交换,第二个和倒数第二个交换,直到中间两个交换完成。如果数据不是二进制位,这个思路是好的,但对于二进制位,这个思路的效率比较低。
CPU指令并不能高效地操作单个位,它操作的最小数据单位一般是32位(32位机器),另外,CPU可以高效地实现移位和逻辑运算,但实现加、减、乘、除运算则比较慢。
reverse是在充分利用CPU的这些特性,并行高效地进行相邻位的交换,也可以通过其他更容易理解的方式实现相同功能,但很难比这个代码更高效。
2.循环移位
Integer有两个静态方法可以进行循环移位:
1 | public static int rotateLeft(int i, int distance) |
rotateLeft方法是循环左移,rotateRight方法是循环右移,distance是移动的位数。所谓循环移位,是相对于普通的移位而言的,普通移位,比如左移2位,原来的最高两位就没有了,右边会补0,而如果是循环左移两位,则原来的最高两位会移到最右边,就像一个左右相接的环一样。看个例子:
1 | int a = 0x12345678; |
b是a循环左移8位的结果,c是a循环右移8位的结果,所以输出为:
1 | 34567812 |
这两个函数的实现代码为:
1 | public static int rotateLeft(int i, int distance) { |
这两个函数中令人费解的是负数,如果distance是8,那i>>>-8是什么意思呢?其实,实际的移位个数不是后面的直接数字,而是直接数字的最低5位的值,或者说是直接数字&0x1f的结果。之所以这样,是因为5位最大表示31,移位超过31位对int整数是无效的。
理解了移动负数位的含义,就比较容易理解上面这段代码了,比如,-8的二进制表示是:
1 | 11111111111111111111111111111000 |
其最低5位是11000,十进制表示就是24,所以i>>>-8就是i>>>24, i<<8 |i>>>24就是循环左移8位。上面代码中,i>>>-distance就是i>>>(32-distance),i<<-distance就是i<<(32-distance)。
Integer中还有一些其他的位操作,具体可参看API文档。关于其实现代码,都有注释指向Hacker’s Delight这本书的相关章节,不再赘述。
3. valueOf的实现
在前面,我们提到,创建包装类对象时,可以使用静态的valueOf方法,也可以直接使用new,但建议使用valueOf方法,为什么呢?我们来看Integer的valueOf的代码(基于Java
7):
1 | public static Integer valueOf(int i) { |
它使用了IntegerCache,这是一个私有静态内部类,如代码清单7-1所示。
1 | private static class IntegerCache { |
IntegerCache表示Integer缓存,其中的cache变量是一个静态Integer数组,在静态初始化代码块中被初始化,默认情况下,保存了-128~127共256个整数对应的Integer对象。
在valueOf代码中,如果数值位于被缓存的范围,即默认-128~127,则直接从Integer-Cache中获取已预先创建的Integer对象,只有不在缓存范围时,才通过new创建对象。
通过共享常用对象,可以节省内存空间,由于Integer是不可变的,所以缓存的对象可以安全地被共享。Boolean、Byte、Short、Long、Character都有类似的实现。这种共享常用对象的思路,是一种常见的设计思路,它有一个名字,叫享元模式,英文叫Flyweight,即共享的轻量级元素。
7.1.4 剖析Character
本节探讨Character类。Character类除了封装了一个char外,还有什么可介绍的呢?它有很多静态方法,封装了Unicode字符级别的各种操作,是Java文本处理的基础,注意不是char级别,Unicode字符并不等同于char,本节详细介绍这些方法。在此之前,先来回顾一下Unicode知识。
1. Unicode基础
Unicode给世界上每个字符分配了一个编号,编号范围为0x000000~0x10FFFF。编号范围在0x0000~0xFFFF的字符为常用字符集,称BMP(Basic MultilingualPlane)字符。编号范围在0x10000~0x10FFFF的字符叫做增补字符(supplementary character)。
Unicode主要规定了编号,但没有规定如何把编号映射为二进制。UTF-16是一种编码方式,或者叫映射方式,它将编号映射为两个或4个字节,对BMP字符,它直接用两个字节表示,对于增补字符,使用4个字节表示,前两个字节叫高代理项(high surrogate),范围为0xD800~0xDBFF,后两个字节叫低代理项(lowsurrogate),范围为0xDC00~0xDFFF。UTF-16定义了一个公式,可以将编号与4字节表示进行相互转换。
Java内部采用UTF-16编码,char表示一个字符,但只能表示BMP中的字符,对于增补字符,需要使用两个char表示,一个表示高代理项,一个表示低代理项。
使用int可以表示任意一个Unicode字符,低21位表示Unicode编号,高11位设为0。整数编号在Unicode中一般称为代码点(code point),表示一个Unicode字符,与之相对,还有一个词代码单元(code unit)表示一个char。
Character类中有很多相关静态方法,下面分别介绍。
2.检查code point和char
