8.5.3 基于栈的解释器执行过程
8.5.3 基于栈的解释器执行过程
关于栈架构执行引擎的必要前置知识已经全部讲解完毕了,本节笔者准备了一段Java代码,以便向读者实际展示在虚拟机里字节码是如何执行的。前面笔者曾经举过一个计算“1+1”的例子,那种小学一年级的算数题目显然太过简单了,给聪明的读者练习的题目起码……嗯,笔者准备的是四则运算加减乘除法,大概能达到三年级左右的数学水平,请看代码清单8-17。
1 | public int calc() { |
这段代码从Java语言的角度没有任何谈论的必要,直接使用javap命令看看它的字节码指令,如代码清单8-18所示。
1 | public int calc(); |
javap提示这段代码需要深度为2的操作数栈和4个变量槽的局部变量空间,笔者就根据这些信息画了图8-5至图8-11共7张图片,来描述代码清单8-13执行过程中的代码、操作数栈和局部变量表的变化情况。
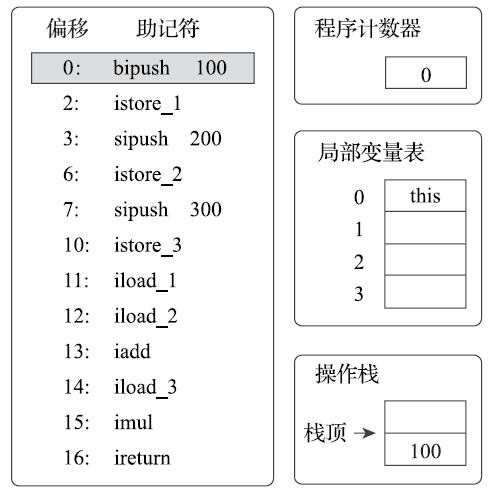
首先,执行偏移地址为0的指令,Bipush指令的作用是将单字节的整型常量值(-128~127)推入操作数栈顶,跟随有一个参数,指明推送的常量值,这里是100。
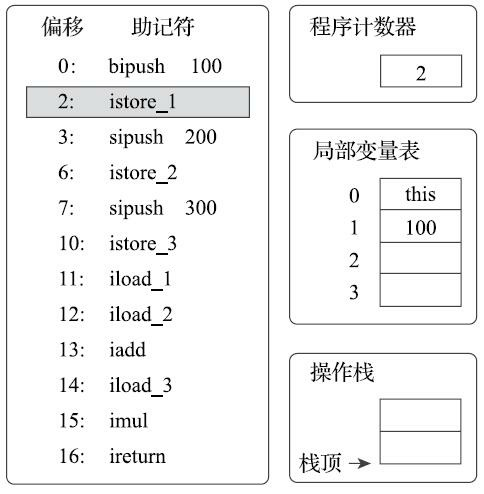
执行偏移地址为2的指令,istore_1指令的作用是将操作数栈顶的整型值出栈并存放到第1个局部变量槽中。后续4条指令(直到偏移为11的指令为止)都是做一样的事情,也就是在对应代码中把变量a、b、c赋值为100、200、300。这4条指令的图示略过。
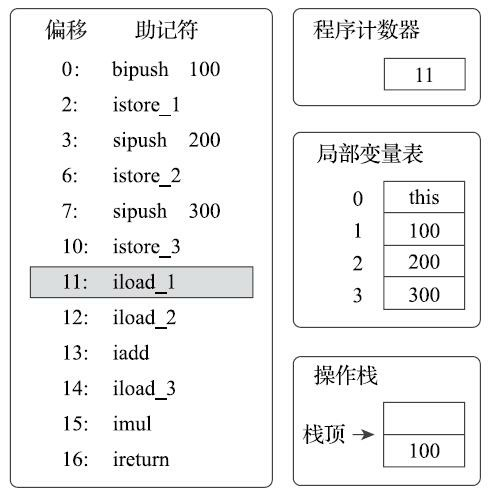
执行偏移地址为11的指令,iload_1指令的作用是将局部变量表第1个变量槽中的整型值复制到操作数栈顶。
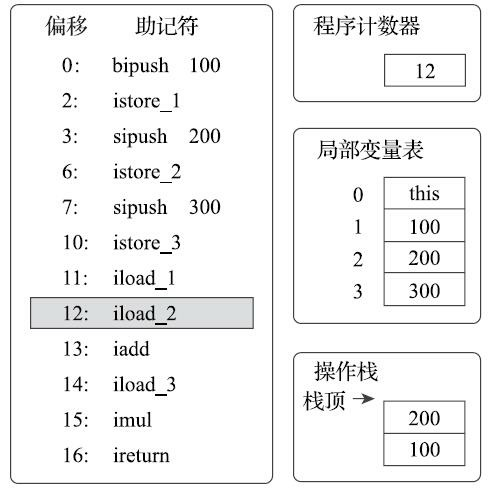
