10.6 剖析LinkedHashMap
10.6 剖析LinkedHashMap
前面我们介绍了Map接口的两个实现类HashMap和TreeMap,本节介绍另一个实现类LinkedHashMap。它是HashMap的子类,但可以保持元素按插入或访问有序,这与TreeMap按键排序不同。按插入有序容易理解,按访问有序是什么意思呢?这两个有序有什么用呢?内部是怎么实现的?本节就来探讨这些问题,从用法开始。
10.6.1 基本用法
LinkedHashMap是HashMap的子类,但内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于这个双向链表中。LinkedHashMap支持两种顺序:一种是插入顺序;另外一种是访问顺序。
插入顺序容易理解,先添加的在前面,后添加的在后面,修改操作不影响顺序。访问顺序是什么意思呢?所谓访问是指get/put操作,对一个键执行get/put操作后,其对应的键值对会移到链表末尾,所以,最末尾的是最近访问的,最开始的最久没被访问的,这种顺序就是访问顺序。
LinkedHashMap有5个构造方法,其中4个都是按插入顺序,只有一个构造方法可以指定按访问顺序,如下所示:
1 | public LinkedHashMap(int initialCapacity, float loadFactor, |
其中参数accessOrder就是用来指定是否按访问顺序,如果为true,就是访问顺序。默认情况下,LinkedHashMap是按插入有序的,我们看个例子:
1 | Map<String, Integer> seqMap = new LinkedHashMap<>(); |
键是按照”c”、”d”、”a”的顺序插入的,修改”d”的值不会修改顺序,所以输出为:
1 | c 100 |
什么时候希望保持插入顺序呢?
Map经常用来处理一些数据,其处理模式是:接收一些键值对作为输入,处理,然后输出,输出时希望保持原来的顺序。比如一个配置文件,其中有一些键值对形式的配置项,但其中有一些键是重复的,希望保留最后一个值,但还是按原来的键顺序输出, LinkedHashMap就是一个合适的数据结构。
再如,希望的数据模型可能就是一个Map,但希望保持添加的顺序,如一个购物车,键为购买项目,值为购买数量,按用户添加的顺序保存。
另外一种常见的场景是:希望Map能够按键有序,但在添加到Map前,键已经通过其他方式排好序了,这时,就没有必要使用TreeMap了,毕竟TreeMap的开销要大一些。比如,在从数据库查询数据放到内存时,可以使用SQL的order by语句让数据库对数据排序。
我们来看按访问有序的例子,代码如下:
1 | Map<String, Integer> accessMap = new LinkedHashMap<>(16, 0.75f, true); |
每次访问都会将该键值对移到末尾,所以输出为:
1 | a 500 |
什么时候希望按访问有序呢?一种典型的应用是LRU缓存,它是什么呢?