1 | //判断一个int是不是一个有效的代码点,小于等于0x10FFFF的为有效,大于的为无效 |
3. code point与char的转换
除了简单的检查外,Character类中还有很多方法,进行code point与char的相互转换。
1 | //根据高代理项high和低代理项low生成代码点,这个转换有个公式,这个方法封装了这个公式 |
4.按code point处理char数组或序列
Character包含若干方法,以方便按照code point处理char数组或序列。
返回char数组a中从offset开始count个char包含的code point个数:
1 | public static int codePointCount(char[] a, int offset, int count) |
比如,如下代码输出为2, char个数为3,但code point为2。
1 | char[] chs = new char[3]; |
除了接受char数组,还有一个重载的方法接受字符序列CharSequence:
1 | public static int codePointCount(CharSequence seq, int beginIndex,int endIndex) |
CharSequence是一个接口,它的定义如下所示:
1 | public interface CharSequence { |
它与一个char数组是类似的,有length方法,有charAt方法根据索引获取字符,String类就实现了该接口。
返回char数组或序列中指定索引位置的code point:
1 | public static int codePointAt(char[] a, int index) |
如果指定索引位置为高代理项,下一个位置为低代理项,则返回两项组成的codepoint,检查下一个位置时,下一个位置要小于limit,没传limit时,默认为a.length。
返回char数组或序列中指定索引位置之前的code point:
1 | public static int codePointBefore(char[] a, int index) |
codePointAt是往后找,codePointBefore是往前找,如果指定位置为低代理项,且前一个位置为高代理项,则返回两项组成的code point,检查前一个位置时,前一个位置要大于等于start,没传start时,默认为0。
根据code point偏移数计算char索引:
1 | public static int offsetByCodePoints(char[] a, int start, int count,int index, int codePointOffset) |
如果字符数组或序列中没有增补字符,返回值为index+codePointOffset,如果有增补字符,则会将codePointOffset看作code point偏移,转换为字符偏移,start和count取字符数组的子数组。
比如,如下代码:
1 | char[] chs = new char[3]; |
5.字符属性
Unicode在给每个字符分配一个编号之外,还分配了一些属性,Character类封装了对Unicode字符属性的检查和操作,下面介绍一些主要的属性。
获取字符类型(general category):
1 | public static int getType(int codePoint) |
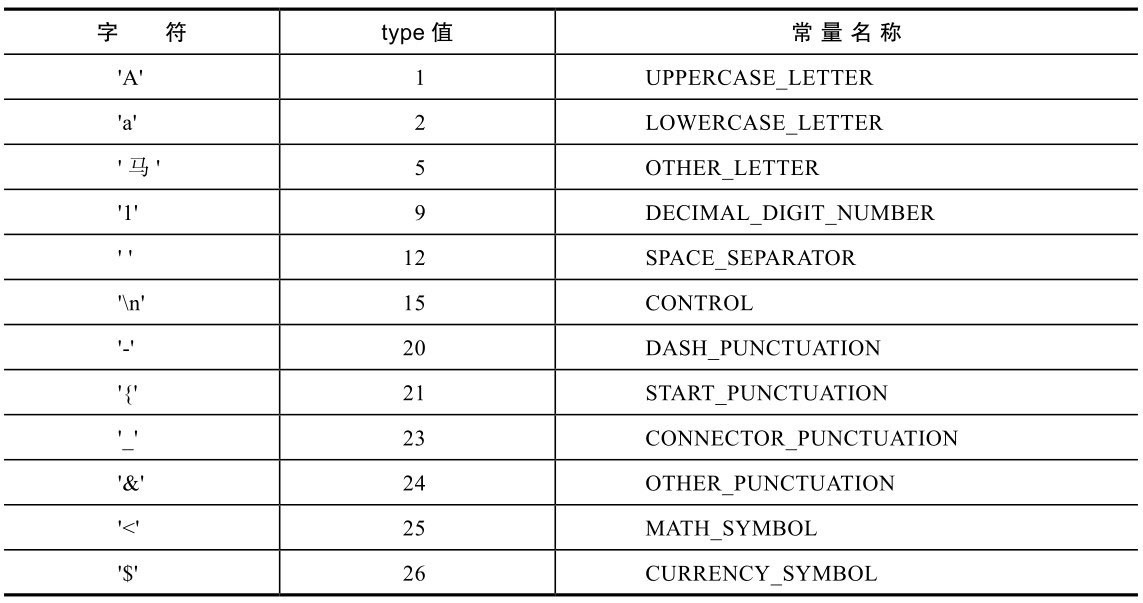
Unicode给每个字符分配了一个类型,这个类型是非常重要的,很多其他检查和操作都是基于这个类型的。getType方法的参数可以是int类型的code point,也可以是char类型。char类型只能处理BMP字符,而int类型可以处理所有字符。Character类中很多方法都是既可以接受int类型,也可以接受char类型,后续只列出int类型的方法。返回值是int,表示类型,Character类中定义了很多静态常量表示这些类型,表7-3列出了一些字符、type值,以及Character类中常量的名称。
检查字符是否在Unicode中被定义:
1 | public static boolean isDefined(int codePoint) |
每个被定义的字符,其getType()返回值都不为0,如果返回值为0,表示无定义。注意与isValidCodePoint的区别,后者只要数字不大于0x10FFFF都返回true。
检查字符是否为数字:
1 | public static boolean isDigit(int codePoint) |
getType()返回值为DECIMAL_DIGIT_NUMBER的字符为数字。需要注意的是,不光字符’0’、’1’、……、’9’是数字,中文全角字符的0~9也是数字。比如:
1 | char ch = '9'; //中文全角数字 |
输出为:
1 | 65305, true |
全角字符的9, Unicode编号为65305,它也是数字。
检查是否为字母(Letter):
1 | public static boolean isLetter(int codePoint) |
如果getType()的返回值为下列之一,则为Letter:
1 | UPPERCASE_LETTER |
除了TITLECASE_LETTER和MODIFIER_LETTER,其他在表7-3中有示例,而这两个平时碰到的也比较少,就不介绍了。
检查是否为字母或数字:
1 | public static boolean isLetterOrDigit(int codePoint) |