执行偏移地址为12的指令,iload_2指令的执行过程与iload_1类似,把第2个变量槽的整型值入栈。 画出这个指令的图示主要是为了显示下一条iadd指令执行前的堆栈状况。
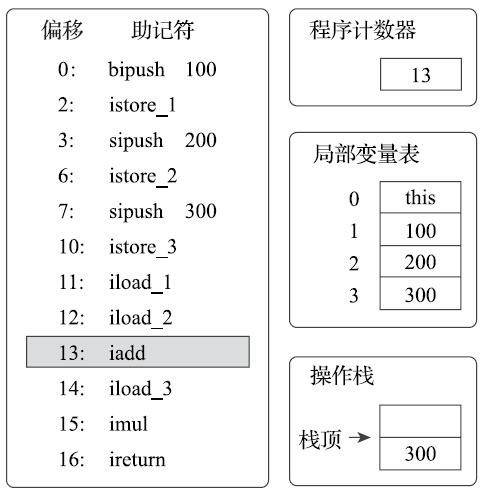
执行偏移地址为13的指令,iadd指令的作用是将操作数栈中头两个栈顶元素出栈,做整型加法, 然后把结果重新入栈。在iadd指令执行完毕后,栈中原有的100和200被出栈,它们的和300被重新入栈。
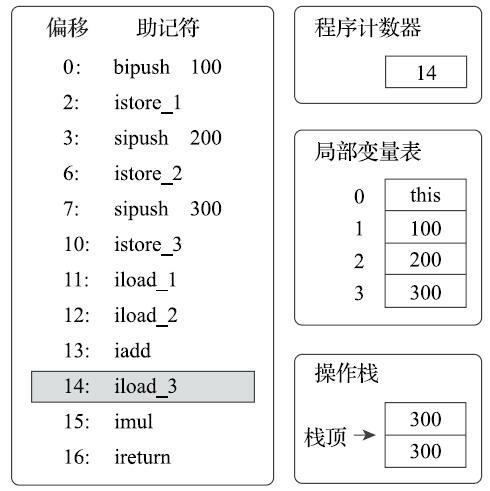
执行偏移地址为14的指令,iload_3指令把存放在第3个局部变量槽中的300入栈到操作数栈中。这时操作数栈为两个整数300。下一条指令imul是将操作数栈中头两个栈顶元素出栈,做整型乘法,然后把结果重新入栈,与iadd完全类似,所以笔者省略图示。
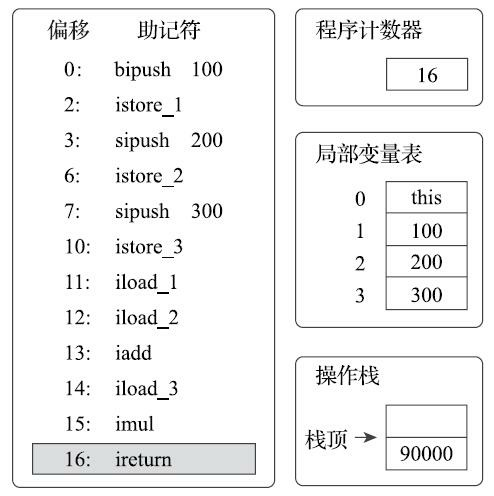
执行偏移地址为16的指令,ireturn指令是方法返回指令之一,它将结束方法执行并将操作数栈顶的整型值返回给该方法的调用者。到此为止,这段方法执行结束。
再次强调上面的执行过程仅仅是一种概念模型,虚拟机最终会对执行过程做出一系列优化来提高性能,实际的运作过程并不会完全符合概念模型的描述。更确切地说,实际情况会和上面描述的概念模型差距非常大,差距产生的根本原因是虚拟机中解析器和即时编译器都会对输入的字节码进行优化,即使解释器中也不是按照字节码指令去逐条执行的。例如在HotSpot虚拟机中,就有很多以“fast_”开头的非标准字节码指令用于合并、替换输入的字节码以提升解释执行性能,即时编译器的优化手段则更是花样繁多^1。
不过我们从这段程序的执行中也可以看出栈结构指令集的一般运行过程,整个运算过程的中间变量都以操作数栈的出栈、入栈为信息交换途径,符合我们在前面分析的特点。