缓存是计算机技术中一种非常有用的技术,是一个通用的提升数据访问性能的思路,一般用来保存常用的数据,容量较小,但访问更快。缓存是相对主存而言的,主存的容量更大,但访问更慢。缓存的基本假设是:数据会被多次访问,一般访问数据时都先从缓存中找,缓存中没有再从主存中找,找到后再放入缓存,这样下次如果再找相同数据访问就快了。
缓存用于计算机技术的各个领域,比如CPU里有缓存,有一级缓存、二级缓存、三级缓存等,一级缓存非常小、非常贵、也非常快,三级缓存则大一些、便宜一些、也慢一些, CPU缓存是相对于内存而言的,它们都比内存快。内存里也有缓存,内存的缓存一般是相对于硬盘数据而言的。硬盘也可能是缓存,缓存网络上其他机器的数据,比如浏览器访问网页时,会把一些网页缓存到本地硬盘。
LinkedHashMap可以用于缓存,比如缓存用户基本信息,键是用户Id,值是用户信息,所有用户的信息可能保存在数据库中,部分活跃用户的信息可能保存在缓存中。
一般而言,缓存容量有限,不能无限存储所有数据,如果缓存满了,当需要存储新数据时,就需要一定的策略将一些老的数据清理出去,这个策略一般称为替换算法。LRU是一种流行的替换算法,它的全称是Least Recently Used,即最近最少使用。它的思路是,最近刚被使用的很快再次被用的可能性最高,而最久没被访问的很快再次被用的可能性最低,所以被优先清理。
使用LinkedHashMap,可以非常容易地实现LRU缓存,默认情况下,LinkedHashMap没有对容量做限制,但它可以容易地做到,它有一个protected方法,如下所示:
1 | protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { |
在添加元素到LinkedHashMap后,LinkedHashMap会调用这个方法,传递的参数是最久没被访问的键值对,如果这个方法返回true,则这个最久的键值对就会被删除。Linked-HashMap的实现总是返回false,所有容量没有限制,但子类可以重写该方法,在满足一定条件的情况,返回true。
代码清单10-4就是一个简单的LRU缓存的实现,它有一个容量限制,这个限制在构造方法中传递。
1 | public class LRUCache<K, V> extends LinkedHashMap<K, V> { |
这个缓存可以这么用:
1 | LRUCache<String, Object> cache = new LRUCache<>(3); |
限定缓存容量为3,先后添加了4个键值对,最久没被访问的键是”b”,会被删除,所以输出为:
1 | {c=call, a=abstract, d=call} |
10.6.2 实现原理
理解了LinkedHashMap的用法,下面我们来看其实现代码(基于Java
7)。先来看内部组成,再看一些主要方法的实现。LinkedHashMap是HashMap的子类,内部增加了如下实例变量:
1 | private transient Entry<K, V> header; |
accessOrder表示是按访问顺序还是插入顺序。header表示双向链表的头,它的类型Entry是一个内部类,这个类是HashMap.Entry的子类,增加了两个变量before和after,指向链表中的前驱和后继,Entry的完整定义如代码清单10-5所示。
1 | private static class Entry<K, V> extends HashMap.Entry<K, V> { |
recordAccess和recordRemoval是HashMap.Entry中定义的方法,在HashMap中,这两个方法的实现为空,它们就是被设计用来被子类重写的。在put被调用且键存在时,HashMap会调用Entry的recordAccess方法;在键被删除时,HashMap会调用Entry的recordRemoval方法。
LinkedHashMap.Entry重写了这两个方法。在recordAccess方法中,如果是按访问顺序的,则将该节点移到链表的末尾;在recordRemoval方法中,将该节点从链表中移除。
了解了内部组成,我们来看操作方法,先看构造方法。
在HashMap的构造方法中,会调用init方法,init方法在HashMap的实现中为空,也是被设计用来被重写的。LinkedHashMap重写了该方法,用于初始化链表的头节点,代码如下:
1 | void init() { |
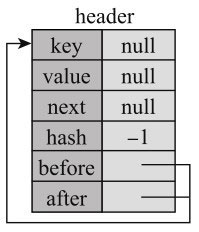
header被初始化为一个Entry对象,前驱和后继都指向自己,如图10-12所示。
header.after指向第一个节点,header.before指向最后一个节点,指向header表示链表为空。
在LinkedHashMap中,put方法还会将节点加入到链表中来,如果是按访问有序的,还会调整节点到末尾,并根据情况删除最久没被访问的节点。
HashMap的put实现中,如果是新的键,会调用addEntry方法添加节点,LinkedHash-Map重写了该方法,代码为:
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
它先调用父类的addEntry方法,父类的addEntry会调用createEntry创建节点,Linked-HashMap重写了createEntry,代码为:
1 | void createEntry(int hash, K key, V value, int bucketIndex) { |
新建节点,加入哈希表中,同时加入链表中,加到链表末尾的代码是:
1 | e.addBefore(header) |
比如,执行如下代码:
1 | Map<String, Integer> countMap = new |
执行后,内存结构如图10-13所示。
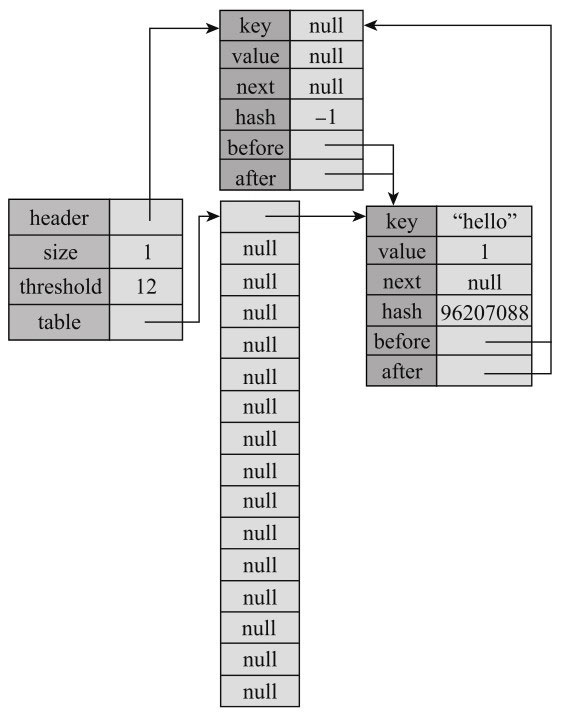
添加完后,调用removeEldestEntry检查是否应该删除老节点,如果返回值为true,则调用removeEntryForKey进行删除,remove-EntryForKey是HashMap中定义的方法,删除节点时会调用HashMap.Entry的record-Removal方法,该方法被LinkedHashMap.Entry重写了,会将节点从链表中删除。
在HashMap的put实现中,如果键已经存在了,则会调用节点的recordAccess方法。LinkedHashMap.Entry重写了该方法,如果是按访问有序,则调整该节点到链表末尾。
LinkedHashMap重写了get方法,代码为:
1 | public V get(Object key) { |
与HashMap的get方法的区别,主要是调用了节点的recordAccess方法,如果是按访问有序,recordAccess调整该节点到链表末尾。
查看HashMap中是否包含某个值需要进行遍历,由于LinkedHashMap维护了单独的链表,它可以使用链表进行更为高效的遍历,具体代码比较简单,我们就不列举了。
以上就是LinkedHashMap的基本实现原理,它是HashMap的子类,它的节点类LinkedHashMap.Entry是HashMap.Entry的子类,LinkedHashMap内部维护了一个单独的双向链表,每个节点即位于哈希表中,也位于双向链表中,在链表中的顺序默认是插入顺序,也可以配置为访问顺序,LinkedHashMap及其节点类LinkedHashMap.Entry重写了若干方法以维护这种关系。
10.6.3 LinkedHashSet
之前介绍的Map接口的实现类都有一个对应的Set接口的实现类,比如HashMap有HashSet, TreeMap有TreeSet, LinkedHashMap也不例外,它也有一个对应的Set接口的实现类LinkedHashSet。LinkedHashSet是HashSet的子类,它内部的Map的实现类是LinkedHashMap,所以它也可以保持插入顺序,比如:
1 | Set<String> set = new LinkedHashSet<>(); |
输出为:
1 | [b, c, a] |
LinkedHashSet的实现比较简单,我们就不再介绍了。
10.6.4 小结
本节主要介绍了LinkedHashMap的用法和实现原理,用法上,它可以保持插入顺序或访问顺序。插入顺序经常用于处理键值对的数据,并保持其输入顺序,也经常用于键已经排好序的场景,相比TreeMap效率更高;访问顺序经常用于实现LRU缓存。实现原理上,它是HashMap的子类,但内部有一个双向链表以维护节点的顺序。最后,我们简单介绍了LinkedHashSet,它是HashSet的子类,但内部使用LinkedHashMap。