只要其中之一返回true就返回true。
检查是否为字母(Alphabetic):
1 | public static boolean isAlphabetic(int codePoint) |
这也是检查是否为字母,与isLetter的区别是:isLetter返回true时,isAlphabetic也必然返回true;此外,getType()值为LETTER_NUMBER时,isAlphabetic也返回true,而isLetter返回false。LETTER_NUMBER中常见的字符有罗马数字字符,如’I’、’Ⅱ’、’Ⅲ’、’Ⅳ’。
检查是否为空格字符:
1 | public static boolean isSpaceChar(int codePoint) |
getType()值为SPACE_SEPARATOR,LINE_SEPARATOR和PARAGRAPH_SEPARATOR时,返回true。这个方法其实并不常用,因为它只能严格匹配空格字符本身,不能匹配实际产生空格效果的字符,如Tab控制键’\t‘。
更常用的检查空格的方法:
1 | public static boolean isWhitespace(int codePoint) |
‘\t‘、’\n‘、全角空格’ ‘和半角空格’ ‘的返回值都为true。
检查是否为小写字符:
1 | public static boolean isLowerCase(int codePoint) |
常见的小写字符主要是小写英文字母a~z。
检查是否为大写字符:
1 | public static boolean isUpperCase(int codePoint) |
常见的大写字符主要是大写英文字母A~Z。
检查是否为表意象形文字:
1 | public static boolean isIdeographic(int codePoint) |
大部分中文都返回为true
检查是否为ISO 8859-1编码中的控制字符:
1 | public static boolean isISOControl(int codePoint) |
我们在第2章介绍过,0~31、127~159表示控制字符。
检查是否可作为Java标识符的第一个字符:
1 | public static boolean isJavaIdentifierStart(int codePoint) |
Java标识符是Java中的变量名、函数名、类名等,字母(Alphabetic)、美元符号($)、下画线(_)可作为Java标识符的第一个字符,但数字字符不可以。
检查是否可作为Java标识符的中间字符:
1 | public static boolean isJavaIdentifierPart(int codePoint) |
相比isJavaIdentifierStart,主要多了数字字符,Java标识符的中间字符可以包含数字。
检查是否为镜像(mirrowed)字符:
1 | public static boolean isMirrored(int codePoint) |
常见镜像字符有( )、{ }、< >、[ ],都有对应的镜像。
6.字符转换
Unicode除了规定字符属性外,对有大小写对应的字符,还规定了其对应的大小写,对有数值含义的字符,也规定了其数值。
我们先来看大小写,Character有两个静态方法,对字符进行大小写转换:
1 | public static int toLowerCase(int codePoint) |
这两个方法主要针对英文字符a~z和A~Z,例如:toLowerCase(‘A’)返回’a’,toUpper-Case(‘z’)返回’Z’。
返回一个字符表示的数值:
1 | public static int getNumericValue(int codePoint) |
字符’0’~’9’返回数值0~9,对于字符a~z,无论是小写字符还是大写字符,无论是普通英文还是中文全角,数值结果都是10~35。例如,如下代码的输出结果是一样的,都是10。
1 | System.out.println(Character.getNumericValue('A')); //全角大写A |
返回按给定进制表示的数值:
1 | public static int digit(int codePoint, int radix) |
radix表示进制,常见的有二进制、八进制、十进制、十六进制,计算方式与get-NumericValue类似,只是会检查有效性,数值需要小于radix,如果无效,返回-1。例如:digit(‘F’,16)返回15,是有效的;但digit(‘G’,16)就无效,返回-1。
返回给定数值的字符形式:
1 | public static char forDigit(int digit, int radix) |
与digit(int codePoint, int radix)相比,进行相反转换,如果数字无效,返回’\0‘。例如, Character.forDigit(15, 16)返回’F‘。
与Integer类似,Character也有按字节翻转:
1 | public static char reverseBytes(char ch) |
例如,翻转字符0x1234:
1 | System.out.println(Integer.toHexString(Character.reverseBytes((char)0x1234))); |
输出为3412。
至此,Characer类就介绍完了,它在Unicode字符级别(而非char级别)封装了字符的各种操作,通过将字符处理的细节交给Character类,其他类就可以在更高的层次上处理文本了。